关于执行计划的解读,聚集索引,in的方式查询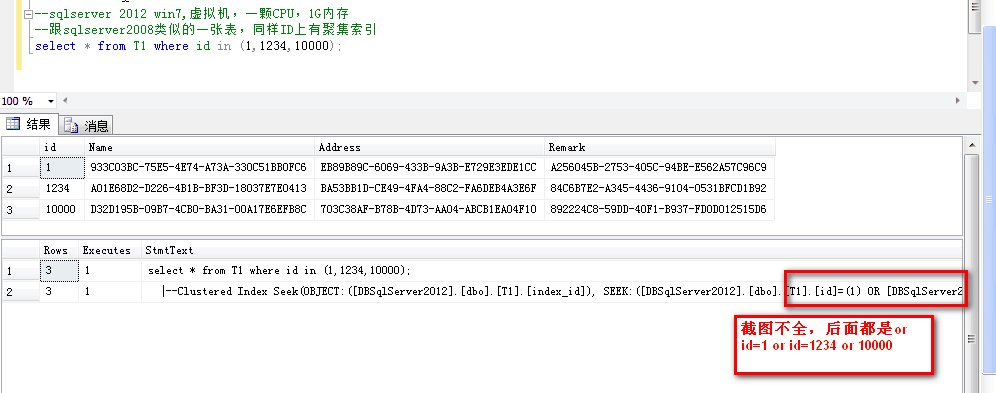
.
[解决办法]
我首先看了IO,比如三个ID,
一个一个查,逻辑IO是3(3次就是9了),
放到in 里面一次性查询出来,逻辑IO是9
从这一点上说,IO是一样的,不存在in的方式用不到索引的问题
比一个一个查询,最起码节省了数据库连接的开销
首先可以肯定地说你这个查询使用in是会利用大索引的。
当然也有使用in的时候不会index seek的时候
而逻辑读取是指从缓存读取的页数,这个跟你的行大小有关系。而不是跟你的返回行数有这么明确的关系。
至于执行计划,你需要注意几个地方:
第一,每个节点返回的行数
第二,每个节点预估行数
这两点的结果对比可以判断你的执行计划是否是最优的。如果两者结果相差不大,说明SQL优化器选择的执行计划是合理的,如果有很大误差说明这个执行计划不是最优的。这个时候可能就要考虑对应的索引的问题了。可能是索引不合理,也或者是统计信息不够准确或者没来得及更新。
[解决办法]
用in 不一定会用不到索引,只是可能会用不到。通过你的这个执行计划看,你的这个查询,就用到了索引,但是是否是最优的执行计划,就还需要进一步验证。
[解决办法]
In的本质是or,如果大量的ID,比如上千个,可能会导致执行计划无法生成。这个我试过,2008和2012的算法的确有不同,我看过基本上的例子,然后在本机上测试的确证明了这点。
[解决办法]
其实,从你贴出来的2008和2012的执行计划,能看出,同一个表,同一个聚集索引,同一个语句,所生成的执行计划却有不同:
2008的显然是采用了:
1、常量扫描-》计算标量,其实就是数据类型转化之类的 -》串联-》排序-》合并interval,这个估计有可能是去除重复
2、nested loop循环,把上面的结果,再 聚集索引中,进行index seek
而2012的,看上去非常简单,只是index seek id 加上or,也就是进行了3次index seek
说明,两者生成的执行计划,还是不同的。