记一次WEB数据采集程序开发经历――对付简单的动态加载
自从学做网站账号批量注册机、图片批量下载器,开始接触HTTP协议,了解了基本的GET/POST请求等知识,于是便开始着手开发一些小东西了。
WEB数据采集,很多人都在搞。据说搞WEB数据采集用JAVA会更方便,有很多现成的类库可用。可以说WEB数据采集这块,是C++的短板。我目前能想到的方法就是利用WinInet,这是一组关于Intelnet三大协议HTTP、FTP、Gopher的windowsAPI。这组API在MFC里有了封装,用起来更方便,#include <afxinet.h>。目前用于开发非企业级的WEB数据采集器绰绰有余。我发现这种个人级的WEB数据采集器,很多人都是用delphi开发,可能是delphi在网络这块要强点吧。
前几天在猪八戒威客网上看到一个悬赏200元的开发程序的任务。任务内容大概是这样的:开发一个程序,从一个类似于58同城的网吧招聘网上采集网吧信息。这个网站上全部是全国各地的网吧招聘信息,要求把这些网吧信息:网吧名、地区、联系人、电话、QQ采集到ACCESS数据库里。其实他的目的不言而喻,他要采集这些数据干嘛?无非是发广告呗,嘿嘿。闲话不多说,打开这个网站看。(敏感信息被我打了马赛克)
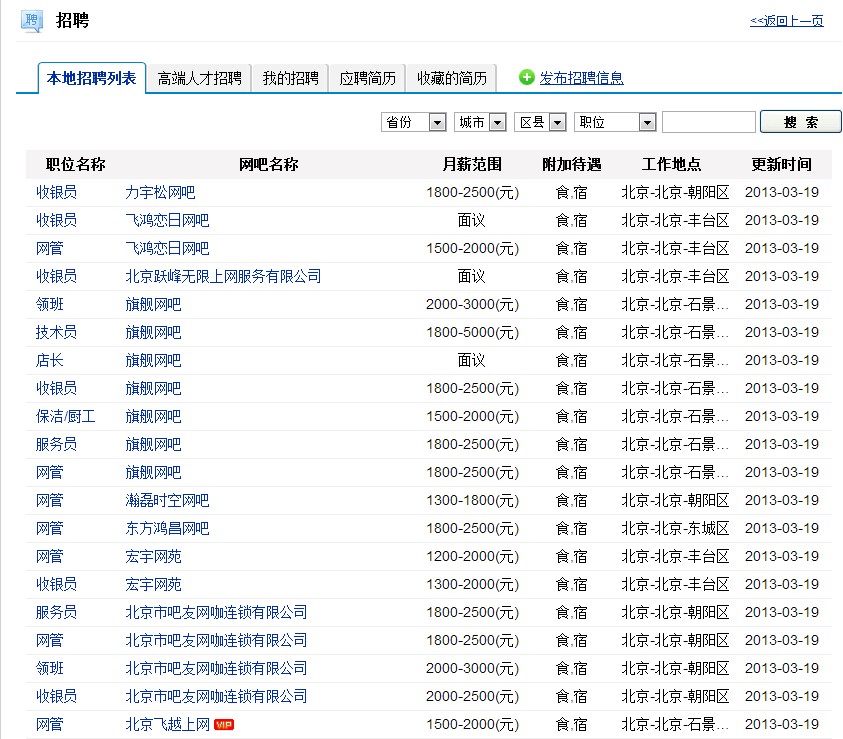
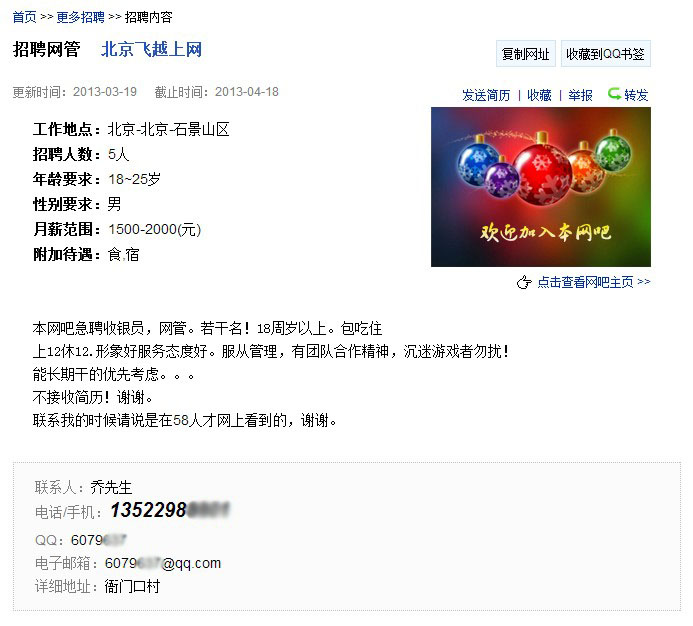
可以看出来,这些信息都只是文本,并不是图片。那就简单多了,直接从HTML里读出来不就完事了。用MFC的CInternetSession对象的OpenURL方法打开URL,返回CHttpFile指针,通过该指针调用Read方法把整个HTML页面文本全部读到缓冲区。查看缓冲区,搜索手机号1352298...,居然没搜到。搜索“乔先生”,搜到了。怎么回事?怎么没有手机号在HTML里?
用谷歌浏览器打开这个页面,右键查看源码如下:

发现联系人、邮箱、地址都有,手机号和QQ那里居然是空的。为什么是空的呢?我不停的刷新页面,思考着这个问题。突然,我发每次刷新,都是页面全部内容都出来了,手机号和QQ才紧随其后出来。动态加载!手机号和QQ没有在静态HTML里,是后来加载的。
怎么办?抓包分析!打开Fiddler,强烈推荐这个软件,专门用于抓HTTP协议的包。抓包后发现,每次打开网页,除了页面元素下载,IE进行了四次请求。

0、2、8、9号请求,一个一个查看:
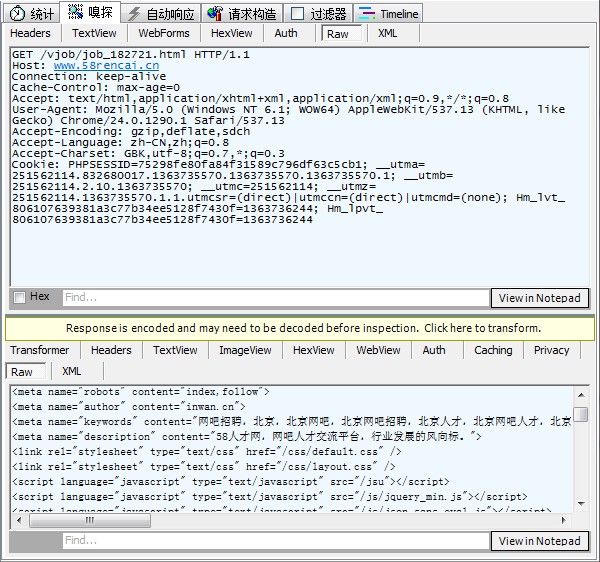
第一个GET请求,很明显,是获取页面HTML的,从下面内容看,也确实是获取了HTML页面。这些内容也就相当于我用CInternetSession获取到的内容,手机号和QQ不在这里面的,不用看了。
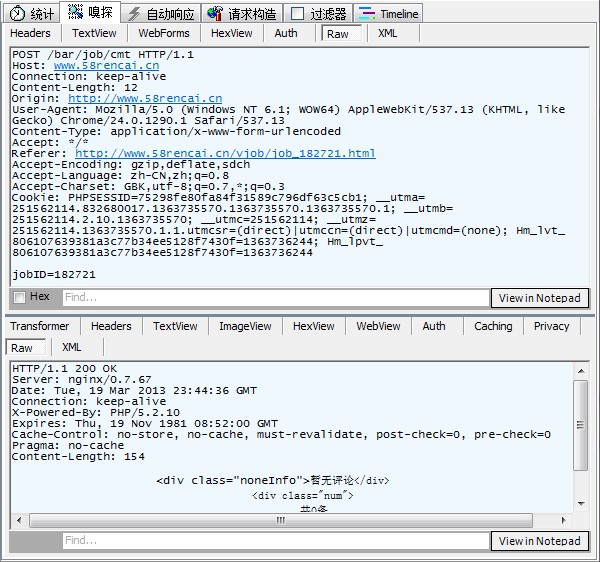
第二个是POST请求,从返回内容上来看,是获取评论的,没有我们要找的信息。
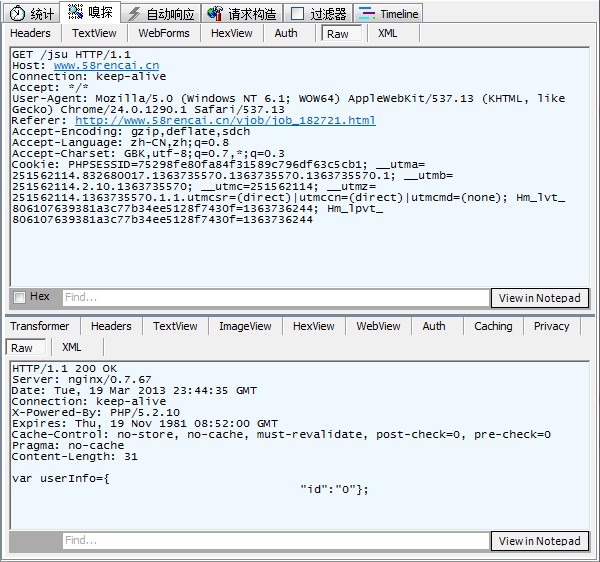
第三个是GET请求,从返回内容上来看不知道是什么,先略过。
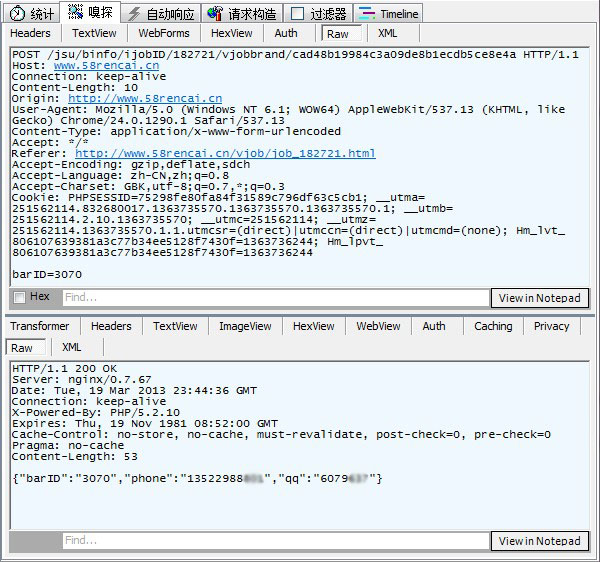
第四个是POST请求,从返回信息上来看,正是我们要的信息!原来动态加载是这么加载的。我们也用程序模拟这个POST不就行了?但是等等,注意这个POST的目标URL,最后是一段貌似密文的东西。多抓几次看看,发现这段密文每次都不一样!难道是根据时间或Cookie什么的算出来的?那样就比较麻烦了!仔细想想,这个POST提交了个“barID=3070",ID3070,这个ID号在HTML里是有的,它通过提交这个ID获取这个ID对应的网吧信息,那我们在HTML文件里搜索这个ID3070看看。

一搜还果然搜到了。太明显了,这是一段JS脚本,GetBarInfo这个函数也太明显了吧,注意后面的URL,正是我们一直想不通的那段密文!原来是这样!每次获取HTML页面后,里面都包含了不同的用于动态获取网吧信息的URL。再对这个URL用POST方式提交ID获取网吧信息。原来是这么简单。那就容易了,在我们写的程序里,用CInternetSession获取页面HTML内容后检索出这段URL和网吧ID,再用CHttpConnection对象模拟提交一个POST,就可以得到手机号和QQ号了。
可以说这个网站为了防爬虫爬取信息,还是做了一点动态加载的限制,但也太弱了点,直接在HTML里面暴露了。也是我起初一点HTML知识都不懂,搞了半天才发现,如果是熟悉HTML和JS脚本的人,应该一下就发现了吧。
看来网页这块,也得了解下,学习下,如果要继续做WEB数据采集的话。还有更多难题呢。