linux MTD FALSH管理设计由于loader升级需要使用flash来保存数据,但在android系统上又没有合适的接口使用,
linux MTD FALSH管理设计
由于loader升级需要使用flash来保存数据,但在android系统上又没有合适的接口使用,因此
对MTD接口设计研究了一下并移植了flash管理代码,有些心得记录一下。
专有名词:
1. MTD:Memory Technology Device,内存技术设备,
2. JEDEC:Joint Electron Device Engineering Council,电子电器设备联合会
3. CFI:Common Flash Interface,通用Flash接口,Intel发起的一个Flash的接口标准
4. OOB: out of band,某些内存技术支持out-of-band数据——例如,NAND flash每512字节的块有16个字节的extra data,用于纠错或元数据。
5. ECC: error correction,某些硬件不仅允许对flash的访问,也有ecc功能,所有flash器件都受位交换现象的困扰。在某些情况下,一个比特位会发生反转或被报告反转了,如果此位真的反转了,就要采用ECC算法。
6. erasesize: 一个erase命令可以擦除的最小块的尺寸
7. buswidth:MTD设备的接口总线宽度
8. interleave:交错数,几块芯片平行连接成一块芯片,使buswidth变大
9. devicetype:芯片类型,x8、x16或者x32
10.NAND:一种Flash技术,参看NAND和NOR的比较
11.NOR:一种Flash技术,参看NAND和NOR的比较
1、概述
MTD就在在硬件和文件系统层之间的提供了一个抽象的接口,MTD是用来访问内存设备(如:ROM、flash)的中间层,它将内存设备的共有特性抽取出来,从而使增加新的内存设备驱动程序变得更简单。本文件就是利用MTD来编写上层管理flash程序接口.
MTD中间层细分为四层,按从上到下依次为:设备节点、MTD设备层、MTD原始设备层和硬件驱动层
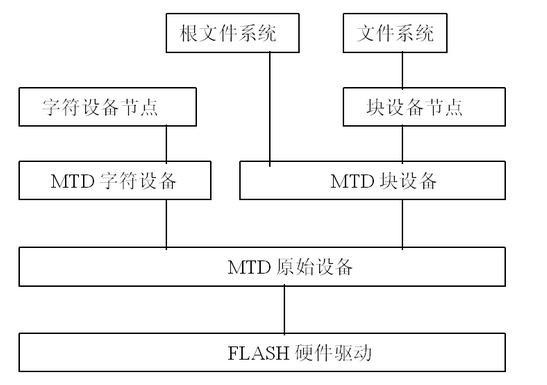
MTD设备层、MTD原始设备层和Flash硬件驱动层之间的接口关系如下图:
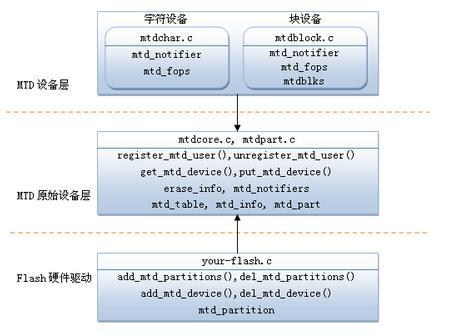
2、几个重要的数据结构:
/* Parse the contents of the file, which looks like: */
cat /proc/mtd
dev: size erasesize name
mtd0: 00400000 00100000 "logo"
mtd1: 01e00000 00100000 "cache"
mtd2: 00100000 00100000 "misc"
mtd3: 00700000 00100000 "kernel"
mtd4: 0b400000 00100000 "system"
mtd5: 10e00000 00100000 "userdata"
mtd6: 01300000 00100000 "factorydata"
mtd7: 00100000 00100000 "blackbox"
打开 "/proc/mtd" 文件即可解析出MTD分区信息,从这里可以知道MTD数目,SIZE,擦写块大小及DEV NAME
ls -l /dev/mtd/mtd* [partition_info]
crw------- root root 90, 15 1970-01-01 08:00 mtd7ro
crw------- root root 90, 14 1970-01-01 08:00 mtd7
crw------- root root 90, 13 1970-01-01 08:00 mtd6ro
crw------- root root 90, 12 1970-01-01 08:00 mtd6
crw------- root root 90, 11 1970-01-01 08:00 mtd5ro
crw------- root root 90, 10 1970-01-01 08:00 mtd5
crw------- root root 90, 9 1970-01-01 08:00 mtd4ro
crw------- root root 90, 8 1970-01-01 08:00 mtd4
crw------- root root 90, 7 1970-01-01 08:00 mtd3ro
crw------- root root 90, 6 1970-01-01 08:00 mtd3
crw------- root root 90, 5 1970-01-01 08:00 mtd2ro
crw------- root root 90, 4 1970-01-01 08:00 mtd2
crw------- root root 90, 3 1970-01-01 08:00 mtd1ro
crw------- root root 90, 2 1970-01-01 08:00 mtd1
crw------- root root 90, 1 1970-01-01 08:00 mtd0ro
crw------- root root 90, 0 1970-01-01 08:00 mtd0
可看出每个mtd设备有两个:一个是RW设备,另一个的RO,一般使用不带ro后缀的设备
mtd_info数据结构
struct mtd_info_user {
unsigned char type; //内存技术类型,例如MTD_RAM,MTD_ROM,MTD_NORFLASH,MTD_NAND_FLASH,MTD_PEROM等
unsigned long flags; //标志位
unsigned long size; // Total size of the MTD//MTD设备的大小
unsigned long erasesize; //最小的擦除块大小
unsigned long writesize; //编程块大小
unsigned long oobsize; // Amount of OOB data per block (e.g. 16)//oob(Out of band)块大小
unsigned long ecctype; // Available OOB bytes per block//每块的可用的oob字节
unsigned long eccsize;
};
#define MEMGETINFO _IOR('M', 1, struct mtd_info_user)
sprintf(MTD_DevName, "/dev/mtd/mtd%d", i);
可以open(MTD_DevName,O_RDWR)设备,利用ioctl(fd, MEMGETINFO, &mtdinfo);获取MTD信息
根据以上可以换算得到某个分区的起始地址及终止地址
//分区结构信息
struct mtd_part {
struct mtd_info mtd;//mtd_info数据结构,会被加入mtd_table中
struct mtd_info *master;//该分区的主分区
uint64_t offset;//该分区的偏移地址
struct list_head list;//分区链表
};
mtd_partition描述mtd具体分区结构
struct mtd_partition {
char *name; /* identifier string 分区名*/
uint64_t size; /* partition size 分区大小*/
uint64_t offset; /* offset within the master MTD space 偏移地址*/
uint32_t mask_flags; /* master MTD flags to mask out for this partition */
struct nand_ecclayout *ecclayout; /* out of band layout for this partition (NAND only)*/
};
ls -l /dev/block/ [mount_partition]
brw------- root root 31, 7 1970-01-01 08:00 mtdblock7
brw------- root root 31, 6 1970-01-01 08:00 mtdblock6
brw------- root root 31, 5 1970-01-01 08:00 mtdblock5
brw------- root root 31, 4 1970-01-01 08:00 mtdblock4
brw------- root root 31, 3 1970-01-01 08:00 mtdblock3
brw------- root root 31, 2 1970-01-01 08:00 mtdblock2
brw------- root root 31, 1 1970-01-01 08:00 mtdblock1
brw------- root root 31, 0 1970-01-01 08:00 mtdblock0
这里一般用于mount结点使用,不同的文件系统使用
3、读写数据及擦写数据
基本上就是利用lseek/write/read进行操作数据,需要注意是坏块及oob数据的处理并且按照块设备操作逻辑即可。
4、坏块情况
1.为什么会出现坏块
由于NAND Flash的工艺不能保证NAND的Memory Array在其生命周期中保持性能的可靠,因此,在NAND的生产中及使用过程中会产生坏块。坏块的特性是:当编程/擦除这个块时,会造成Page Program和Block Erase操作时的错误,相应地反映到Status Register的相应位。
2.坏块的分类
总体上,坏块可以分为两大类:(1)固有坏块:这是生产过程中产生的坏块,一般芯片原厂都会在出厂时都会将每个坏块第一个page的spare area的第6个byte标记为不等于0xff的 值。(2)使用坏块:这是在NAND Flash使用过程中,如果Block Erase或者Page Program错误,就可以简单地将这个块作为坏块来处理,这个时候需要把坏块标记起来。为了和固有坏块信息保持一致,将新发现的坏块的第一个page的 spare area的第6个Byte标记为非0xff的值。
3.坏块管理
根据上面的这些叙述,可以了解NAND Flash出厂时在spare area中已经反映出了坏块信息,因此, 如果在擦除一个块之前,一定要先check一下第一页的spare area的第6个byte是否是0xff,如果是就证明这是一个好块,可以擦除;如果是非0xff,那么就不能擦除,以免将坏块标记擦掉。 当然,这样处理可能会犯一个错误―――“错杀伪坏块”,因为在芯片操作过程中可能由于 电压不稳定等偶然因素会造成NAND操作的错误。但是,为了数据的可靠性及软件设计的简单化,还是需要遵照这个标准。
可以用BBT:bad block table,即坏块表来进行管理。各家对nand的坏块管理方法都有差异。比如专门用nand做存储的,会把bbt放到block0,因为第0块一定是好 的块。但是如果nand本身被用来boot,那么第0块就要存放程序,不能放bbt了。 有的把bbt放到最后一块,当然,这一块坚决不能为坏块。 bbt的大小跟nand大小有关,nand越大,需要的bbt也就越大。
需要注意的是:OOB是每个页都有的数据,里面存的有ECC(当然不仅仅);而BBT是一个FLASH才有一个;针对每个BLOCK的坏块识别则是该块第一页spare area的第六个字节。
4.坏块纠正
ECC: NAND Flash出错的时候一般不会造成整个Block或是Page不能读取或是全部出错,而是整个Page(例如512Bytes)中只有一个或几个bit出 错。一般使用一种比较专用的校验——ECC。ECC能纠正单比特错误和检测双比特错误,而且计算速度很快,但对1比特以上的错误无法纠正,对2比特以上的 错误不保证能检测。
ECC一般每256字节原始数据生成3字节ECC校验数据,这三字节共24比特分成两部分:6比特的列校验和16比特的行校验,多余的两个比特置1。(512生成两组ECC,共6字节)
当往NAND Flash的page中写入数据的时候,每256字节我们生成一个ECC校验和,称之为原ECC校验和,保存到PAGE的OOB (out- of-band)数据区中。其位置就是eccpos[]。校验的时候,根据上述ECC生成原理不难推断:将从OOB区中读出的原ECC校验和新ECC校验 和按位异或,若结果为0,则表示不存在错(或是出现了ECC无法检测的错误);若3个字节异或结果中存在11个比特位为1,表示存在一个比特错误,且可纠 正;若3个字节异或结果中只存在1个比特位为1,表示OOB区出错;其他情况均表示出现了无法纠正的错误。

