Linux的IO系统常用系统调用及分析
Linux的IO从广义上来说包括很多类,从狭义上来说只是讲磁盘的IO。在本文中我也就只是主要介绍磁盘的IO。在这里我对Linux的磁盘IO的常用系统调用进行深入一些的分析,希望在大家在磁盘IO产生瓶颈的时候,能够帮助做优化,同时我也是对之前的一篇博文作总结。转载此文请标明出处:http://blog.csdn.net/jiang1st2010/article/details/8373063
一、读磁盘:
ssize_t read(int fd,void * buf ,size_t count);
读磁盘时,最常用的系统调用就是read(或者fread)。大家都很熟悉它了,首先fopen打开一个文件,同时malloc一段内存,最后调用read函数将fp指向的文件读到这段内存当中。执行完毕后,文件读写位置会随读取到的字节移动。
虽然很简单,也最通用,但是read函数的执行过程有些同学可能不大了解。这个过程可以总结为下面这个图:
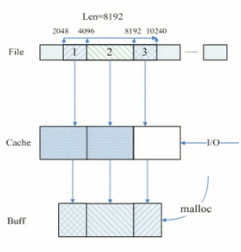
图中从上到下的三个位置依次表示:
文件在磁盘中的存储地址;内核维护的文件的cache(也叫做page cache,4k为一页,每一页是一个基本的cache单位);用户态的buffer(read函数中分配的那段内存)。发起一次读请求后,内核会先看一下,要读的文件是否已经缓存在内核的页面里面了。如果是,则直接从内核的buffer中复制到用户态的buffer里面。如果不是,内核会发起一次对文件的IO,读到内核的cache中,然后才会拷贝到buffer中。
这个行为有三个特点:
read的行为是一种阻塞的系统调用(堵在这,直到拿到数据为止);以内核为缓冲,从内核到用户内存进行了一次内存拷贝(而内存拷贝是很占用CPU的)没有显示地通知使用者从文件的哪个位置开始去读。使用者需要利用文件指针,通过lseek之类的系统调用来指定位置。这三个特点其实都是有很多缺点的(相信在我的描述下大家也体会到了)。对于第二个特点,可以采用direct IO消除这个内核buffer的过程(方法是fopen的时候在标志位上加一个direct标志),不过带来的问题则是无法利用cache,这显然不是一种很好的解决办法。所以在很多场景下,直接用read不是很高效的。接下来,我就要依次为大家介绍几种更高效的系统调用。
ssize_t pread(intfd, void *buf, size_tcount, off_toffset);
pread与read在功能上完全一样,只是多一个参数:要读的文件的起始地址。在多线程的情况下,多个线程要同时读同一个文件的不同地址时,要对文件指针加锁,影响了性能,而用pread后就不需要加锁了,使程序更加高效。解决了第三个问题。
ssize_t readahead(int fd, off64_t offset, size_t count);
readahead是一种非阻塞的系统调用,它只要求内核把这段数据预读到内核的buffer中,并不等待它执行完就返回了。执行readahead后再执行read的话,由于之前已经并行地让内核读取了数据了,这时更多地是直接从内核的buffer中直接copy到用户的buffer里,效率就有所提升了。这样就解决了read的第一个问题。我们可以看下面这个例子:
其中有两个过程会触发写磁盘:1)dirty ration(默认40%)超过阈值:此时write会被阻塞,开始同步写脏页,直到比例降下去以后才继续write。2)dirty background ration(默认10%)超过阈值:此时write不被阻塞,会被返回,不过返回之前会唤醒后台进程刷脏页。它的行为是有脏页就开始刷(不一定是正在write的脏页)。对于低于10%什么时候刷脏页呢?内核的后台有一个线程,它会周期性地刷脏页。这个周期在内核中默认是5秒钟(即每5秒钟唤醒一次)。它会扫描所有的脏页,然后找到最老的脏页变脏的时间超过dirty_expire_centisecs(默认为30秒),达到这个时间的就刷下去(这个过程与刚才的那个后台进程是有些不一样的)。
写磁盘遇到的问题一般是,在内核写磁盘的过程中,如果这个比例不合适,可能会突然地写磁盘占用的IO过大,这样导致读磁盘的性能下降。为了解决这类问题,可以让写的更加平滑一些,也就是把这几个参数都调小一下。
这样,我就简单地把这两个过程介绍了一下。关于实际使用中的例子,欢迎猛戳这里。
转载此文请标明出处:http://blog.csdn.net/jiang1st2010/article/details/8373063