REST与Web2.0(一):Ajax 和REST 第一部分
Ajax/REST 架构风格对于融入式 Web 应用程序的优点
简介:
服务器端 Web 应用程序因采用富应用程序模型和交付个性化内容而具备了融入式(immersive) 的特点,这种特点越突出,应用程序架构对 Web 架构风格 REST(Representational State Transfer)的违背就越多。这种违背会降低应用程序的可伸缩性,增加系统复杂性。通过与 REST 相互协调,Ajax 架构将使融入式 Web 应用程序消除这些负面影响,尽享 REST 那些出色的特性
在短短 15 年中,World Wide Web 已经从一项研究实验成长为现代社会的技术支柱。最初发明 Web 的目的是使人们可以轻松发布和链接信息,现在它已经发展为软件应用程序的可行平台。但随着应用程序通过使用富应用程序模型和生成个性化内容而获得了更多的融入性,它们的架构对 Web 架构风格 REST(Representational State Transfer)的违背也越来越多。这种违背会降低应用程序的可伸缩性,增加系统复杂性。
新兴的 Ajax Web 客户机架构风格让融入式 Web 应用程序与 REST 架构风格协调一致。使它们可以尽享 REST 那些出色的特性,同时又消除了应用程序违背 REST 准则时带来的不良特性。本文将介绍为融入式 Web 应用程序成功结合 Ajax 和 REST 的方法与原因。
REST:Web 架构
尽管 World Wide Web 是在数十年的相关研究基础上建立起来的,但它的有效诞生日期是 1990 年 12 月,当时 Tim Berners-Lee 完成了 Web 主要组件的工作原型:统一资源标识符(URI)、HTTP、HTML、浏览器和服务器。Web 被迅猛采用,远远超过了先驱者们的预期。在 Roy Fielding 最出名的系列文章中(请参看 参考资料),他描述了自己当时的心情:
“尽管对其成功感到兴奋不已,但是 Internet 开发者社区逐渐开始担心,Web 使用的这种快速增长,以及早期 HTTP 的一些拙劣的网络特性,会快速压倒 Internet 基础设施所能承担的容量,从而导致突然的崩塌。”
“一种架构在设计时就应该考虑到一组特性,让它可以满足甚至超越系统的需求。忽略这些特性可能会导致后期变更干扰整个架构,就像是使用一扇落地窗去取代承重墙会破坏整个建筑结构的可靠性。” ―― Roy Fielding
Fielding 和其他人对 Web 架构及其是否能够足以支持各种扩展和用法重新进行了审视。这种重新审视的有形结果包括更新诸如 URI 和 HTTP 之类的一些重要标准。这种重新审视还获得了一些无形但却非常有意义的结果:为超级媒体应用程序确定了一种新的架构风格,Fielding 将其命名为 REST(Representational State Transfer)。Fielding 断言,使用且符合 REST 设计约束的 Web 上部署的组件可以充分利用 Web 的有用特性。他还警告说,违背 REST 准则的 Web 组件都将无法利用这些优点。
早期时,大部分 Web 站点和简单的 Web 应用程序实际上都是遵守 REST 准则的。但是随着融入式 Web 应用程序的日益普及,Web 应用程序架构逐渐开始背离 REST 准则了,此后因果循环,情况日益恶化。融入式服务器端 Web 架构的问题很难分析清楚,因为在使用这种架构风格的十年中,已经建立起这样一种信仰:这些问题都是 Web 应用程序架构所固有的。实际上,这并非是 Web 应用程序架构的问题。而是由服务器端 Web 应用程序架构风格所产生的问题。要打破这种偏见,我们来回顾一下整个架构是如何发展到现在这种状态的,这会很有帮助。我们将说明为什么在 Ajax 应用程序创建在商业上可行之后,过去接受的很多假设现在都不再成立了。
Web 应用程序的简史
Berners-Lee 创造了 Web,最初是将 Web 作为研究人员远程共享文档和在文档之间创建简单链接以加速知识和思想传播的一种手段。然而,URI 标准的架构特征很快实现了除静态文件之外更多内容的共享。
提供静态文档的 Web 站点
Web 上最早的内容由一些静态 HTML 文档组成,其中有很多到其他静态文档的链接,如图 1 所示:
图 1. 提供静态文档的 Web 站点
REST 使静态文档的检索极其高效、可伸缩,这是因为它们可以根据 URI 和最后修改日期来轻松缓存。很快开发人员就超越了静态文档的领域,开始动态文档的提供。
早期的动态 Web 应用程序
Berners-Lee 和其他人设计了 URI 标准,为资源的统一唯一标识提供支持,同时使其表示(HTML、文本等)根据 Web 客户机(通常是 Web 浏览器)和 Web 服务器之间的协商结果而变化。由于 URI 将资源标识和资源的底层存储机制区分开来,因此 Web 开发人员可以创建一些程序,使之检查 URI 语法,并动态生成文档,将预先定义的 UI 元素和动态检索的数据(通常是从关系数据库中)合并在一起,如图 2 所示。尽管这些文档是生成的,但是它们的缓存特征与静态文件的完全相同。
图 2. 以嵌入 HTML 模板代码形式提供数据库记录的 Web 站点
此类早期应用程序的一个简单例子是统一目录 Web 应用程序。这种应用程序通常以如下方式工作:
1 用户在 Web 表单中输入名字(例如,Bill Higgins),并单击提交按钮。
2 表单根据输入的名字创建一个 URI,并从服务器上请求这个 URI 的内容(例如 GET http://psu.edu/Directory/Bill+Higgins)。
3 服务器检查这个 URI,并使用这个学生的电话号码和地址来生成一个 Web 页面。
4 服务器将所生成的页面发回到用户的浏览器上。
这种交互的一个重要特性是它是幂等的(idempotent),也就是说除非底层资源发生变化(例如 Bill 修改了自己的电话号码),否则同一请求的结果总是相同的。这意味着浏览器或代理服务器都可以在本地对 Bill Higgins 的文档进行缓存,只要底层资源没有发生变化,那就可以从本地缓存中检索资源,而不再需要从远程服务器检索。这种方法能提高用户感受到的响应性,并增加系统整体效率和可伸缩性。这些早期的动态 Web 应用程序可以很好地工作,将大量的信息送至用户指尖。
融入式 Web 应用程序
下一代 Web 应用程序的目标就是高度融入,提供个性化的内容和富应用程序模型。在过去十年中,Web 开发人员成功创建了这些融入式应用程序。一个非常恰当的例子是 Amazon.com 电子商务站点。当用户与 Amazon Web 应用程序进行交互时,它会创建复杂的客户页面来推荐有针对性的商品,显示浏览历史记录,并显示用户购物车中商品的价格。
融入式服务器端应用程序和 REST
融入式 Web 应用程序确实非常有用,但服务器端的融入式 Web 应用程序风格从根本上来说是不符合 REST 架构准则的。具体来说,它违背了一项关键的 REST 约束,并且没有利用 REST 最为重要的一些优点,因此又产生了一组新问题
违背了 “无状态服务器” 约束
REST 的 “客户机-无状态-服务器” 约束禁止在服务器上保存会话状态。符合这一约束进行设计可以提高系统的可见性、可靠性和可伸缩性。但是融入式服务器端 Web 应用程序希望能够为单个用户提供大量个性化内容,因此必须在两种设计之间作出选择。第一种设计要在每个客户机请求中都发送大量状态信息,因此每个请求都完整地保留了上下文的内容,服务器是无状态的。第二种解决方案表面上来看比较简单,应用程序开发人员和中间件供应商都比较倾向于这种方法,它只是简单地发送一个用户标识,并在服务器端为这个标识关联一个 “用户会话”(如图 3 所示)。第二种设计直接违背了客户机-无状态-服务器约束。尽管它确实可以实现我们想要的用户功能(具体来说就是指个性化),但却对这个架构进行了极大的改动
图 3. 融入式服务器端 Web 应用程序,其中包含了大量服务器端会话状态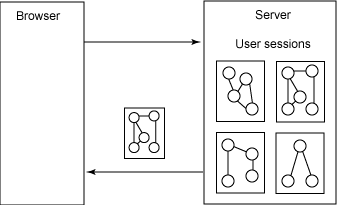
Java? Servlet 的 HttpSession API 正是一个此类变动的例子。HttpSession 让我们可以在状态和特定用户之间建立关联。这个 API 看起来对于开发新手非常简单。实际上,它似乎可以将任何对象保存到 HttpSession 中,并且不需要自己实现任何特定的查找逻辑就可以将这些对象取出来。但是当我们开始在 HttpSession 中放入更多对象时,就会开始注意到我们的应用服务器要占用的内存和处理资源越来越多。很快我们就确定自己需要将应用程序部署到集群环境中来应对日益增加的资源需求。然后就会认识到,要让 HttpSession 在集群环境中工作,每个对象都必须实现 Java 的 Serializable 接口,以使会话数据能够在集群环境中的服务器间传递。然后必须确定应用服务器在关机/重启过程中是否要继续维护会话数据。很快您就会质疑,违背客户机-无状态-服务器约束是否真的是一个好主意。(实际上,很多开发人员都不了解这个约束。)
使分布式缓存变为不可能
融入式服务器端 Web 应用程序的第二个严重后果在于:它实际上不能利用 REST 的第一类支持进行资源缓存。引用 Fielding 的话来说,“添加缓存约束的优点是可以部分或完全避免某些交互操作,从而可以通过减少一系列交互的平均延迟来提高效率、可伸缩性以及用户可以感受到的性能。不过这样做的代价是如果缓存中的陈旧数据与通过将请求直接发送给服务器而获得的数据有很大区别,那么缓存的可靠性就降低了。”
我们可以将融入式 Web 应用程序近似地看作一个活动实体,它会根据用户提供的新输入内容、其他人输入的新内容以及新的后台数据而不断发生变化。由于服务器必须根据多个用户与应用程序的交互来生成每个页面,因此我们实际上无法两次生成相同的文档。因此,Web 浏览器或代理服务器无法缓存服务器资源。
有几种解决方案可以用来处理资源无法缓存的问题。一种就是创建细粒度的资源在服务器端的缓存,这样服务器就可以通过预先组合好的部分来构建一个粗粒度的页面,而不是通过基本元素(HTML 和数据)从头开始一步步地构建这种页面了。但是问题依然存在:每个请求都会导致大量的服务器处理,这会损害系统的可伸缩性,还可能会对用户感受到的响应性造成负面影响。
无法提供可缓存资源的另外一个结果是:动态程度相当高的 Web 应用程序必须显式地禁止搜索引擎和其他类型的 “机器人”作出请求,因为处理这类请求的成本都非常昂贵;而在符合 REST 准则的应用程序中,只需一次性地将某个资源提供给那一类 “机器人”,然后对它们的后续访问发送一条简单的 “Not-modified” 消息即可。
但是为什么要在一个负载过重的服务器上集中这么多的资源消耗呢?从理论上来说,我们什么时候可以将处理和内存需求分布到客户机呢?简单的答案是给定传统 Web 浏览器约束,这是不可行的(请参看 不使用 Ajax 的客户端处理)。但是 Ajax 架构风格使开发人员可以将处理和状态需求分布到客户机。请继续阅读,学习为什么选择使用 Ajax 风格的融入式应用程序可以继续遵循 REST 准则,并充分利用它的优势。
Ajax 和 REST
正如我们前面看到的一样,传统的服务器端 Web 应用程序将数据的标识和服务器上的动态数据元素合并在了一起,并将所构成的完整 HTML 文档返回给浏览器。Ajax 应用程序在其主要 UI 和浏览器中的主要逻辑方面有所不同;基于浏览器的应用程序代码可以在必要时获取新的服务器数据,并将这些数据织入当前页面(请参看 参考资料 中 Jesse James Garrett 有关 Ajax 的启蒙文章)。呈现和数据绑定的位置看起来可能是一个实现细节,但是这种区别会导致完全不同的架构风格
利用有状态 Web 客户机的优点
人们通常将 Ajax 应用程序描述成无需在每次点击时彻底地刷新整页的 Web 页面。尽管这个描述非常确切,但是根本的动机在于彻底刷新整页会令用户不耐烦,从而无法获得愉快、融入式的用户体验。从架构的角度来看,整个页面全部刷新的设计甚至非常危险,这种设计使您无法选择在客户机存储应用程序状态,这可能会导致妨碍应用程序充分利用 Web 最强大的架构设计点的设计决策。
Ajax 让我们不需要进行完全刷新就可以与服务器进行交互,这一事实使有状态客户机再次成为可用选择。这一点对于动态融入式 Web 应用程序架构的可能性有深远的影响:由于应用程序资源和数据资源的绑定转换到了客户端,因此这些应用程序都可以享受这两个世界中最好的东西 ―― 融入式 Web 应用程序中动态、个性化的用户体验,以及遵守 REST 准则的应用程序中简单、可伸缩的架构。
缓存 Ajax 引擎
设想一下,将 Amazon.com 彻底重新实现为一个 Ajax 应用程序 ―― 一个 Web 页面可以从服务器上动态获取所有的数据。(出于商业原因,Amazon 可能并不希望这样做,不过那是其他文章讨论的话题了。)由于现在有很多 UI 和应用程序逻辑都可以在客户机而不是在服务器上运行,根据 Garrett 的说法,最初加载页面时需要下载 Amazon 的 Ajax “引擎”。这个引擎包含大量应用程序逻辑(以 JavaScript 代码实现),另外还有此后将使用从服务器上异步获取的数据填充的 UI 框架(见图 4):
图 4. 融入式 Ajax 应用程序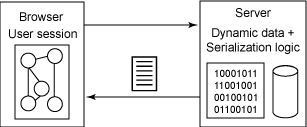
Ajax 引擎一个有趣的特征就是:尽管它包含了很多应用程序逻辑和表示框架元素,但是如果经过恰当的设计,它可以不包含任何业务数据或个性化内容。应用程序和表示都冻结在部署时。在典型的 Web 环境中,应用程序资源可能 6 个月才会变更一次。这意味着负责隔离应用程序资源和数据资源的 Ajax 引擎是高度可缓存的
Dojo Toolkit 就是一个很好的例子(请参看 参考资料)。Dojo 提供了构建时工具来创建一个包含所有应用程序逻辑、表示和风格的压缩 JavaScript 文件。由于它终究只是一个文件,因此 Web 浏览器可以对其进行缓存,这意味着我们第二次访问启用 Dojo 的 Web 应用程序时,很可能就会从浏览器缓存中加载 Ajax,而不是从服务器上加载它。我们可以将这种情况与高度融入化的服务器端 Web 应用程序进行一下对比,后者每次请求都会导致大量的服务器处理,因为浏览器和网络中介不能对缓存不断变化的资源。
由于 Ajax 应用程序引擎只是一个文件,因此它也是可以使用代理缓存的。在大型的企业内部网中,只要有一名员工曾经下载过某个特定版本的应用程序的 Ajax 引擎,其他任何人都可以从内部网网关上上获取一个缓存过的拷贝。
因此对于应用程序资源来说,经过良好定义的 Ajax 应用程序引擎符合 REST 准则,与服务器端 Web 应用程序相比,它具有显著的可伸缩性优势。
缓存 Ajax 数据
用户浏览一个 Ajax Web 站点,加载 Ajax 应用程序引擎,最好是从浏览器缓存中加载的,否则就从本地代理服务器加载。那么对于业务数据来说情况如何呢?由于应用程序逻辑和状态都在浏览器上驻留并执行,因此应用程序与服务器的交互就与传统 Web 应用程序的方式有很大的不同。不需要获取混合的内容页面,只需要获取业务数据即可。
现在回到 Amazon.com 的例子上来,假设我们点击了一个链接,要查看有关设计模式的一本书籍。在 Amazon.com 目前的应用程序中,链接点击操作会发送很多标识所请求的资源的信息。它还会发送很多会话状态信息,这让服务器可以创建一个新页面,其中可以包括之前的状态(例如最近查看的内容)、个性化信息(例如您在 1999 年购买的书籍)以及实际的业务资源本身。应用程序是动态且高度个性化的 ―― 但是却不能缓存,也无法伸缩(正如 Amazon 所示范的一样,这些架构问题都可以通过投入大量资金构建基础设施来克服)。现在我们考虑一下这个操作在(假想的)Ajax 版本的应用程序中的情况。对于 “最近查看的内容” 并不需要进行处理。当我们点击某个链接时,这些在页面上已经存在的信息并不会消失。有两个请求很可能会与设计模式的书籍有关:
/Books/0201633612(其中 0201633612 是设计模式书的 ISBN 号)
/PurchaseHistory/0201633612/bhiggins@us.ibm.com
第一个假定的请求会返回有关书籍的信息(作者、标题、简介等);其中并没有包含特定于用户的数据。特定于用户的数据意味着当更多用户请求相同的资源时,很可能会从 Internet 上的中间节点上来检索缓存版本,而不是从原始服务器上检索这些资源。这种特性会降低服务器和总体网络负载。另外一方面,第二个请求包含了特定于用户的信息(Bill Higgins 的购买该书的历史记录)。由于这些数据包括一些个性化信息,因此只有一名用户需要从这个 URI 中获取并缓存数据。尽管这种个性化数据并没有非个性化数据的可伸缩特性,但是重要的问题是这些信息都是直接从 URL 中获取的,因此都具有这样的正面特征:它们都不会妨碍其他可缓存的应用程序和数据资源的缓存。
Ajax 和健壮性
Ajax 架构风格的另外一个优点是它可以轻松处理服务器的故障。正如我们前面介绍的一样,具有融入式用户体验的服务器端 Web 应用程序通常会在服务器上保存大量的用户会话状态。如果服务器发生了故障,会话状态就丢失了,那么用户就会体验到非常奇怪的浏览器行为(“为什么我又回到主页上来了?我的购物车中的东西都到哪里去了?”)。在采用有状态客户机和无状态服务的 Ajax 应用程序中,服务器崩溃/重新启动对于用户来说都是完全透明的,因为服务器崩溃不会影响会话状态,这些都保存在用户的浏览器中;无状态服务的行为是幂等的,可以由用户请求的内容来单独确定。
from: http://www.ibm.com/developerworks/cn/web/wa-ajaxarch/