linux�����������֮�����Ķ�������(5)
ԭ����Ʒ������ת�أ�ת��ʱ������Գ�������ʽ��������ԭʼ���� ��������Ϣ�ͱ�������������������
2.5 ���̵Ĺ�����ʽ
�û�Ҳ�ã�Ȩ��Ҳ�գ���������Ҫ��һ��֤���Լ�����أ��ļ�Ҳ�գ�����Ҳ�ã��������ǵ���һ�����������ļ�������Linux�Լ�Ҳ��������Լ�������֮�����Ǿ��Ǵ��̡���ʵLinux�Դ��̵Ĺ���ʮ�ֶԵ��������֣�����������
2.5.1Linux���ļ�ϵͳֻҪ�Ǵ��̾͵�格ʽ���������Ѿ����쾭����������ˣ�����û����ȥ��Ϊʲô���ܶ��о��������似�����и������ľ��������Ƿ����Ĵ��������������һ��װ�����塰A��Ƭ���ƶ�Ӳ�̣���ˬ����������һЩ���Ժ�����Ʒζ������������ôһЩ�����ȽϺõ�Ƭ�ӣ��ߴ糬��4G������ʧ�ܡ���ԭ�������������dz�Ц������ʲô������㻹��FAT32���Ͻ���NTFS�ɡ����������ʱ����Ͳ��ò���һ�£�ΪʲôFAT32���ж�NTFSȴ���аɣ�
��Ϊ�����Dz�ͬ���ļ�ϵͳ�����ܲ�ͬ��������ͬ��FAT32����Windows95ʱ����ʼ���õ��ļ�ϵͳ�������ڶ��������ã�����U�̣�������˵�ǰ��������dzɳ����ļ�ϵͳ��FAT��File Allocation Table����д�������������Ͼ��ܿ�������һ����似��格һ�����ļ�ϵͳ�����������������ļ���С��������һ��32λ��值���������ܹ�֧�ֵĵ����ļ�����ܳ���4G����NTFS����ר��ΪNTϵͳ��Ƶģ������ļ������Դﵽ2T��������Ϊ���õ�Windows XP��Windows 7��֧��NTFS������NTFS����ô�����ļ����е㲻̫��˵����Ϊ��һֱ�����Ǹ������ܡ���
LinuxҲ���Լ����ļ�ϵͳ格ʽ������ΪExtN��N=2��3��4�������Ҫ��ExtN����Դ����ʵҪ��FAT32��NTFS��Ҫ���ϣ�Ҳ��������ǰ����˵�Ļ���inode���ļ�ϵͳ����ǰ��������ExtN�ļ�ϵͳ�ض�Ҫ����inode���ݽṹ������һ���ļ������Ҵ洢����ļ��ĸ������Ժ�Ȩ�ޡ�����ʵ�ʵ����������data block�����С�����֮�⣬ExtN�ļ�ϵͳ����һ������������superblock�������ڼ�¼�����ļ�ϵͳ��������Ϣ������inode��data block��������ʹ������ʣ������
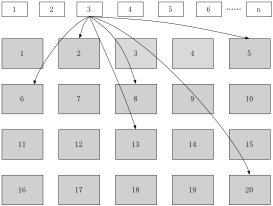
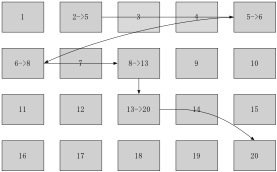
data block��inodeһ����ÿһ������һ��Ψһ��ţ�inodeֻ��Ҫ��¼��Щ��ţ����ܹ���λ�����ļ�������һ�����ݡ����Ǽٶ���һ�����Ϊ3��inode�������������ļ������ݱ������ڱ��Ϊ2��5��6��8��13��20���⼸��data block�С���ô��ȡ����ļ��Ĺ�������ͼ2.4��ʾ�������������ݴ�ȡ�ķ������ļ�ϵͳ����֮Ϊ������ʽ�ļ�ϵͳ������������źܶ��˳ɳ���FAT32��ʲô��ͬ�أ�ͼ2.5�Ա���������̡�
ͨ��������ͼ�ıȽϣ����ǿ��������Ŀ�����ExtNͨ��inode�ܹ�һ���Ի���ļ���������ŵ�λ�ã����Ծݴ������Ŵ��̵��Ķ�˳������֤�ڴ���ֻ��תһȦ������½��������ݶ���������FAT32��ֻ�н���Ӧ��data block����֮���֪����һ��data block��ʲô�ط������һ���ļ���data block�ȽϷ�ɢ�Ļ��������ѱ�֤�ڴ���ֻ��תһȦ������¶�ȡȫ�����ݣ���ʱ������Ҫ��ת�ܶ�Ȧ���ܶ������ݡ�
��������Ƿdz���Ϥ�ġ�������Ƭ�����⡣���ڳ�ʱ��Ķ��ļ����д�����ɾ������д�����ѱ�֤ͬһ���ļ���data block��λ�����ڡ�������FAT32�Ķ�д���ԣ���data block�����ڵ�����¶�д���ܻἫ���½�������Ϊ�����Windowsϵͳ�Ĵ������ܣ������Ե�����������Ƭ�������Ƿdz��б�Ҫ�ġ�
������Linux�����ļ�ϵͳ��������ϲ���Ҫ���д�����Ƭ������������Ҳ�������Ҳ�����似�Ĺ��ߡ�����Linuxϵͳ������ʱ��ʹ��֮���ǻ����ļ����ݹ��ڷ�ɢ������ġ������ܹ������ܺõĹ滮�����Ƕ����ܶ�����Ի��ǻ���һЩӰ�죬ֻ��û��ʹ��FAT32��Windows��ô���ذ��ˡ����ԣ�һ��ʹ��ʱ��ܾõ�LinuxϵͳҲ����Ϊ������Ƭ�������������Ҳ����ʵ��ֻ�Dz���Ҫ̫����������
ͼ2.4 ExtN�ļ�ϵͳ��ȡ���ݹ���ʾ��ͼ
ͼ2.5 FAT32�ļ�ϵͳ��ȡ���ݹ���ʾ��ͼ
2.5.2 ���̵Ļ���������ǰ���С���н��ܹ�������õ��ļ��������ls��cd��cp��rm��mv����Ȼ����Ҳ���������ڴ����ϣ�������������Ķ����Ϊ��һЩ�������ļ�����ġ�����������Ҫ���ܵ������ͼ�һ�㣬����ǵ��ļ������塪�����̵�һЩ������������õ��ǣ�df��du��dd��fsck��mount��
df�������ڲ鿴ϵͳ�����д��̵�����ʹ�����������ǵIJ���ϵͳ���ܹ��õ�������ʾ��Ϣ��
Filesystem 1K-blocks Used Available Use% Mountedon
/dev/mapper/VolGroup-lv_root
51606140 5587240 43397460 12% /
tmpfs 250860 272 250588 1% /dev/shm
/dev/sda1 495844 31891 438353 7% /boot
/dev/mapper/VolGroup-lv_home
9877432 1681704 7693968 18% /home
�ɼ�df�����������DZȽ������ġ��������������������Ҫ����һ�£�����������˵�ġ�Filesystem���͡�Mounted on�������Ҫ��������ģ��ܶ��˵Ļ����п�����ʾ���ֶ��������ǡ��ļ�ϵͳ���͡����ص㡱��
������˵�ġ��ļ�ϵͳ��������֮ǰ��˵�IJ���ϵͳ�е��ļ�ϵͳ�ĸ����е㲻����ͬ�����������ĺ���ָ���Ǵ��̷�����֮���Խ������ļ�ϵͳ������Ϊÿһ�����̷�������һ���ļ�ϵͳ�ľ���ʵ�������������������˵�����ǣ���Ͷ�������ExtN�����ľ����࣬������Ĵ��̷������������Ķ������ڡ����ص㡱��Ƚ���Ȥ������ij�������Ŀ¼��
��dfÿһ���е�����Ͽ����ѵ�����Ĵ��̷�������ij�������Ŀ¼�йأ���ʵ��ȷ�������ġ�ǰ��Ҳ��˵����Linuxû��Windows�е�C�̡�D�̵ĸ����ͨWindows��ͬѧ�������Windows�еķ�������һ���̷�������Ӧ���ڷ����е��ļ���Ŀ¼����֯�ṹ����һ����һ�������������̷�+��������Linux��֯�ļ���Ŀ¼�ķ�ʽ����Ҳ�ܱ�������һ��������������û��C�̡�D�̵ĸ����û���̷�һ˵�����Ǿ�����涨��һ���ܵ������С�/����������ij�������������ʹ�ij��Ŀ¼��ʼ�����ڲ�ͬ�ķ���Ӧ�ô��ĸ�Ŀ¼��ʼ�����û����ȷ�Ĺ涨����ʵ���涨Ҳ�����й涨�������������ָ�ɡ�������ָ���ĸ��������ĸ�Ŀ¼��Ӧ������mount������ָ���ˡ�֮��ֻҪ�����ĸ�Ŀ¼����κ��ļ���Ŀ¼�����ǶԾ���ķ������з����ˡ������Ŀ¼��Ϊ�����ص㡱��
����df�����������ݿ��Կ�����Linux�ļ��е���������/���롰������/dev/mapper/VolGroup-lv_root���������/dev/shmĿ¼�롰������tmpfs�������/bootĿ¼�����/dev/sda1���������������Щ������������ʲô�����أ���ʵ����Щ��ν�ķ����У�ֻ��/dev/sda1���������Ĵ��̷������������������������̷����ġ��豸��������Linuxϵͳ�У�/devĿ¼�µ������ļ�����һ��������豸�йأ��������ģ�Ҳ������ġ���sda1�������һ���������豸������Ӧϵͳ��һ�鴮��Ӳ�̵ĵ�һ����������ô����ǵڶ��������أ�sda2����������sda3����������Ӧ����Ӳ�̵�����sda���ɴ˵��ƣ��ڶ��鴮��Ӳ�̣�Ӧ����sdb��������Ӧ����sdc��������/dev/mapper/*��Щ����ʲô�أ��������������豸�ˣ���ʵ�������������й������ĸ��������Ժ���˵��������ֻҪ֪����������Ĵ��̷��������ˡ���������ֵ���tmpfs������豸�ļ���ʲô�ط��أ�����û�У���Ϊ������Ӧ�κ��豸����ʵ�������������ļ�ϵͳ���ơ�������ļ�ϵͳ�����ڴ�������ģ�������Ӳ���أ�����Ҳû�о�����豸��������df����������Ҿ��롰�����������ˡ��������ļ�ϵͳ���кܶ࣬����procfs��sysfs�ȣ��������ר�ŵ�һ����������Щ�����ļ�ϵͳ��
df�������û��ʲô�ü����ٽ��ܵ��ˣ�������һЩ����Զ��df����Ҫ��Ҫ�ܶ࣬����Ǵ��Ӧ�ø���ע��ġ�����/devĿ¼�µ���Щ�ļ������鲻�������ȥ�������Ƕ�����˭���Ͼ�ÿ���˵�ϵͳ����ͬ������Ҳû��˵����û��������ô�����أ��ȽϺð�İ취���ʰٶȻ�ȸ裬��������ѧϰLinux�ز����ٵĹ��ߡ����ˣ��Ҳ�����˵���ˣ���Ϊ�������Ƕ�����ҵ������ٶ�ȥ�ˡ�
df�����������۲��������ʹ�����ģ�Ҫ�۲�ֲ�ʹ��������Ҫʹ��du���df�������ͨ����ȡ���̵�superblock��ʵ�֣���du������ͬ����Ҫ�������е�inode������ֲ����ݣ�����du�����ִ��Ч�ʣ�����Ҫ��df��ܶࡣ
����格������������dd����Ӧ�ò����ڹ������̵������Ϊ������������˵���Ĺ����ǡ�convert and copy a file���������������Ҫֱ�Ӷ�д���̵�ÿһ�����������߾����������̣�dd�������Ƿdz��õ�ѡ��ͨ��dd�����格ʽ���£�
dd if=input_file of=out_file
����������÷������������������˵�����ģ�����һ���ļ�������ʹ����似���������
# dd if=/etc/bashrc of=./bashrc
���������cp /etc/bashrc ./bashrc�ǵȼ۵ġ���ʵ��if���͡�of������������Ҳ���ø���������Ĭ��值����if����Ĭ��值�DZ����룬��of����Ĭ��值�DZ���������Ҫģ��cat�������ʹ�����������
# dd if=/etc/bashrc
����ǰ��Ľ��������ݣ������Ӳ���豸��/devĿ¼�»��ɾ�����ļ���֮��Ӧ������/dev/sda1�����Ҫ������һ�����ڴ��̵�һ�������ľ����ļ�������ʹ�����������
# dd if=/dev/sda1 of=./sda1.img
��Ҫע�⣬ִ�����������ʱ������ļ����ڵķ����������sda1����������Ϊʲô�����㶮�ġ������ϣ�������ɵľ����ļ�ѹ��һ�£�����ʹ�����������
# dd if=/dev/sda1 | gzip -9 > ./sda1.img
�������˼·�����ǽ��������̶���һ�������أ�
# dd if=/dev/sda | gzip -9 > ./sda.img
���Ҫ�ָ�������̵����ݣ��Ϳ���������# gzip -dc ./sda.img | ddof=/dev/sda
ͨ���������������뵽��ʲô������Dz�����������Windows�¾���ʹ��ghost�dz����أ��о��������˹�˾���ϴ�Ӧ���ҿ鶹��ײ������dd�����ֹ��㱾�£�������ָ����д������������bs��count�������������ܹ�ָ�����ζ�д���Լ����Ͷ�д�������������ܹ�ָ����д�����ˡ�������Ҫ���ݴ��̵���������¼������������
# dd if=/dev/sda of=./mbr.img bs=512 count=1
��Ҫ��值��ȡsda���̵���512���ֽڵ���Ϣ��Ҳ���ǵ�һ�����������ݣ��������浽mbr.img�ļ�����mbr���ݸ���Ȥ��ͬѧ������ʹ�÷����ߣ�������ļ�������������֪�����������ô�������ˡ�
ʹ��dd�����ܹ��������黹�кܶ࣬�������ٴ������ݡ����Դ��̶�д�ٶȡ������̵ȣ�Ϊ�˷�����ʹ�ã��ҽ���Щ������������
# dd if=/dev/urandom of=/dev/sda1
# dd if=/dev/zero of=./test.file bs=1024count=1000000
# dd if=./test.file bs=8k | dd of=/dev/null
# dd if=/dev/sda of=/dev/sda
������Щ���Ҿ������Ǹ�����Ϊ�������˹�˾���ϴ�Ӧ����鶹��ײ�����ر�˵��һ��/dev/urandom��/dev/zero��/dev/null�����������豸�豸�ļ��dz����á�urandom�����漴����ÿ�ζ�������ݶ�������ͬ��zero����0��ÿ�ζ�������ݶ���0����null��Ҫ���д���൱����һ���ڶ�һ��������дʲô������ʧ����Ӱ���١�
��֪��ͨ��������Ľ��ܣ�����Ƿ��Ѿ�����dd�ڴ��̹����е��������أ���Ȼ����������ϣ�����������Ҳ�ܲ����ˡ�����ü��������ǵ����ݽ��������ߣ���˵һ��fsck�ˡ�
fsckһ�����Ǻ����ֹ�ִ�У������϶�����ϵͳ�����ξ�ִ���ˡ���������ʲô������dz�����Windows��scandiskһ�������ļ�ϵͳ������������Ҫע�⣬fsckֻ�ܶ��ļ�ϵͳ�����������Դ��̵�������û�а취�ġ��������ǻ��е������½�������fsck�Ĺ���ԭ��������Ͳ��������������ʹ�÷������ǣ�
# fsck -t �ļ�ϵͳ�豸��
���磺
# fsck -f -t ext3 /dev/hda3
���в�����-f��Ҫ�����ǿ�Ƽ�顣���������-fѡ���û�б����Ĵ������Dz��������ġ����ڴ���ʲôʱ��ᱨ���أ�һ����ǷǷ��ػ���ʱ����!
�ڴ��Ѿõ�mount�����ڵdz��ˡ�ǰ���Ѿ��������ҽӵ㡱�Ǹ�ʲô�����ˣ����Ŵ�һ���ΪLinux���֡����족����ƶ����������ء����������ù�Linux���ҷ�������Windows����Ʒdz���֡����֮�£�Linux�ķ�ʽ��Ϊ���ͱ�����Windows����һ������������D���µ�ij��Ŀ¼�ж�ȡ�ļ������������������һ��û��D�̵�ϵͳ�о���ִ���ˣ��෴�ģ���Linux�£�ֻ��Ҫ���ⴴ��һ��Ŀ¼���ɣ������Ҫ�����Ĵ��̷������洢����ʹ��mount����ָ�������ͺ��ˡ�
��˵mount�����������е����棬����ʹ������ȴ�Ƿdz���һ����÷��������ģ�
# mount [-t �ļ�ϵͳ] �豸���ƹҽӵ�
��������Ҫ��ϵͳ�еڶ��鴮��Ӳ�̵ĵ�һ������������еĻ����ҽӵ�/dataĿ¼�£����������ã�
# mount /dev/sdb1 /data
��
# mount -t vfat /dev/sdb1 /data
��ô�������İɣ����ڵڶ����÷��ܶ�ʱ��-t�������Ƕ���ģ���Ϊ��似ext2��ext3������ExtN��Ļ���inode���ļ�ϵͳ�����Ƕ��г�����ġ����ó�������ܹ��˽������ļ�ϵͳ�����Ե�һ���÷��ڴ����ʱ��ɹ������ڶ����÷��������ڹҽ�Windows����ʱʹ�ã���Ϊ��Щ�ļ��ļ�ϵͳ���߱������졣
��ʵ�ҽӴ��̷�����ֻ��mount�������ƽ����һ���÷�������Linuxʹ���豸�ļ�������һ���豸����ô�����һ��ʵ�ʵ��ļ��е���������ij�������豸�ļ��еĶ���������һ�£���ô���ʵ�ʵ��ļ�Ҳ�ܹ��ҽӽ������ͱ�������֮ǰʹ��dd�������sda1.img�ļ���δѹ���ģ����Ϳ��������������������ҽ���һ��Ŀ¼�ϣ�
# mount -o loop ./sda1.img /mnt/sda1
������ͻᷢ��/mnt/sda1Ŀ¼�µ�������/bootĿ¼�µ�������ͬ��������֮ǰdf�������������Դ����ƣ��������ص���*.iso�ļ�Ҳ����ʹ��ͬ���ķ����ҽӵ�ij��Ŀ¼��ֱ�ӷ����ˡ����磺
# mount -o loop ./CentOS-6.4-x86_64-bin-DVD1.iso/mnt/centos
���������Dz��Ǿ���Windows����Щ������������������Ƕ�����鶹��ײ���ˣ�
������mount���÷��У��Ƚ���Ҫ���ǡ�-o������ѡ����Ǹ�mount�Ƚ�����һ��ѡ��кܶ��ѡ���������硰ro��˵���ҽӵĴ�����ֻ���ġ���rw��˵���ҽӵĴ����ǿɶ�д�ĵȵȡ���loop��˵��Ҫ�ҽӵ��ļ���һ�������豸������������豸�ǻ��ε��豸��Ϊʲô�ǡ����Ρ��أ�����Ӳ�̡����̡����̵ȶ���ʲô��״�����ˡ�����֪����Բ�εİ���
��mount�෴�IJ�������ж���ˣ�ʹ��umount������IJ������Ӽ������ҽӵ�Ŀ¼������豸�����ˡ����磺
# umount /data
��
#umount /dev/sdb1
������ϵͳ������Щ�豸���������ַ����ǵȼ۵ġ�
������йؽ��д��̷�����格ʽ��������Ͳ�����ϸ�����ˡ���Ϊ�ܶ�����Windows�������Ĺ�����ô�ö����㲻������ɼ����Ƕ��Ǻ����õ��Ķ�����Ϊ������һ��ͬѧ�ĺ����ģ�����������ֻ˵һ�����ǵ����֡�
���ڴ��̷�����������fdisk������Windows��DOS�µ���������һ�µġ���fdisk������һЩ�ķ���������cfdisk��Cent OS�����ṩ�����Դ�����格ʽ��������format�����Linux����mkfs.*�������*��ʲô��ȡ������格ʽ����ʲôϵͳ������Ҫ格ʽ����ext3�ļ�ϵͳ����Ӧ����mkfs.ext3��������˽�ϵͳ�ж�����Щ�ļ�ϵͳ֧�����������ֱ�ӵ�/sbinĿ¼�²鿴�����ˡ�����Ϊͨ�õ�格ʽ����������mkfs���������ʹ�ã��鿴���������ɡ��������֮ǰ���ܵ���Щ���̹���Ҳ��һ���ģ����Զ�ij�������е�һ�������ļ����С���������格ʽ����
2.5.3 /etc/fstab�ļ����ڴ���Ѿ��˽��Linux���̵�һЩ����������ʽ��Ҳ�˽��ˡ��ҽӡ���������������Windows����ô���������Dz��Ǻ������������Linux����֮�����ļ������ܹ��������������������Ǿ���һ��һ���Ĺҽ�����ɵġ������ô��̵ĸ�����������Ҫ�ҽӵ��ĸ�Ŀ¼����/etc/fstab�ļ��������ģ���������ļ���Linuxϵͳ��ʮ����Ҫ���ļ���һ����ʧ��ϵͳ��������������������������ļ���格ʽ�����ֹ��ָ��������dz�ΪLinuxϵͳ����Ա�ı��γ̡�����ļ���/etc/fstab�������ǵIJ���ϵͳ��������ʾ��
#
# /etc/fstab
# Created by anaconda on Sat Mar 17 05:12:212012
#
# Accessible filesystems, by reference, aremaintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8)and/or blkid(8) for more info
#
/dev/mapper/VolGroup-lv_root / ext4 defaults 1 1
UUID=ec11a28b-9bf2-4f7e-95dc-2b7ccd5992ca /boot ext4 defaults 1 2
/dev/mapper/VolGroup-lv_home /home ext4 defaults 1 2
/dev/mapper/VolGroup-lv_swap swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
���ǿ�������ؿ���������ļ�һ����Ϊ6���ֶΣ��ֱ��ǣ�
l�豸�ļ������̾������UUID
l�ҽӵ�
l�ļ�ϵͳ����
lmount�����-oѡ�������defaults������-oѡ��ʱ����Ϊ
l�Ƿ�ʹ��dump����ݣ�0����������1����ÿ�챸��
l�Ƿ�ʹ��fsck��������̣�0��������飬1���������飨һ��ֻ��������/����1����2Ҳ��Ҫ��飬ֻ�DZ�1Ҫ����������֮���һ�㶼ʹ�������
�ڵ�һ���ֶ��У����ǿ�����һЩ��df�����г��ֵġ�������������һЩ��û����������ʵʹ�á�df �Ca���Ϳ��Բ鿴�����ˡ����Ƚ������������/dev/sda1ȷ�����ˣ����������Կ������ǡ�UUID=ec11a28b-2bf2-4f7e-95dc-2b7ccd5992ca������豸��ʹ������blkid�������¶������Ŀ�ˡ�ʵ����������ֱ��д/dev/sda1Ҳ��û������ġ�
��Ȼ/dev/sda1�ҵ����ˣ����ǻ���һ��������df����������ôҲ�Ҳ������Ǿ�������Ϊswap����������������ʲô�أ�����ǽ�������������������ʲô�����أ���Windows��ҳ���ļ�����ͬ�ĸ��
��ν��ҳ�潻���ļ���ʵ���Ͼ��������ڴ����ʱҪʹ�õ��ڴ��û��ļ�������������չ�����ڴ�ռ�ġ���Ȼ��Ҳ������ϵͳ���������֮һ����Ҫע�⣬�����ʹ�õ���32λ��ϵͳ�������Ѿ��䱸��4G���ڴ棬��ô��û�б�Ҫ��Windows����ҳ�潻���ļ�����û�п���PAEģʽ������£���Linux��Ҳ�������Ĺ�أ�ֻ�ǽ�ҳ�潻���ļ���ɽ��������ˡ�
����������������ʹ��fdisk���格ʽ����ʹ��mkswap������似����û���ӳ�����֮ǰ�����յ�һЩ֪ʶ�����ǵ��˾���ҽӵ�ʱ��Ͳ�һ���ˣ������ǹҽӵģ�������ʹ��mount�������õġ�ȡ����֮����ʹ��swapon��������Ҫ�ص�ij��������������ʹ��swapoff���
���⣬��������֮ǰ�ľ��飬��ͨ�ļ�Ҳ���ܹ���Ϊ�������������ģ����ǵ�ǰ�潲�����������)���������Ҿͽ��������ļ����ˡ���������ʹ��dd����������һ���յ��ļ���Ȼ��ʹ��mkswap��������格ʽ�����������紴��һ��1G�Ľ����ļ�������������
# dd if=/dev/zero of=/tmp/swap bs=1Mcount=1024
# mkswap /tmp/swap
���ڽ���������ô���������㶮�ġ�
2.5.4 ������ǰһС��������������һ��Сβ�ͣ�˵/dev/mapper/*��Щ����������������������ʲô��û�м���˵����Ҫ����Ϊ���Сβ����ʵ����С��һ��С�Ŀ��ܼе�β�͡�
1.ʲô������
��ô����ʲô�������أ�������ܵ���Ҫһ���Ƚ�ʵ�ʵij���������һ�£����û���һ����
ǰ��������һ��ͬ�£����Լ��ĵ�����������Windows���а�װ��һ��Ubuntu������ʹ��Linux��ʱ�������Եú�С����ֻ������Ubuntu����10G��Ӳ�̿ռ䣬�����������������ֱ���ˡ�/������/home����swap��������/������2G�Ŀռ䣬��/home��������7G��swapΪ1G�������ķ��䷽�����DZȽ�רҵ�ġ�ֻ��û�����������������鷳�����������Linuxϵͳ������һ��Androidϵͳ�����Ǿ���Ҫ���ص�Android��ȫ��Դ���롣����û�뵽Googleʵ���Ǵ�7G�Ĵ��̿ռ䲻��װAndroid��Դ���롣���ˣ��������ʸ�λͬѧ������������������Ҫ��ô����
��������ǰ�����յ�֪ʶ�����������������ٴ�Ӳ���л���һ������ķ�������������100G��Ȼ���ٽ��������格ʽ����Linux���ļ�ϵͳ������/homeĿ¼�µ�����ȫ�����Ƶ��µķ����������/etc/fstab�ļ������µķ�����Ϊ/home������֮��ʹ���ˡ������������ķdz��ã�Linux���������Ȼ��һ�㡣�����������100G����̫�����أ�Windows�ֲ���������ô�죿�ѵ����ظ��������������ģ������ļ���Ҫ���ܳ��ܳ�ʱ��ģ�����������Դ����Ķ�����������С�ļ���
���ˣ���������������������ģ����ܹ����Եĵ����ļ�ϵͳ����������������˵�����������ڴ��̷������ļ�ϵͳ֮��������һ�����㡣���������ļ�ϵͳ���������ò�����ʱ�������������������µķ�����ʵ������������Ŀ�ģ����������ļ�ϵͳ������д����˷ѵ�ʱ����ѡ��ȥ��һЩ����û��ʹ�õĴ��̷������ﵽ������Ŀ�ġ���Linuxϵͳ��ʵ���������ܵ���LVM,��Logical Volume Manager��������������
2.����������ԭ��
�ڽ�һ����������֮ǰ���������˽�һ�����Ļ������
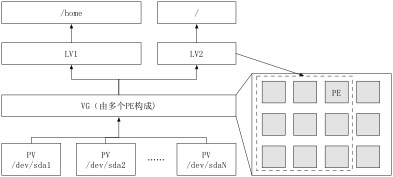
lPhysical Volume��PV��������
���������Ǿ����Ӳ�̷�����������Ӳ�̷���������ͬ���ܵ��豸������raid�ȣ���LVM�Ļ����洢��Ԫ������������������洢���ʣ�������ͨ��Ӳ�̷����ȣ���������Ҫ������LVM��صĹ���������
lVolume Group��VG������
������似�ڷ�LVMϵͳ�е�����Ӳ�̣��ɶ����������ɡ������ھ����ϴ���һ������LVM������
lPhysical Extend��PE��������չ��
ÿһ������������һ�����ֳɱ���Ϊ������չ���Ļ�����Ԫ�����仰˵PE��LVMʹ�õ���С�洢���������������еġ����������ļ�ϵͳ�еġ��ء��ĸ��������ͬ��LVM��Ĭ��PE��С��4M��ÿ�����������ܺ���65534��PE�����ԣ�һ������������������4M*65534=256G������ı�PE�Ĵ�С�����ܹ��ı��������������
lLogical Volume��LV������
�������˵���������ˣ�����������������������ھ���֮���ٽ����з֣��������������ϼ������ַ�����һ���ĵ��������������Ĵ�С������PE���������������LVM�ܹ����Ե��������������������ڡ���Ҫ����������������PE����Ҫ�����������ͼ���PE��LVM�Ĺ���ԭ����ͼ2.6��ʾ��
ͼ2.6 FAT32�ļ�ϵͳ��ȡ���ݹ���ʾ��ͼ
���˾���������ϣ��Ϳ���Ӧ��mkfs�������格ʽ���ˣ�����������ܹ�ʹ��mount����ҽӵ�ϵͳ���ˡ�
����ԭ���������Ǹ㶨�ˣ����Ƕ���һ���������ܻ��Ӧ��������������ϣ���ô����Ӳ����д�����ݵ�ʱ������ô�������أ�Ŀǰ������ģʽ��
l����ģʽ��linear�����������������ʹ�á�����һ������ռ����/dev/sda1��/dev/sda2������������ô����д/dev/sda1��ֱ������֮��Ż�ʹ��/dev/sda2��
l����ģʽ��triped��������ͽ�һ�����ݲ���������֣��ֱ�д��/dev/sda1��/dev/sda2�������RAID 0�������ʹ��/dev/sda1��/dev/sdb1����������������������൱��һ������������Ӳ����д�����������ܹ�������дЧ�ʵġ�
��Ҫע�⣬��Ȼ����ģʽ�������е���RAID��������������Ŀ�Ļ������ڴ��������ĵ��Կɵ��ġ����Ҫ��ע���ܣ�����ֱ��ʹ��RAID�ȽϺá�����tripedģʽ��������RAID 0����似�ģ�����ij�������ҵ��ˣ���ô�������Ҳ����Żҷ�����ġ�����������Ĭ�Ϲ���ģʽ��linear�ġ�
3.��������
Cent OS�Ѿ�Ĭ��֧�������ˣ��������ѡ����Cent OS��ͬѧ�����ھ��Ѿ���ʹ�������ˡ����������ѡ����Ubuntu�����ķ��а棬��û����ô�����ˣ���ΪUbuntu��û���ṩ�ⷽ���֧�֡�����Ҳ��Ҫ�������ǿ����ֶ���װ��
���ȣ������������ں�֧�ֲ��ܹ��������Ա��뱣֤����ʹ�õ��ں��Ѿ������˵�������֧�֣����ڴ�����������а���ں˶�֧�֣�����Σ���Ҫ��װlvm2������������Щ������֮�Ϳɿ�ʼ����Ĺ����ˡ�
��һ�����������̿���ռ䣨PQ�����Ǹ��ù��ߣ���Ӳ�̶��ͬѧ���Կ������õڶ���Ӳ�̡�Ȼ������Щ���õĿ���ռ��л��������������������÷�������ΪLinux LVM��������־��8e������������������һ����20G����Ӳ�̣����ǽ���������4��������ƽ��ÿ������5G��
�ڶ����Ǵ���������������������ص������У�pvcreate��pvscan��pvdisplay��pvremove�ĸ������嶼�ṩ��Щ���ܣ����ͨ�����ƶ����˽�����ǽ��ոջ��ֵ�4�����������ó���������ִ�����������
# pvcreate /dev/hdb1
# pvcreate /dev/hdb2
# pvcreate /dev/hdb3
# pvcreate /dev/hdb4
��
# pvcreate /dev/hdb{1��2��3��4��
��Ȼ��һ�ֵķ�格���Ӽ�㣬�������Ǻ�������в��������������ַ�格��
���������Ǵ�������VG����������������У�vgcreate��vgscan��vgdisplay��vgextend��vgreduce��vgchange��vgremove������һ���¾������ִ����似���������
# vgcreate /dev/hdb{1��2��3} NewVolGroup
����֪���������ɶ�����������ɵģ��������ǽ�/dev/hdb1��/dev/hdb2��/dev/hdb3����һ����ΪNewVolGroup�ľ��飬���µ��Ǹ����ڷ��ں���˵�������̬���ӻ���������á��ھ����ж������ӻ�ɾ����������������vgextend��vgreduce���ڴ��������������һʱ�̣����Ը�vgcreate����ݡ�-s��ѡ��ָ��������չ��PE�Ĵ�С������16M��������ͬѧ��������ýϴ��PE�ᵼ�´��̵��˷ѡ���ʵ��Ȼ��PE����̵���С�洢��Ԫ���������ء���ͬ����ֻ��LVM���ڽ��ж�̬�����ߴ��һ����С���䵥Ԫ�����������洢�ļ���ʱ���ǻ����ô��̱�������С�洢��Ԫ��
���IJ��Ǵ�������LV�����൱�ڶԾ����������̽��з�����������LV�йص������У�lvcreate��lvscan��lvdisplay��lvextend��lvreduce��lvremove��lvresize�����ڷ��㿼�ǣ����ǽ�����VGֻ����Ϊһ��LV��ʹ�����
# lvcreate -l 3842 -n lv_data NewVolGroup
����������С�-l��ѡ��˵�������PE��������-n��ѡ����Ϊ�µ�LV������������3842�����������е�ȫ��PE���������Ǵ������õ��أ�����vgdisplay������С�
������һ���µ������ʹ�������ˡ�ʣ�µ��������格ʽ�����ҽ���������ʹ���������
# mkfs.ext4 /dev/mapper/NewVolGroup-lv_data
# mkdir /mnt/data
# mount /dev/mapper/NewVolGroup-lv_data/mnt/data
֮��Ϳ���ʹ��df������ȷ������µĴ���ʹ������ˡ�
4.��������
ʹ��������Ŀ�ľ��dz��������������ŵģ�������������������ǹؼ����ڡ�����������һ����θ���������������
����֮ǰ����������/dev/hda4��������¡���ʵ��Ӧ���У�����Ҫ���������������������ĽΡ���һ���µ����������뵽һ�����еľ�����ʹ��vgextend��������ǵ�����������������
$ vgextend NewVolGroup /dev/hda4
֮������ʹ��vgdisplay������ܷ������µ�Free PE���֣������ǵIJ��Ի�����1274����������������˾�������������������Ļ�û�иı䡣����Ҫʹ��lvresize��������ӵ�PE���뵽�����С������ǵ�����������������
$ lvresize -l +1274/dev/mapper/NewVolGroup-lv_data
������ʹ��vgdisply����ͷ����Ѿ�û��Free PE�ˡ��������ʱ������ʹ��df����鿴���̿ռ����ʱ����û�з�����ʲô�仯����Ҫ����Ϊ���ǻ���һ�����裬����ִ��resize2fs��������ԭ����ʵ�ܼ����������ӵ���Щ���̿ռ仹û��格ʽ���ء��������ܼ������ǵ�������ֻ��Ҫ������
$ resize2fs /dev/mapper/NewVolGroup-lv_data
���������ǵĴ��������������ˣ���ȫ�����ߵģ��Dz����൱�����أ�
���ˣ�˵������������������������μ�С�����ɡ��������Ҫ��/dev/hda1����������Ǽ�С�������������Ҫ�鷳һЩ�ˣ����������Dz������ߵ��ˡ�
������Ҫȷ��/dev/hda1�����ж����ͨ��pvdisplay�����á������ǵIJ��Ի��еõ��Ľ����5.01G�������ǵ�Ӳ����20G�ģ���ô��Ҫʹ��resize2fs������ǵĴ��̵�����20G-5.01G=14990M�Ĵ�С������ִ�����������
# umount /mnt/data
# e2fsck -f /dev/mapper/NewVolGroup-lv_data
# resize2fs /dev/mapper/NewVolGroup-lv_data14990M
# mount /dev/mapper/NewVolGroup-lv_data/mnt/data
��֮��������ͨ��df����鿴���ܿ������������Ѿ������ˡ����Ǵ�ʱ���ǻ���û�����κ�PE�����ʱ����Ҫʹ��lvresize����������PE�����ն����أ���Ȼ��/dev/hda1�к��е���Щ�ˡ�ͨ��pvdisplay������Բ鵽��1282��������ִ�����
# lvresize -l -1282/dev/mapper/NewVolGroup-lv_data
�������Dz��ǾͿ��Խ�/dev/hda1��������أ������С���Ϊͨ��pvdisplay����֣�/dev/sda1��û�п��е�PE�������е�PE������/dev/sda3��/dev/sda4�ϡ�/dev/sda4����1274��Free PE����/dev/sda3����8��Free PE���ܹ�1280��PE)��Ҫ���/dev/sda1�������ǵ�����ȫ��PEΪFree״̬��������Խ���pvmove������ɡ���������������п���ʹ����似���������
# psmove /dev/hda1:0-1273 /dev/hda4:0-1273
# psmove /dev/hda1:1274-1281/dev/hda3:1272-1279
��֮����ʹ��pvdisplay�鿴���ͷ���/dev/sda1��PE��ΪFree״̬�ˡ���֮��Ϳ���ʹ��vgreduce�����/dev/sda1����ˡ������ǵij����п�ִ����似���������
# vgreduce NewVolGroup /dev/hda1
��Ҫ���Ѵ��һ�£���������������У�����/dev/sda1�����з���������һ����ʹ���������������������뵽�κ����������У�����������ʹ��psmove�����ʱ�������Щ���ӡ������������ȴ����ʵ��Ӧ�õ��о�����������������������Ŀ���������ռ��ԭ�������ʱ��PE��ŷ�Χ�Ϳ���ʡ���ˡ�˳����һ�䣬PE����Ǵ��㿪ʼ�ġ�