Linux内核的malloc实现(Oracle的cache buffer影子)
本文原创为freas_1990,转载请标明出处:http://blog.csdn.net/freas_1990/article/details/12845059
本文介绍一下malloc的原理,对mm感兴趣(或者对Oracle internal实现感兴趣)的同学能在本文找到感兴趣的内容。
malloc主要由两个结构体做支撑。
struct bucket_desc { /* 16 bytes */ void *page; struct bucket_desc *next; void *freeptr; unsigned short refcnt; unsigned short bucket_size;};这个结构体是一个bucket descriptor。所有的object会通过链表链接起来。
struct _bucket_dir {/* 8 bytes */intsize;struct bucket_desc*chain;};这是bucket的目录。
我画了两个图来描述一个page(页面;4k)如何被这两个结构体描述。
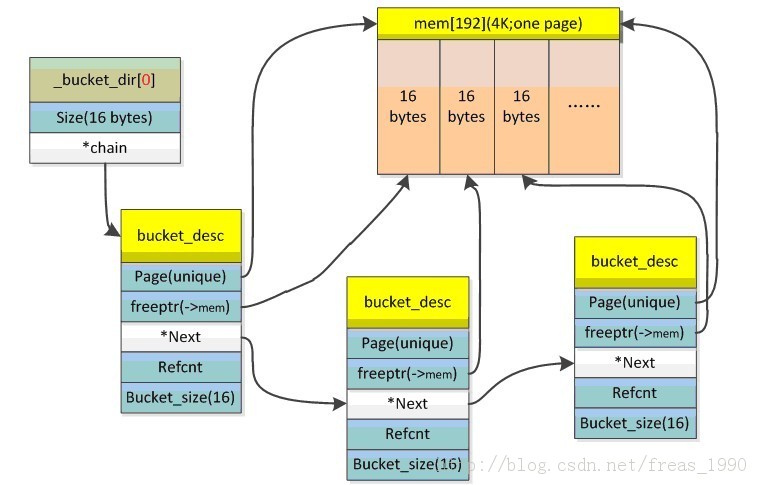
一个4k的页面被分配到若刚个16 bytes大小的bucket中
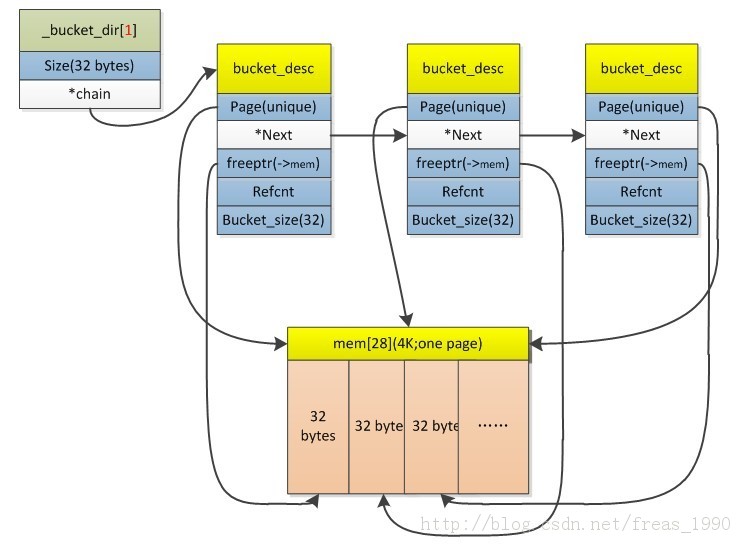
一个4k的页面被分配到若刚个32 bytes大小的bucket中。
那么,这些数据结构是如何被初始化的呢?
首先,在内核代码里,硬编码了如下数据。
struct _bucket_dir bucket_dir[] = {{ 16,(struct bucket_desc *) 0},{ 32,(struct bucket_desc *) 0},{ 64,(struct bucket_desc *) 0},{ 128,(struct bucket_desc *) 0},{ 256,(struct bucket_desc *) 0},{ 512,(struct bucket_desc *) 0},{ 1024,(struct bucket_desc *) 0},{ 2048, (struct bucket_desc *) 0},{ 4096, (struct bucket_desc *) 0},{ 0, (struct bucket_desc *) 0}}; /* End of list marker */定义了粒度从16起的次方增长。
我写了简化的伪代码来描述整个流程。
malloc的伪代码:
procedure:get the bucket_desc with object size(for example 16 bytes)if(search bucket_desc list for free space){return bdesc->freeptr} else {if(init_bucket_desc){return bdesc->freeptr} else {panic("init_bucket_desc error")}}init_bucket_desc:if(page = get_one_page){sepreated the page(4k) with dir->sizelink all the pieces} else {panic("get page error")}end procedure
free的伪代码:
procedure:get the bucket_desc with object size(for example 16 bytes)if(search bucket_desc list for the related bucket_desc){erase bdesc->freeptrbdesc->refcnt--if(bdesc->refcnt == 0){if(whole page NULL){if(!free_page(bdesc->page)){panic("free_page error")}}}} else {panic("input pointer not right")}end procedure
关于数据结构性能的思考:
这里的主要数据结构就是单向链表,查找的时间复杂为O(N),属于暴力查找。
用了10个元素的数组做分拆,当内存使用过大的时候,这个数据结构就不能承载了。
或许采用一个hash或者树形结构能解决问题。
不过,对于20年前的内存来说,完全能应付了:)