文本分类的阈值策略
位置截尾法, rank-based threshold
RCut:将文本指定给前t个类别。参数t即可以由用户指定,也可以通过预定初始值,然后给出测试文本,使用分类器进行分类,再根据分类的准确程度调整初始值。
优点:考虑了分类器的全局性能
比例截尾法, proportion-based threshold
PCut:将所有测试文本与某一类别的相似度按照由高到低的顺序排序,然后将前kj个
文本确定为该类别。
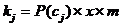
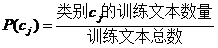
m是类别数量,Cj代表类别j,P(Cj)是类别j的先验概率。
优点:考虑了全局的分类性能,主要以x为参数,它的值可以通过分类的准确程度来调整。
最优截尾法, score-based local optimization threshold
SCut:计算所有测试文本与该类别的相似度。根据最优化该类别分类器的性能来调整相应的阈值,然后将确定的阈值应用到新的待分类文本上。
优点:性能优异
RTCut:方法修改了RCut和SCut的不足,并将二者结合起来确定类别的阈值,使查全率和查准率达到一定的平衡。在RTCut中,需要预先确定每个类的最优截尾阈值,新的阈值通过公式(3)计算:
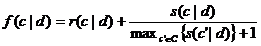
d是待分类文本,r(c|d)是RCut中类别c的排列位置,s(c|d)是类别c的SCut阈值,而f(c|d)是类别c的新阈值。
优点:召回率和精确率整体表现良好。