WebKit的结构与解构
原文地址:http://blog.sina.com.cn/s/blog_46d0a3930100d5pt.html
?WebKit的结构与解构
从指定一个HTML文本文件,到绘制出一幅布局复杂,字体多样,内含图片音频视频等等多媒体内容的网页,这是一个复杂的过程。在这个过程中Webkit所做的一切,都是围绕DOM Tree和Rendering Tree这两个核心。上一章我们谈到这两棵树各自的功用,这一章,我们借一个简单的HTML文件,展示一下DOM Tree和Rendering Tree的具体构成,同时解剖一下Webkit是如何构造这两棵树的。
?
?
Figure 1. From HTML to webpage, and the underlying DOM tree and rendering tree.
Courtesy http://farm4.static.flickr.com/3351/3556972420_23a30366c2_o.jpg
1. DOM Tree 与 Rendering Tree 的结构
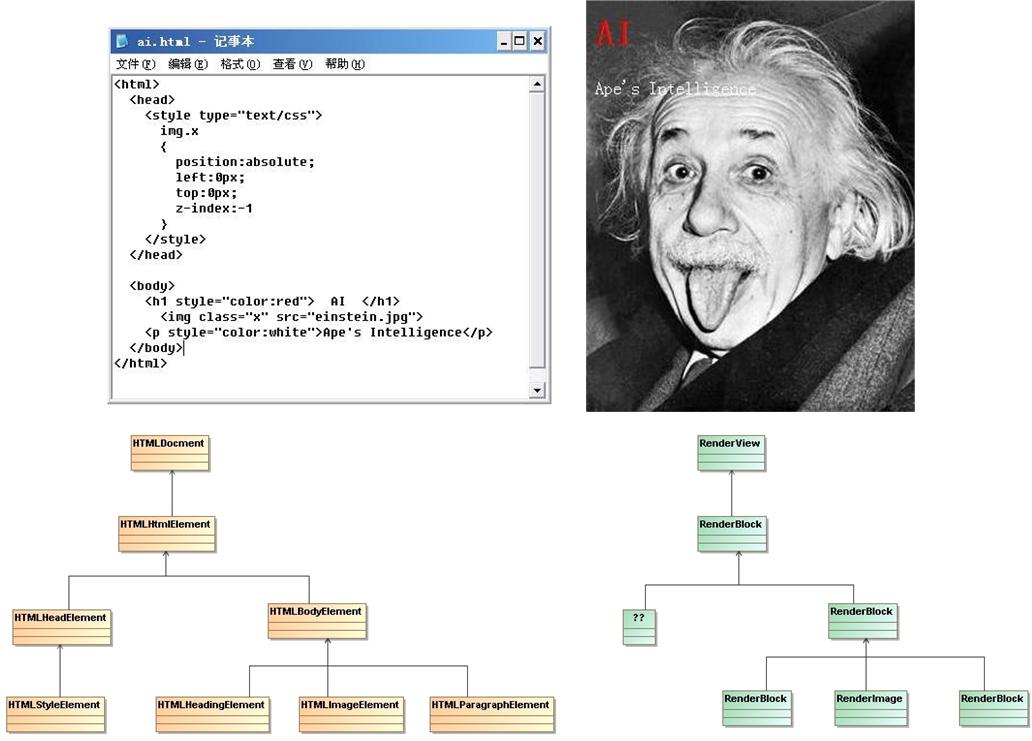
Figure 1中左上是一个简单的HTML文本文件,右上是Webkit rendering engine绘制出来的页面。页面的内容包括一个标题,“AI”,一行正文,“Ape's Intelligence”,以及一幅照片。整个页面分成前后两个层面,标题和正文绘制在前一个层面,照片处于后一个层面。L君和我亦步亦趋地跟踪了,从解析这个HTML文本文件,到生成DOM Tree和Rendering Tree的整个流程,目的是为了了解DOM Tree和Rendering Tree的具体成份,以及构造的各个步骤。
先说Figure 1中左下角的DOM Tree。基本上HTML文本文件中每个tag,在webkit/webcore/html中都有一个class与之对应。譬如<HTML> tag 对应HTMLHtmlElement,<HEAD> tag 对应HTMLHeadElement,<STYLE> tag 对应HTMLStyleElement 等等。比较特别的是DOM Tree的根节点,HTMLDocument,在HTML文本文件中没有哪个tag与之对应。关于HTMLDocument的作用,我们稍后介绍。整个 DOM Tree的结构,与HTML文本文件中各个tags的嵌套关系也一一对应。一言以蔽之,DOM Tree就是把HTML文本文件翻译成object树状结构。
需要强调的是,DOM Tree是一个通用数据结构,任何XML文本文件都可以翻译成DOM Tree,而不仅仅限于HTML文本文件。webkit/webcore/html 中林林总总html classes,基本上都是webkit/webcore/dom 中的某个class的子类,也就是说,/html 是 /dom的一个特例。这样的设计,为将来把Webkit拓展到HTML格式以外的页面的布局和渲染,埋下了伏笔。所以严格地讲,Figure 1中左下的DOM Tree,实际上是一个HTML DOM Tree。
再看Rendering Tree,显著的特点在于,
a. 整个Rendering Tree树状结构,与HTML DOM Tree树状结构一一对应。也就是说,几乎每个HTML DOM Tree中的节点,在Rendering Tree中都有对应的节点。节点与节点之间的父子或兄弟关系也一一对应。
例外的是,在HTML DOM Tree有HTMLStyleElement叶子节点,而在Rendering Tree中,没有相应的叶子节点。原因是,Rendering Tree各个节点,都涉及页面中某块区域的布局和渲染。而HTMLStyleElement,并不直接涉及某块区域的布局和渲染,HTML DOM Tree中HTMLStyleElement叶子节点包含的内容,已经融入Rendering Tree中RenderImage叶子节点的属性中去了。另外,因为Rendering Tree中不存在与HTMLStyleElement相应的叶子节点,所以,与HTMLHeadElement对应的节点也没有必要存在。
b. webkit/webcore/rendering中各个class与HTML tags并没有一一对应的关系。
Rendering Tree是一个通用的规划页面布局和渲染的机制,这个通用机制可以服务于HTML页面,但是并不仅仅限于为HTML页面服务,我们可以用 Rendering Tree来规划其它格式的页面的布局和渲染。以DOM Tree和Rendering Tree为核心的Webkit渲染机,是一个功能强大,扩展性良好的通用渲染机。它不仅可以用来绘制HTML页面,也可以用来渲染其它格式的页面,譬如可以用它来制作email阅读和管理器,制作数据库管理工具,甚至制作游戏界面。
稍微让人有点吃惊的是,对于 HTMLHtmlElement,HTMLBodyElement,HTMLHeadingElement和HTMLParagraphElement,在Rendering Tree中通通以RenderBlock呼应。如果说HTMLHeadingElement和HTMLParagraphElement的区别不大,仅仅是字体和对齐方式有些微小的差别,所以Rendering Tree可以用RenderBlock来统一应对。那么问题是,HTMLHtmlElement和HTMLBodyElement是两种容器,总是出现在 DOM Tree的中部,而从来不会作为叶子节点出现,对应于这样的容器节点,为什么Rendering Tree不另设一种class,与RenderBlock有所区别呢?不过话又说回来,这不是个大问题,最多是个美感的问题。
?
?
Figure 2. The construction sequence of the root of the DOM tree.
Courtesy http://farm4.static.flickr.com/3010/3554310018_e34d271344_o.jpg
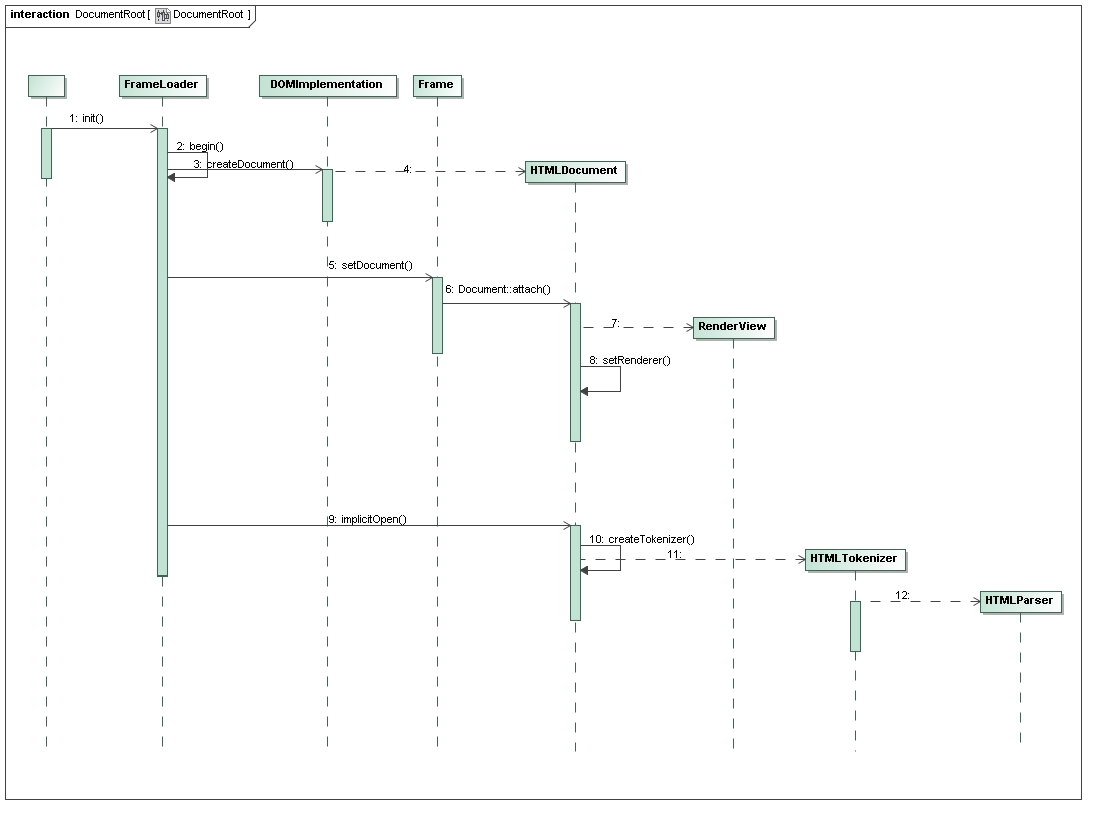
2. DOM Tree 与 Rendering Tree 的根节点
前一节中我们提到HTMLDocument是一个比较特殊的class,它是整个HTML DOM Tree的根节点,但是不对应任何HTML tag。JavaScript中经常出现的document,指的就是这个根。例如,
?? ?“document.getElementByIdx(x).style.background="yellow";”
HTML文本文件,通常是以<HTML>开头,以</HTML>结尾。但是<HTML> tag并不对应DOM Tree的根节点,而是根以下的第一个子节点,即HTMLHtmlElement节点。
初看Figure 2 觉得有点意外,当用户在浏览器里打开一个空白页面的时候,立刻生成了DOM Tree的根节点HTMLDocument,与Rendering Tree的根节点RenderView。而这个时候,用户并没有给定URL,也就是说,对于浏览器来讲,这时候具体的HTML文本文件并不存在。根节点与具体HTML内容相脱节,或许暗示了Webkit的两个设计思路,
a. DOM Tree的根节点HTMLDocument,与Rendering Tree的根节点RenderView,可以重复利用。
当用户在同一个浏览器页面中,先后打开两个不同的URLs,也就是两个不同的HTML文本文时,HTMLDocument和RenderView两个根节点并没有发生改变,改变的是HTMLHtmlElement以下的子树,以及对应的Rendering Tree的子树。
为什么这样设计?原因是HTMLDocument和RenderView服从于浏览器页面的设置,譬如页面的大小和在整个屏幕中的位置等等。这些设置与页面中要显示什么的内容无关。同时HTMLDocument绑定HTMLTokenizer和HTMLParser,这两个构件也与某一个具体的HTML内容无关。
b. 同一个DOM Tree的根节点可以悬挂多个HTML子树,同一个Rendering Tree的根节点可以悬挂多个RenderBlock子树。
在我们目前所见到的浏览器中,每一个页面通常只显示一个HTML文件。虽然一个HTML文件可以分割成多个frames,每个frame承载一个独立的 HTML文件,但是从DOM Tree结构来讲,HTMLDocument根节点以下,只有一个子节点,这个子节点是HTMLHtmlElement,它领衔某个HTML文本文件对应的子树。Rendering Tree也一样,目前我们见到的网页中,一个RenderView根节点以下,也只有一个RenderBlock子节点。
但是Webkit的设计,却允许同一个根以下,悬挂多个HTML子树。虽然我们目前没有看到一个页面中,并存多个HTML文件,并存多个布局和渲染风格的情景,但是Webkit为将来的拓展留下了空间。前文中所设想的个性化,多皮肤,多视角的浏览器页面绘制,用Webkit实现起来难度不大。
?
Figure 3. The construction sequence of the DOM Tree and the Rendering Tree.
Courtesy http://farm4.static.flickr.com/3627/3554182242_b0bec88534_b.jpg
?
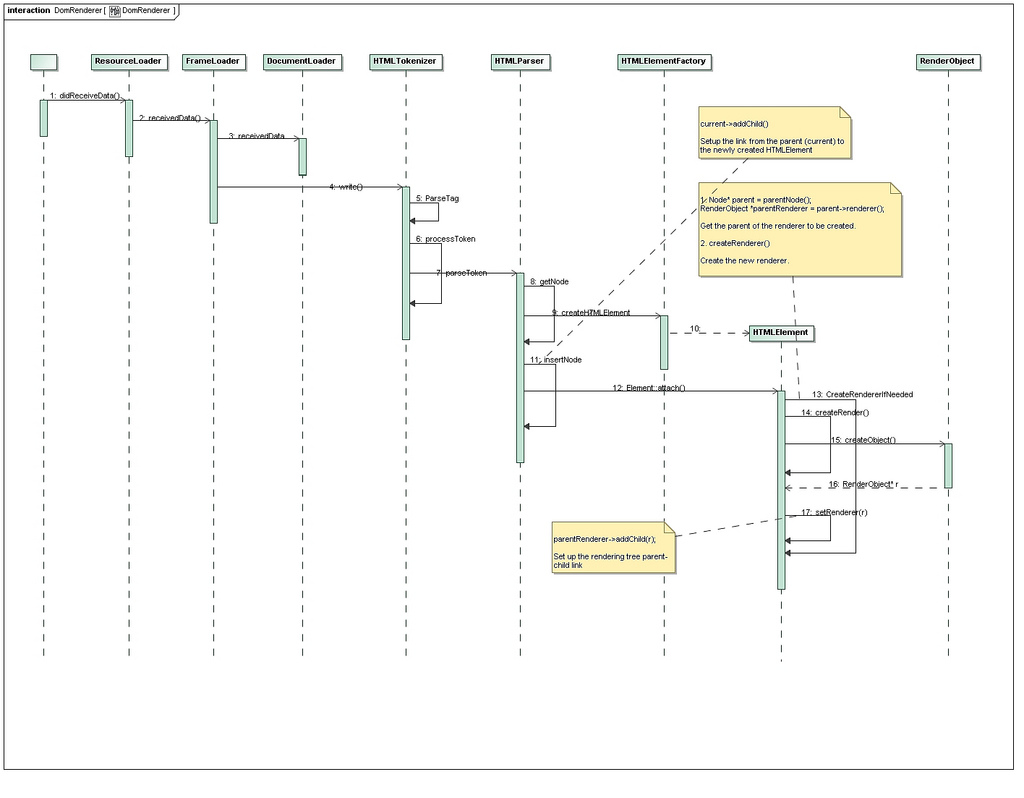
3. DOM Tree 与 Rendering Tree 的构筑
HTMLDocument 根节点包含的最重要的构件是HTMLTokenizer,而HTMLTokenizer又包含HTMLParser这个构件。HTMLTokenizer 从前到后读取HTML文本文件中每一个字符,并从中提取出各个HTML tags以及它们的内容。而HTMLParser不仅负责HTML DOM Tree的构筑,而且也同时负责Rendering Tree的构筑。
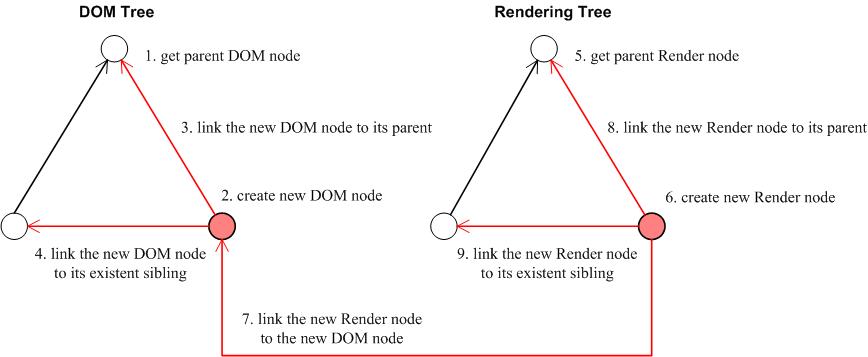
在Figure 3中,从第8步到第11步,HTMLParser根据一个HTML Tag生成一个HTML DOM Tree节点。从第12步到第17步,生成相应的Rendering Tree的节点,并把它和HTML DOM Tree的节点勾连在一起。这张图的细节过多,读解不容易。Figure 4把第8步到第17步演示了一下。
?
Figure 4. An illustration of the construction of a DOM tree node and its corresponding Rendering tree node.
Courtesy http://farm4.static.flickr.com/3306/3554259140_3deb9736ea_o.jpg
值得注意的是,每当HTMLParser生成一个DOM Tree的节点的时候,相应地,也同时生成一个Rendering Tree节点。然后把它们两个新节点勾连在一起。换而言之,Rendering Tree与DOM Tree同步生长。
Webkit 值得赞赏的地方非常多,但是HTMLParser让DOM Tree和Rendering Tree同步生长的做法,却值得商榷。如果同步生长,那么Rendering Tree必然平铺直叙地刻板地忠实于DOM Tree。假设先生成DOM Tree,再生成Rendering Tree,把两者割裂开,就有机会让Webkit发挥更加奇妙的布局和渲染。平铺直叙固然符合大多数人在大多数时间里的阅读习惯,但是离经叛道的设计,也会有市场。一个例子就是上一章末尾处那张多视点的地图。如果让DOM Tree与Rendering Tree同步生长,这样的布局和渲染是难以想像的。
?