linux�����������֮�����Ķ�������(4)
ԭ����Ʒ������ת�أ�ת��ʱ������Գ�������ʽ��������ԭʼ���� ��������Ϣ�ͱ�������������������
2.4 �����ִ������Linux�Ķ��û�˵���ˣ�����Ҫ������һ�����⣬�Ǿ��Ƕ���������⡣��ν��������ͬһʱ���ܹ�ִ�ж���������������ʵ���ڴ����Windows�û��������Ǹ����⣬��Ϊ���Ǿ�����һ�������ҳ��һ����QQ���죬ͬʱ���������֡���ΪWindows�����ڽ���Щ�����Ľ���ͬ��չ������Ļ�ϣ�����Ų��£�Ҳ����ͨ�������ڡ��ѵ��ķ�ʽ��������Ҫ���ĸ��ͽ��ĸ��ŵ���������ˡ�Linux��ʹ��ͼ�λ����µ�ʱ��Ҳ������������û��ʲôҪר��������˵һ˵�ı�Ҫ�����������������������һ�������ˡ�������֪���������������ͬʱ���ж��������ͬʱ�������ն˵��������ͱ�ˣ���С�����ˣ���Ϊ�Ǹ����㡣���������Ǿ�Ҫ����Linux����ô����������ġ�
2.4.1 ִ�г���ķ������ֻ�Ǽ�����������ִ��һ����������һ���dz������⣬��������һЩ�������ʶ���˶�Ӧ���ܹ��µ���ֱ�������������ƾ���ִ�г���û����Linux����������Ƶģ���������֮ǰִ�е���Щ�������������Ǿ���ij���������Ҳ���Ǿ���ij���������������������飬����Ҫִ�е�ǰ�����ڵ�Ŀ¼�µ�һ����ִ���ļ�ʱ�����ܻ��˼����ֱ���������������������ִ�У���ΪWindows����������Ƶġ����ǣ���Linux����ܻ��ջ�ʧ�ܣ���ΪLinux��Windows������Dz�ͬ�ġ�������ֱ��������������������֮��Linuxϵͳֻ����$PATH����������ָ������Щ·����������Ӧ�ij���Windows��������һ�µ�ǰĿ¼��������$PATH��ָ����Ŀ¼��������Ҳ�����ʧ�ܡ����Ҫִ�в���$PATH��ָ����·���еij�����ʹ�����·�������·�������ԣ��������ڵ�ǰ·���µ�һ�������ļ�������abc.exe������Ҫʹ��./abc.exe������ʹ��Windows��ϰ�ߣ�ִ�����ļ�����չ���ǿ��Ժ��Եģ�����Linux��������Ҫ��չ���������ļ��Ŀ�ִ���ԣ�����Ҳ���ܺ�����ν����չ����
����������ǰ�������cpio����ִ�е�������������������һ�������⣬��Ϊ������ʽ�ȽϹŹ֡���������Ҫ��/bootĿ¼�µ������ļ������һ���ļ������ǿ���ִ�����������
$ find /boot | cpio -ocB > /tmp/boot.img
��������һ��������������ͬ���������find��cpio�����Dz�����������������ͬʱִ���أ����ǿ϶��ġ�������ֳ�Linuxϵͳ������������ˣ����һ����ֳ�Linuxϵͳ�������Э�������ԣ����������֮�����ܹ����ﻥ���ġ���������֮������ߡ�|������������Э�����õģ��Ƚ�רҵ�ijƺ��С��ܵ������������ֳ���ֱ�ӵ�Э������Ҳ����֮Ϊ���ܵ�������Ϊרҵ�����ƽС������ܵ�����
�ܵ���Linuxϵͳ�ṩ�Ķ�����Э�����Ƶ�һ�֣�Ӧ��ʮ�ֹ㷺���ܵ��ɷ�Ϊ�������������֣����Dz����������Ƕ�ӵ��һ����ͬ�����ԣ���������ֻ�ܴӹܵ���һ��д�벢����һ�˶�ȡ�����Ҷ�����˳����д���˳������ͬ�ġ����Թܵ�Ҳ����FIFO��First Input First Output������ô�����������ܵ���ʲô�����أ���ʵ������ʱ������ʽ���IJ����ν�������Dz�������������У�������ʱ����������������Ҫ����̶�����Դ���й̶��ĸ�λ�ͱ��ƣ��������û��Dz������������Ƕ��������㽫���������У���������ʽ����������ǰ������ӣ�ʹ�����ߡ�|�������Ĺܵ�������������ʱ������Ҫ���������ܵ�����Ҫʹ��mkfifo�������������ָ����·���ϴ���һ���ļ�����Ϊ��p�����ļ�����ʵ����ͷ��ʽ����Խ��Խ�ٵģ��ܶ����鶼����ʱ���ɵģ�Linux��㻹�Ƿdz���ʱ����ġ�
�����ٻص�ǰ���оٵ����ӣ�find����ڹܵ���д��ˣ�cpio����ڹܵ��Ķ�ȡ�ˡ�ͨ������ִ�С�find /boot���������ǿ����˽�����/bootĿ¼�µ������ļ�����ʾ����Ļ���ˡ��ڱ����У���Щԭ��Ҫ�������Ļ�ϵ����ݲ����ˡ�ȥ���������أ��ܵ��Ȼ����������cpio�ڲ�������ͳͳ���ѹ������/tmp/boot.img�ļ��С�����������˺�Ϳ�ˣ���ô�ö˶˵�����Ļ������������ܵ��ܵ���ȥ���أ����������Linux�е�����һ�������I/O�ض���
I/O�ض���Ҳ��Linux�ṩ��һ�ֶ�����Э�����ơ����Ե�I/O�嶨���ǰ������A�Ķ����ض������B�����߷�����˵��Ҫ��A����õ������ض���B��ȥ����ˡ������ǵ����������������ض���Ӧ���ˣ����һ�Ӧ������ʽ�ض������ʾ�ض������ַ�ʽ����ʽ�ض������ڡ������ܵ�������find����������Ļ�Ķ����ض�����˹ܵ�д��ˣ���cpio����Ҫ�Ӽ��̻�õ������ض����˹ܵ������ˡ�������find��cpio�ͽ�������ͨ·��find��ѯ�������ļ���ԴԴ���ϵ���cpio������������Ӧ���ļ��������������cpio��Ӧ����һ����ʾ���ض������Ҽ����š�>��������ʾ��ָ���������������Ļ�������ض������ļ��С����ǵ����Ӿ��ǽ�cpio����������ض���/tmp/boot.img�ļ��б���������˳��˵һ�䣬���������ܵ�Ҳ�Ǵ����˾�����ļ�������ʹ�������ܵ�ʱ�����дӦ��ʹ����ʾ��I/O�ض���
ͨ���������ݵĽ��ܣ�����Ƿ��Ѿ���������������������find��cpio������ˮ��һ���ڼӹ����ݡ���ʵ�������Ը�⣬���ܹ���������ˮ���ϼ�������Ԫ�ء���������Ҫ��cpio������ļ���Ҫ����ѹ��������ִ������������:
$ find /boot | cpio -ocB | gzip -9 >/tmp/boot.img
��ͻ��������������һͬ�����ˣ��������ݴ�find��ʼ������cpio���������gzip����ѹ�����������/tmp/boot.img�ļ�����������������ˮ��������������ֳ���ִ�з�ʽҲ��һ��ʮ�����е����֡�����ʽ������
����һ���ض������������š�<��������ʾ��ָ����һ���ļ��������ض����������С���ô����cpio�������������������ʱ��Ӧ������������
$ gzip-dc /tmp/boot.img | cpio -idc
Linux�ϵĴ��������֧��������ʽ����������������ʽ�������������ɼ�����������ȥ��ɺܶ�����������ĸ���������Ҳ����Linux���˵ĵط����ڣ��������ǡ�ֻ�����벻��û������������������Ҫ����ij���Ҳ֧��������ʽ����Ҳ�Ƿdz��ģ�ֻҪ�Ӽ��̻�����룬Ȼ����������Ļ�Ͼͻ�����������Ҫ���ˡ���Ϊ����ģ���������½ڻ�������ϸ������
��Ȼ��ʽ�������������������һִͬ�У�������Щ����һЩ������ij��������Ҫͬʱִ��һЩ����صij����һ�ϣ������ͼ�ν����������ܹ������л�����ô�����أ����Ҫ�漰����ǰ��̨�����ˡ�
��νǰ̨������ǵ�ǰ�����ǽ����ij�����̨�������Ȼִ���ŵ��Dz������ǽ����ij�����ͼ�ν��治ͬ�����������£�ǰ̨����������Ψһ�ɼ�������̨����Ҫ���Ϊǰ̨�������ȵ�ǰ��ǰ̨�����л��ɺ�̨���ѵ�ǰ�����л��ɺ�̨������Ҫʹ�ÿ�ݼ���Ctrl+Z��������ִ�����
$ tail -f /etc/profile
֮���¿�ݼ���Ctrl+Z�����ͻῴ��������������ݣ�
[1]+ Stopped tail-f /etc/profile
Ȼ��ִ�����
$ bg
[1]+ tail -f /etc/profile &
��ʹ��������Ѿ����ղŴ�����ǰ̨�����л�����̨�ˡ���������ֱ�Ӵ���һ����̨����Ҳ����ֱ��������ĩβ���ӡ�&����������ɣ����磺
$ tail -f /etc/bashrc &
[2] 29732
����
Ȼ������س����Ϳ��Լ����������������ˡ������������������̣������Ѿ�������������̨�������Ҫ�鿴��Щ������ʹ��jobs������磺
$ jobs
[1]- Running tail -f /etc/profile&
[2]+ Running tail -f /etc/bashrc &
ע��ǰ���[1]��[2]��Щ���֣�����������ţ�Ҫ�뽫ij����̨�����л���ǰ̨�������������������ˡ��л�������fg�����磺
$ fg 1
tail -f /etc/profile
��������tail -f /etc/profile���ͱ��л���ǰ̨�ˡ�����ע������ź�����Ǹ���+���͡�-�������С�+������������Ĭ������ִ�в����κβ���ִ��fg����ʱ�л���ǰ̨������
������ν���һ������ǰ̨�ij�����´�Ҷ���İ����Ҫô����ִ����ϣ�Ҫô�Ͱ���Ctrl+C���ɵ��������Ƕ��ڱ��л�����̨�ij���Ctrl+C���ɾͲ������ˣ��ѵ�����Ҫ���������ij����ֻ�ܵ����Լ�ִ����ϻ����л���ǰ̨�𣿲��ǣ�Linux�»��е�����ѡ����ʹ��kill����ɵ�����������Ҫ�ɵ�2������������������
$ kill -9 %2
$ jobs
[1]- Running tail -f /etc/profile&
[2]+ Killed tail -f /etc/bashrc&
��Ҫע�⣬kill�����Ǵ����źŸ�������������̣�-9����һ���źš�����ź��൱�Ե�����ǿ�Ƹɵ�һ�����������������̡���killĬ�Ϸ������ź�ʵ������-15������źŻ�ʹ�ó��������˳��������й��źŷ������Ϣ�������������ݻ�������ϸ���ܣ��Ȳ������˿���ִ�С�man 7 signal��������ǰѧϰ�����⣬kill�������Ǹ�����ʵ�����Ǵ���һ�����ֵĽ���ID����������������г�ͻ������Ҫ����%���������֡�
�ղ�˵����Ҫ�ɵ�ij�������ǻ���һ��ʮ�ּ��ֵ�������Dz�ϣ�������ʸɵ���������ʲô����»ᱻ�ʸɵ��أ����˳��ն˵�ʱ��ͻᡣ��ΪLinux����������������ն˹����ģ�ֻҪ���˳����նˣ�����������������ᱻ�ɵ���������Щʱ�����ֲ������������ն�ǰ�����������ɵ�����ô���أ�ʹ��nohup������ܱ�֤���������������������ն˵Ĺ�����һ����÷��ǣ�
$ nohup [���������] &
��Ҫע�⣬�������������������������nohup.out����ļ��У������������Ͳ���������ն���ʲô��ϵ�ˡ����ĵĹص��ն˻ؼ�������ȥ�ɣ�
�����Ĺ��̾ͻ�����������Linux���ж�����ʹ�ú��л��ķ�������ȻҪ��Windows��ͼ�ν����ϵ�����Ҫ��ܶ࣬������ִ�����������ʱ���DZȽϷ���ģ��Ͼ�Linux�����Ŀ�IJ������������л�������ġ����Ǵ����������ʹ����ʽ��ʽִ�г���ģ�����Ҫ�ܺõ����չܵ���I/O�ض���ļ��ɡ�
2.4.2 �ƻ�����ʹ�üƻ���������Linux��ִ�г��������һ�ַ�ʽ����Ϊһ���Եĺ������Ե����ࡣ
ִ��һ���Եļƻ�������Ҫʹ��at���ÿ��ִ��at������Ҫ��������һ��ʱ���������ָ���ƻ�����ִ�е�ʱ�䡣���磺
$ at 10:00 tomorrow
��������Ҫ����������10����ִ��һ��������ô��ô�趨����Ҫִ��ʲô�����أ�Ҫ֪���𰸾͵ؼ������¿�������ִ��at����֮�������л���������
at>
ֻҪֱ��������ִ�е�����ɣ�����echo "hello world"������������֮����ϼ�Ctrl+D�����档Ȼ��ͻ�������ʾ��似���������ݣ�
job 1 at 2012-12-20 10:00
��˵����job 1������2012��12��20�յ�10����ִ�С���������ͳɹ��Ĵ�����һ��һ����������Ҫע�⣬�������о�������ӵ�ʱ����Щ͵������Ҫ��echo�����������û���ṩȫ·�����Ⲣ���Dz��ԣ����Dz��ܹ淶����Ϊֱ��ʹ��������ִ�г����ܹ��ɹ��ĸ�������Ϊ��PATH�������������PATH��������û���趨����ô����ֱ��ʹ������ִ�еij���ʧ�ܡ���Ȼ����ƽʱ��������PATH��������û�б����õ�����������ڼƻ���������ȷ�ܳ���������ʹ��ȫ·����ִ�мƻ������Ƿdz����õ�ϰ�ߡ�Ϊ�ˣ����ǵ�����Ӧ�øijɡ�/bin/echo "hello world"����������Ȼ���������Ǻ����ۣ����������ܹ���֤����ִ�гɹ�������ÿ���ƻ�����Ҳ����ֻ��ִ��һ������Ҳ������һ�����л��ֵij����б�����ִ������ʱ����������ֵĴ�������ִ�С�
��֪�����Ƿ�ע���at�����ڽ����������ʱ��ʹ���˱Ƚ����ص��Ctrl+D�������������ݡ���Linux��Ctrl+D����EOF��˵���Ѿ�������ϡ���������EOF����ֱ�ӴӼ����л��������������Ч��������Ctrl+D֮�����Ӽ����л�õ���������ˡ����е����ִӱ������ȡ�������ݵij�����ʹ����似�����������ݡ���������¼�����ݵķ�����һ��ȱ�㣬����һ���м��д���ֻ��ȫ��������Ϊ���ֲ����ȱ�㣬����ʹ��I/O�ض���һ���ļ��е������������������Ҫ���ľ��DZ༭���Ǹ��ļ������ݡ��ͱ���������ӣ����ǿ����ȴ���һ������������ļ�Ȼ�����ǾͿ���ʹ�á�<�����������ļ������ݴ�����������Ϊһ���µļƻ�����������Ҳ���ῴ����at>����������ʾ���ˡ�
һ��һ���Լƻ������Ǻ���Ӧ�õģ����������Լƻ�������Ҳ��ʱ�ܶ��˶�����������������cron���������˽�at�ĸ���ԭ��
ʹ��cron����ͨ��crontab��������ɵġ���crontab �Ce�����༭��ǰ�û���cron������crontab -l���鿴��ǰ�û���cron������crontab �Cr��ɾ����ǰ�û���cron���̣���crontab -u �û�������ij�û�������������cron������Щ�����Ͼ��Dz���cron��ȫ���ˡ�
Ϊ�˴���һ��������������Ҫʹ�á�crontab �Ce����������cron����������������vi�������༭cron�����������ʹ��vi������������ר�ŵ��½������ܣ�Ŀǰֻ��Ҫ��һ�¡�i��������༭ģʽ���ɡ�
һ��cron������cron����һ������ʾ��ÿһ�б���Ϊ���У������ʱ�䣬�ұ��Ǿ������е������at��ͬ������ʹ�������ȫ·����ʱ������5��������ɣ�ÿ�����ÿտ������ֱ������
lÿСʱ�ĵڼ����ӣ�0��59��
lÿ��ĵڼ�Сʱ��0��23��
lÿ�µĵڼ��죺0��31��
lÿ��ĵڼ��£�1��12��
lÿ�ܵ����ڼ���0��6��0��ʾ�����ա�
���⣬��ʱ�������֮�䣬����һ����ѡ���û���������˵��cron�Ժ����û�������ִ�������ˣ�һ��cron�������������Ӧ���ǣ�
���� Сʱ �� �� �� [�û���] ����
���Ҫ�趨����̫̫�������죬ÿ���������������礼���ô������cron������������һ����
0 * 1 8 * echo "���Ŵ��˵����գ�Ҫ��礼�"
Ȼ��ESC�����˳�������ģʽ�����롰:wq�����˳������档������ÿ��8��1�գ�����ͻ������ҡ����ǣ���ͻȻ���������������е�̫�����ˣ�����0��Ϳ�ʼ�����ҡ�����Щ���ף��ɴ�����һ���ģ�
0,15,30,45 12 1 8 * echo "���Ŵ������գ�Ҫ��礼�"
������ֻ��8��1�յ�����12�㣬ÿ��15���ӣ���������һ�Ρ�����趨��Ȼ���������Ƕ����д������������������Ҫ�Ľ�һ�£�
*/15 12 1 8 * echo "���Ŵ������գ�Ҫ��礼�"
����û�䣬��Ȼ�����һЩ���Һ����⡣
ͨ���������Щ���ݣ����ԱȽ�ֱ�۵ؿ�����cron���е�ʱ���趨ӵ�м��ߵ�����ԣ�ʹ���趨��������dz����㡣ÿһ��ʱ����������м��ַ��ű�ʾ�����2-1��ʾ��
��2-1cronʱ�����
����
����
*
��������ʱ��
,
�����ָ�����������ʱ��㣬����2��3��ʾ2��3����
-
����������ʱ��Σ�����2-4��ʾ2��3��4
*/n
��ʾÿ����λʱ��
��Ȼ�ƻ�������ʱ�dz����ã�����Ҳ���������û��������ӵģ�����˭�����Ӽƻ�������Ҫ��ϵͳ�����ĸ��ļ���������at.allow��at.deny��cron.allow��cron.deny����ʵ���ý���Ҳ�ܲµ�����at��ͷ�Ĺ�at����cron��ͷ�Ĺ�cron��������Щ�ļ����л����Եģ���allow��deny����ͬʱ���ڡ�allowҲ�а�������denyҲ�к�������������allow�е��û�������ָ���ƻ�������deny�е��û��Ͳ�����ָ���ƻ�����ǰ�Ĵ����Linux���а�ʹ�ú��������ƣ��Լƻ�����Ȩ�Ĺ�����Ժܿ��ɡ�
2.4.3 �ػ������ƻ���������Ͼ���������ˣ�����ʲô�����ľ����Ǹ����С����ʰɡ���ô��������Ҫ�����ƻ���������ô��ִ�е��ˣ�����Ҫ�鹦���ػ����̡�
Linux������������ʱ��Ҫ�����ܶ�ϵͳ������ʵWindowsҲ�������������ػ������û��ṩ��Linux��ϵͳ���ܽӿڣ�ֱ������Ӧ�ó�����û����ṩ��Щ����ij������������ں�̨���ػ����̣�daemons����ִ�еġ�
�ػ������������ںܳ���һ�ֽ��̡����Ƕ����ڿ����ն˲��������Ե�ִ��ij�������ȴ�����ijЩ�������¼������dz���������Linuxϵͳ����ʱ�������ر�ʱ�رա�linuxϵͳ�кܶ��ػ����̣�������������������ػ�����ʵ�ֵġ����⣬ijЩ�ػ����̻�Э������˺ܶ�ϵͳ�����縺��ƻ������atd��crond�������ӡ��lqd�ȡ�
��Щ����Ҳ���ػ����̳���������������格����������������һЩ��ͬ�ģ�ֻ��һ�����Dz���ȥǿ�����ǵ���ͬ�����һ��Ҫ�ֳ����Ƿ�������ô�������Ǿ�̬�ĸ�����ػ������Ƕ�̬�ĸ���������ػ������ṩ��ѡ��������Щ�ػ����̣�Ҫ���ݾ����������������鿴ϵͳ��ӵ����Щ�ػ����̣�����˵�ܹ��ṩ��Щ������ʹ��ntsysv�����RedHat��Cent OS�У���Ҫ�ɹ�ִ����������Ҫʹ��rootȨ�ޡ�
ʵ�����ػ�����Ҳ���з���ģ���������������������ʽ�����֣���Ϊ����������stand alone��xinetd���ࡣ
��ν��stand alone���������ϵ���˼�������ǡ��������ĺ��塣�������͵��ػ������������ص㣬һ�ǿ��������������ж�����Ҫ����ϵͳ������������������������֮���һֱռ���ڴ���ϵͳ��Դ����������ػ�����ӵ����һ���dz�ͻ�����е㣺��Ӧ��졣stand alone�ػ����̷dz��࣬������apache��mysql�ȶ��ǡ�
����xinetd��һ�ֱȽ����͵��ػ����̡�����һ��ͳһ��stand alone�ػ����������������������ػ����̻���һ�����������֡���superdaemon��֮���Ի��������ֻ��ƣ�������Ϊstand alone��һֱռ���ڴ����Դ���Եú��˷ѡ�����һЩϲ������ϸ����˾����������������ָ��Ҳ����˵����û�пͻ���Ҫ���ʱ��xinetd���͵��ػ����̶���δ���������пͻ���Ҫ������ǣ�super daemon�Ż�ȥ���Ѿ����xinetd�ػ����̡��������ְ������Ļ��Ƶ�����ȱ����Dz��ܼ�ʱ��Ӧ�������ŵ�Ҳ�dz���������һ������super daemon�����Ѹ��������˿��Ը���super daemon��ȫ�ܿصĻ��ƣ������似�������ǽ�Ĺ����ˣ������Ҳ��������Ƴ��ԣ����ͻ��˵�����������رղ���һֱռ��ϵͳ��Դ��
�����Linux���а�Ὣ����stand alone�ػ����̵������ű���������/etc/init.d/Ŀ¼�£�����һ�����ϵ�Ŀ¼����Cent OSʵ�����Ƿ�����/etc/rc.d/init.d/Ŀ¼���ˣ���/etc/init.dֻ������һ���������ӡ�����ڼ����ʱ��ֻҪ��ס����Ŀ¼���ɣ���Щ���а��Լ�ˣ��С�����Ͳ�Ҫ�����ˡ�
ֱ��ִ��ij��stand alone�ػ����̵������ű�����ʾ��������ű����÷������硰/etc/init.d/atd������ű��������������÷���ʾ��
Usage: atd{start|stop|status|restart|condrestart|try-restart|reload|force-reload}
����start��stop��restart����������ѡ������ͨ�õģ���������stand alone�ػ����̵������ű�֧�֣��ֱ����������ֹͣ��������
xinetd�ػ����̵������ļ�������/etc/xinetd.d/Ŀ¼�º�/etc/xinetd.conf�ļ���һ�㲻�ù���xinetd.conf�ļ������ݡ���/etc/xinetd.d�е�ÿ���ļ�����һ��������xinetd�ػ����̡�����rsync����������������ʾ��
# default: off
# description: The rsync server isa good addition to an ftp server, as it \
#allows crc checksumming etc.
service rsync
{
disable = yes
flags = IPv6
socket_type = stream
wait = no
user = root
server = /usr/bin/rsync
server_args = --daemon
log_on_failure += USERID
}
���С�disable=yes���������ػ����̴��ڹر�״̬�����Ҫ����rsync����ֻҪ�ijɡ�disable=no�����ɡ�Ȼ��ִ��/etc/init.d/xinetd restart����super daemon�����������пͻ�������rsync�����ʱ��xinietd�ػ����̾ͻ�����/usr/bin/rsync�������ṩ����
��Ȼ����֪������ο���һ��xinetd�ػ����̣����ǵ��ͻ�����rsync�����ʱ��xinetd��ô��֪������/usr/bin/rsync��������أ�����/etc/services�ļ��У�������ļ������ǻ��ҵ���似���������ݣ�
����
rsync 873/tcp #rsync
rsync 873/udp #rsync
����
��Ϊrsync�����ṩ����Ķ˿���873����xinetdҲ���������˿ڣ��������пͻ������ӵ�����˿��ϣ�����/etc/services�ļ����˽��rsync����Ȼ�����/etc/xinetd.d/rsync�ļ��е������ж��ǿ���״̬��������������
2.4.4 ������Ϣ��ĿǰΪֹ��Linux�����ִ�г���������Щ������ʽ���Ѿ��������ˣ�������Щ���ݶ���һ��ӵ�ж������ܵ�ϵͳ��ԶԶ��������Ӧ�����û��ܹ��˽��ǰϵͳ����������Щ����ʹ������Щ��Դ�Լ�����֮��Ĺ�ϵ��ʲô��ps��top��pstree���������������ṩ����Щ���ܡ�
ps������Ҫ�Dz鿴����ľ�̬��Ϣ������ij��ʱ��ij����������ߢȡ�������Ƚϳ��õ��÷��У���ps aux���鿴ϵͳ�����г�������ݣ���psux���鿴��ǰ�û����г�������ݣ���ps �Cl���鿴�뵱ǰ�ն˹����ij������ݡ�ע�⣬�е��С�-�����е�û�С�-��������ps��man page�dz����ӣ����Դ��ֻҪ��ס�����ṩ�������������÷������Ͼ��������ճ������ˡ�
���ڡ�ps -l����������ǵĻ�����ִ�еĽ��������ʾ��
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 500 2570 2569 0 80 0 - 27134 wait pts/1 00:00:00 bash
0 R 500 10716 2570 0 80 0 - 26487 - pts/1 00:00:00 ps
��Щ�ֶεĶ������2-2��ʾ��
��2-2��ps -l����������ĸ��ֶ�˵��
�ֶ�
˵��
F
�����־�����������ִ��Ȩ�ޣ�������ȡ值�У�0����ͨȨ�ޣ�4��rootȨ�ޣ�1���˳����ִ����fork��û��ִ��exec
S
����״̬��R�������У�S��˯��״̬���ɻ��ѣ�D�����ɱ�����״̬��һ�����ڵȴ�I/O��T��ֹͣ״̬�����类���Ե�ʱ��Z����ʬ״̬�������Ѿ���ֹ��ȴ�����Ƴ����ڴ���
UID
�˽���ӵ���ߵ�UID
PID
�˽��̵Ľ���ID
PPID
�˽��̵ĸ�����ID
C
CPU��ʹ���ʣ���λΪ�ٷֱ�
PRI
�������ȼ�
NI
�������ȼ�����值
ADDR
ָ���ó������ڴ���ĸ����֣�����Ǹ� running �ij���һ��ͻ���ʾ��-��
SZ
�˳����õ����ڴ�
WCHAN
��ʾĿǰ�����Ƿ������У���Ϊ��-����ʾ����������
TTY
��½�ߵ��ն˻�λ�ã���ΪԶ�̵�½��ʹ�ö�̬�ն˽���
TIME
ʹ�õ���CPUʱ�䣬ע�⣬�Ǵ˳���ʵ�ʻ��� CPU ���е�ʱ�䣬������ϵͳʱ��
CMD
����command����д��Ҳ���dz�������
��Ȼ�����ϱ����⡰ps -l��������������ʲô���£�����ǧ�����Ϊ��Щ����ȫ���ˣ���Ϊ��psaux��������������̫һ��������ɲο�������ʾ��
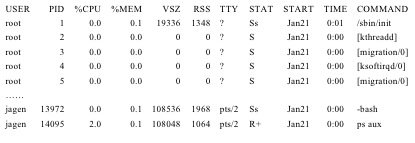
����ɵ眼�˰ɣ������������������е㲻һ�������Ҿ�����һ�����ɣ�����2-3��ʾ��
��2-3��ps aux����������ĸ��ֶ�˵��
�ֶ�
˵��
USER
�ý���������ʹ�����û���
PID
�ý��̵Ľ���ID
%CPU
�ý�����ռCPU��Դ�İٷֱ�
%MEM
�ý�����ռʵ���ڴ�İٷֱ�
VSZ
�ý����õ��������ڴ�����kbytes��
RSS
�ý���ռ�õĹ̶����ڴ�����kbytes��
TTY
�ý��������е��ն˻��������ն˻�������ʾ��?�������⣬tty1-tty6 �DZ�������ĵ�½�߳�����Ϊpts/0�ȵȵģ����ʾΪ���������ӽ������ij���
STAT
�ý��̵ĵ�ǰ״̬���롰ps �Cl����S�ֶ���ͬ��R/S/T/Z��
START
��������ʱ��
TIME
�ý���ʹ��CPU���е�ʱ��
COMMAND
�ij����ʵ������
��Щʱ��ps aux�����������COMMAND�ֶλ�dz����������ڱ��ն���Ļ�ضϡ�����������ķ�����ʹ��more�����������ʹ�ã�
$ ps aux | more
����������һ������ʾ��ϣ�more���������Ļ����ֹͣ��������س���enter���������Լ����鿴��������ݣ�Ҫ�˳�������Q������
��ps���ݲ�ͬ�IJ����������ͬ����������Ȼ�DZȽϿ��˵���ƣ�������Ҳ��psǿ������֡���Ϊ������ƣ�����ʹ��ps�����������Linuxϵͳ�е�����������ʹ�ã����ùܵ���I/O�ض�����ʵ�ָ�Ϊ���ӵij�����Ϣ�۲����Ҳ����ΪpsҪ��������������ʹ��������һ���ľ����ԣ��Ǿ���ֻ��ߢȡijһ��ʱ���ij���״̬�����������̬���ϵͳ�г��������״̬������ʹ��top���˳����һ�䣬ʹ��ps�����Linux�е������������ϣ�Ҳ�ܹ�ʵ����似top�Ĺ��ܡ��������ʵ�֣����Ŷ��걾�����Ӧ���ܹ�������ɡ�
top��������dz��ḻ������ÿ��5���Ӿͻ�ˢ��һ�Ρ�������ʾչʾ��top����Ĵ�������ݣ�
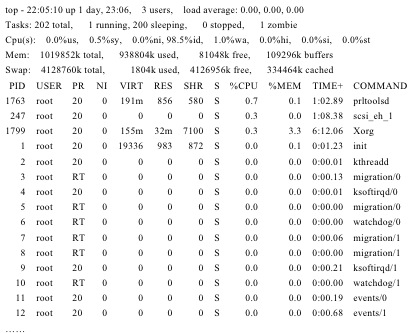
����������top������������Ϊ�������֡�����IJ���չʾ��������ϵͳ����Դ��ʹ��״̬��������IJ���չʾ�����ǵ������̵���Դʹ�������
topʹ��5���ı�����������ϵͳ����Դʹ��״̬,��ʾ�����������ǣ�
l��һ�У�top - ��ǰʱ�� up ϵͳ��������ʱ�䣬�ѵ�¼ϵͳ���û���(3 users����ϵͳ��1��5��15���ӵ�ƽ���������أ�load average����
l�ڶ��У����̵�������������������˯������ֹͣ���ͽ�ʬ����
l�����У��û��ռ�ռ��CPU�İٷֱȣ�%us�����ں˿ռ�ռ��CPU�İٷֱȣ�%sy�����ı�����ȼ��Ľ���ռ��CPU�İٷֱȣ�%ni��������CPU�ٷֱȣ�%id����I/O�ȴ�ר��CPU�İٷֱȣ�%wa����Ӳ�ж�ռ��CPU�İٷֱȣ�%hi�������ж�ռ��CPU�İٷֱȣ�%si������ǿ�Ƶȴ�����CPU��ʱ�䣨%st��������ϵͳ����Ч����
l�����У������ڴ�������������������������������
l��������������������������������������������
����top���ṩ�ĵ���������Ϣ����ǰ����ܵ�ps�������ṩ����Ϣ������似�����ﲻ����������̫һ���ľ���VIRT��RES��SHR�������ֶΡ����Ƿֱ���������ڴ�������ֻ����Ҫ�ģ�����ʵ��ʹ����������ס�ڴ�����ʵ��ʹ�����������������֣������ڴ档����һ��������ռ�õ���ʵ�����ڴ����ʹ�ù�ʽ��RES-SHR�����㡣
��top���ϰ벿������е�cpuռ�Ȳ��֣���Щʱ�����ֳ���100%���������ʵ���Ƿdz������ģ���Ϊtop�����CPUռ���ǰ��յ���CPU����������ģ����һ�����������16��CPU���ģ���ô���CPUռ����߿��Դﵽ1600%��
top������չʾ�����ݵ����������Ի�ľ���ƽ���������أ�load average���ˡ�����һ��ʲô�����أ����ǿ�����һ���г����ŵı���������һ�����˴��������ͺñ���һ���������������£���������Ҫ��ȡ������·�Ĺ��ŷ�--æ�ڴ�����Щ��Ҫ���ŵij����������ȵ�Ȼ��Ҫ�˽�Щ��Ϣ�����糵�������ء��Լ����ж��ٳ������ڵȴ����š����ǰ��û�г����ڵȴ�����ô����Ը��ߺ����˾��ͨ������������ڶ࣬��ô��Ҫ��֪���ǿ�����Ҫ�Ե�һ�ᡣ��ˣ���ҪЩ�ض��Ĵ��ű�ʾĿǰ�ij�����������磺
l0.00����ʾĿǰ������û���κεij�����ʵ�������������0.00��1.00֮������ͬ�ģ��ܶ���֮��ͨ���������ij�������˿�����õȴ���ͨ����
l1.00����ʾ�պ����������ŵij��ܷ�Χ�ڡ��������������⣬ֻ�dz�������Щ�£���������������ܻ���ɽ�ͨԽ��Խ����
l����1.00����ô˵���������Ѿ��������ɣ���ͨ���ص�ӵ�¡���ô����ж���⣿����2.00�����˵�������Ѿ������������ܳ��ܵ�һ������ô���ж������һ���ij������ڽ����ĵȴ���3.00�Ļ�����������ˣ�˵�������Ż������Ѿ�����ܲ��ˣ����г����Ÿ���������ij������ڵȴ���
�ɴ˿ɼ���ƽ���������ز��ܳ���1.00�������˾�˵��ϵͳ�Ѿ���Ҫ�����ظ��ˡ����Ǻܶ��˵�ʵ�ʾ����Ǿ����������1.00�����������һ����CPUռ����ͬ������������йء������16���ĵ�ϵͳ��ƽ���������ؿ��Դﵽ16.00��������һ������ϵͳ�Ѿ������ظ��ˣ���Ȼ��Ȼ�ܹ����У������ֻ�ܴӲ���˵��Linuxϵͳ���ȶ��Ժܺ��ˡ�
top����кܶ�ѡ����ã����бȽ���Ҫ���ǡ�-d��ѡ�������topˢ�����ݵ�Ƶ�ʵġ�top����ܵ�������ij�����̵�����״̬����������ʹ�á�-p��ѡ����磺
$ top -d 2 -p 12201
���DZ���ÿ����ˢ��һ�Σ�ֻ���PIDΪ12201�Ľ��̡�top�������У�Ҳ��һЩ�������Բ��������磺P�����õ���������Ϣ����CPUʹ��������M�������ڴ��ʹ��������N�����Խ��̵�PID���ȵȡ�
ps��top������Ժܷ���Ļ�õ������̵���Ϣ�����Ҫ�鿴���̵ĸ������ȹ�ϵ����Ȼps�����ܹ����㣬��������Ӧ����pstree�ˡ�������ʲô��Ч������ֱ�Ӳ���һ�¾ͺ��ˣ��Ͼ��˷�ֽ����һ��ʮ�ֿɳܵ����顣