毕业设计6---web网页自动分类(开题报告)3.27
(本科)毕业设计(论文)的目标: ? 目标: 对Web搜索引擎返回的页面进行自动的分类。 要点: 1. Web搜索引擎返回的页面是动态的,其文档类别是未知的、不固定的。 2. 根据页面内容自身的差异,使用文档聚类的方法对页面进行自动归类。 3. 分类显示搜索结果。 4. 满足中文查询需求。 5. 针对两类文件:a. 纯文本文件(无超链接,无格式) ?????????????????????????????? ?b. 网页(html,xml..) ?? 注:①暂不考虑各种颜色信息,以及各种格式对文本分析的影响 ?????? ②暂不考虑doc, pdf等有格式文件 6. 系统能够做到快速的反应 7. 分类结果的显示具备人性化,使用户可以轻松的根据分类目录标题找到自己需要的信息。 子功能: 1.从搜索引擎获得Web页面 2.Web网页文档的预处理 3.文档聚类算法 4.Web文档聚类结果的可视化展现 ? ? ? ? ? ? ? ? ? ? ? ? ? ? 实现方法: 本系统拟采用无监督的自动聚类算法,并根据系统的整个运作流程,划分为三个主要模块:输入模块,过滤模块,输出模块。下面针对各个模块的实现方法进行详细的讲解。  图1-1 web网页自动分类系统的基本框架 一.输入模块 自动分类系统首先需要从各大搜索引擎中获得原始数据源。这里我们根据用户输入的关键词,通过Google提供的搜索API获得查询结果的一个列表。这个便是我们最初的数据源。其中的每一条结果至少包含一个URL链接,一个标题,以及一些关于此文档的摘要。根据(Oren Zamir and Oren Etzioni,2001)的研究,源输入数据为文档摘要和整个文档的对比过程中,采用文档摘要的方法不仅大大提高处理速度,而且摘要提供的信息足以满足聚类分析的要求。所以在本系统中,我们采用文档摘要方法。 对中文内容采用中科院研制的ICTCLAS进行分词,英文使用SNOWBALL进行词干化。分词并消除噪声后,建立VSM(向量空间模型)为下面各种工作的进行打下基础。然后,进行特征提取以达到进一步降维的目的。 ? 二.过滤模块 根据建立的VSM模型和实际的情况,我们采用STC(Suffix Tree Clustering,OrenZamir,OrenEtzioni)后缀树算法对文档进行聚类。为了在最后的聚类结果中,分类目录标签更有易知性,浓缩性,并更好的反映该分类的所有内容,我们采用描述符优先方法DCFC(Description comes first clustering),与传统的聚类方式不同,DCFC先提取一个有意义的,多样的分类标签(cluster labels)集合,然后把文档聚类到合适的标签底下―这就完成了web文档的聚类。 ? 三.输出模块 聚类完成后,采用什么方式展现给用户也是个十分重要的问题。主要要求是:易懂,便捷。我们采用分类目录的结构形式提交给用户。搜索引擎返回的结果已经按照相关度的高低进行排序,所以考虑到速度,性能,效率因素,我们选取并返回一定量的搜索结果(比如默认为100条)。在界面中,为了更好的增强用户体验,我们将会加入Ajax异步通讯功能,使界面更加友好。示例如下: (查询词:“引擎”, 括号内的数字表示该类中包含的文档个数) +网络服务(6) +汽车(10) +计算机图像(7) +工业(2) +军事(9) +经济时代(3) +查看更多(…) ? 四.系统流程全图
图1-1 web网页自动分类系统的基本框架 一.输入模块 自动分类系统首先需要从各大搜索引擎中获得原始数据源。这里我们根据用户输入的关键词,通过Google提供的搜索API获得查询结果的一个列表。这个便是我们最初的数据源。其中的每一条结果至少包含一个URL链接,一个标题,以及一些关于此文档的摘要。根据(Oren Zamir and Oren Etzioni,2001)的研究,源输入数据为文档摘要和整个文档的对比过程中,采用文档摘要的方法不仅大大提高处理速度,而且摘要提供的信息足以满足聚类分析的要求。所以在本系统中,我们采用文档摘要方法。 对中文内容采用中科院研制的ICTCLAS进行分词,英文使用SNOWBALL进行词干化。分词并消除噪声后,建立VSM(向量空间模型)为下面各种工作的进行打下基础。然后,进行特征提取以达到进一步降维的目的。 ? 二.过滤模块 根据建立的VSM模型和实际的情况,我们采用STC(Suffix Tree Clustering,OrenZamir,OrenEtzioni)后缀树算法对文档进行聚类。为了在最后的聚类结果中,分类目录标签更有易知性,浓缩性,并更好的反映该分类的所有内容,我们采用描述符优先方法DCFC(Description comes first clustering),与传统的聚类方式不同,DCFC先提取一个有意义的,多样的分类标签(cluster labels)集合,然后把文档聚类到合适的标签底下―这就完成了web文档的聚类。 ? 三.输出模块 聚类完成后,采用什么方式展现给用户也是个十分重要的问题。主要要求是:易懂,便捷。我们采用分类目录的结构形式提交给用户。搜索引擎返回的结果已经按照相关度的高低进行排序,所以考虑到速度,性能,效率因素,我们选取并返回一定量的搜索结果(比如默认为100条)。在界面中,为了更好的增强用户体验,我们将会加入Ajax异步通讯功能,使界面更加友好。示例如下: (查询词:“引擎”, 括号内的数字表示该类中包含的文档个数) +网络服务(6) +汽车(10) +计算机图像(7) +工业(2) +军事(9) +经济时代(3) +查看更多(…) ? 四.系统流程全图 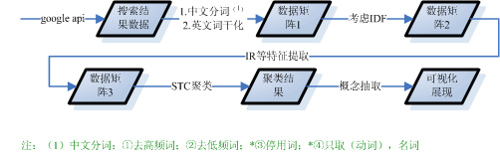 图1-2 系统流程全图 ? 五.开发平台和相关资源 1.开发工具:Eclipse + Struts + Tomcat 2.版本管理工具: CVS 3.测试工具: JUnit(单元测试) + JMeter(压力测试) 4.基于平台: Windows 5.相关资源:Google API包 ? 时间进度安排: 2007年2月26日-2007年3月31日 学习各种相关知识。熟悉系统的开发平和相应的开发工具。架构好整个开发框架。 2007年4月 1日-2006年4月 7 日?完成系统的数据获取模块 2007年4月 8日-2006年4月22日?完成系统的过滤模块。 2007年4月23日-2006年4月31日?完成系统的输出模块。 2007年5月04日-2006年5月25日?完成系统的集成测试和压力测试。 2007年5月26日-2006年6月初???? 完成毕业论文并装订。 ?
图1-2 系统流程全图 ? 五.开发平台和相关资源 1.开发工具:Eclipse + Struts + Tomcat 2.版本管理工具: CVS 3.测试工具: JUnit(单元测试) + JMeter(压力测试) 4.基于平台: Windows 5.相关资源:Google API包 ? 时间进度安排: 2007年2月26日-2007年3月31日 学习各种相关知识。熟悉系统的开发平和相应的开发工具。架构好整个开发框架。 2007年4月 1日-2006年4月 7 日?完成系统的数据获取模块 2007年4月 8日-2006年4月22日?完成系统的过滤模块。 2007年4月23日-2006年4月31日?完成系统的输出模块。 2007年5月04日-2006年5月25日?完成系统的集成测试和压力测试。 2007年5月26日-2006年6月初???? 完成毕业论文并装订。 ?
-----------------------------------------------抓鱼社区 www.zhuayu.net------------------------
1 楼 andyandyandy 2007-03-29 2007年4月23日-2006年4月31日 完成系统的输出模块。