XML解析方式
XML解析方式
XML(Extensible Markup Language)即可扩展标记语言,它与HTML一样,都是SGML(Standard Generalized Markup Language,标准通用标记语言)。Xml是Internet环境中跨平台的,依赖于内容的技术,是当前处理结构化文档信息的有力工具。扩展标记语言XML是一种简单的数据存储语言,使用一系列简单的标记描述数据,而这些标记可以用方便的方式建立。XML已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便。XML的解析方式基本上分为三类:第一类是基于XML文档树结构的解析,例如DOM(Document Object Model);第二类是基于流式的解析,例如SAX(Simple API for XML)、StAX(Stream API for XML)和XPP(XML Pull Parser);第三类是基于非提取式的解析,例如VTD-XML(Virtual Token Description for XML)。
1 DOMDOM是用与平台和语言无关的方式表示诸如XML和HTML文档的W3C(万维网联盟) 官方推荐标准。它定义了所有文档元素的对象和属性,以及访问它们的API接口。W3C DOM被分为3个不同的部分,核心DOM、XML DOM和HTML DOM。核心DOM用于任何结构化文档的标准模型;XML DOM用于XML的标准对象模型和标准编程接口;HTML DOM用于HTML文档的标准模型。
DOM是以层次结构组织的节点或信息片断的集合。这个层次结构允许开发人员在树中寻找特定信息。分析该结构通常需要加载整个文档和构造层次结构,然后才能做任何工作。由于它是基于信息层次的,因而DOM被认为是基于树或基于对象的。
优点:易用性强,由于树在内存中是持久的,因此可以修改它以便应用程序能对数据和结构作出更改,它还可以在任何时候在树中上下导航。
缺点:效率低,解析速度慢,内存占用量过高,对于大文件来说几乎不可能使用。另外效率低还表现在大量的消耗时间,因为使用DOM进行解析时,将为文档的每个element、attribute、processing-instruction和comment都创建一个对象,这样在DOM机制中所运用的大量对象的创建和销毁无疑会影响其效率。
2 SAXSAX是基于事件驱动的推式解析方式。它并不是W3C的官方标准,而是业界事实上的标准。SAX解析的基本原理是把元素开始、元素结束、文本、文档的开始或结束等当成一个事件,当解析器遇到这些事件时,就发送请求给事件处理接口进行处理。事件处理接口的具体实现是程序员编写的事件处理响应代码。SAX解析的基本原理如下图:
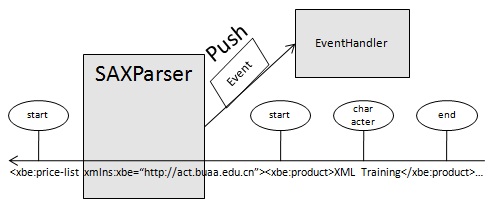
SAX处理的优点非常类似于流媒体的优点。分析能够立即开始,而不是等待所有的数据被处理。由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。事实上,应用程序甚至不必解析整个文档;它可以在某个条件得到满足时停止解析。一般来说,SAX还比它的替代者DOM快许多。
选择DOM还是选择SAX? 对于需要自己编写代码来处理XML文档的开发人员来说, 选择DOM还是SAX解析模型是一个非常重要的设计决策。DOM采用建立树形结构的方式访问XML文档,而SAX采用的事件模型。
DOM解析器把XML文档转化为一个包含其内容的树,并可以对树进行遍历。用DOM解析模型的优点是编程容易,开发人员只需要调用建树的指令,然后利用navigation APIs访问所需的树节点来完成任务。可以很容易的添加和修改树中的元素。然而由于使用DOM解析器的时候需要处理整个XML文档,所以对性能和内存的要求比较高,尤其是遇到很大的XML文件的时候。由于它的遍历能力,DOM解析器常用于XML文档需要频繁的改变的服务中。
SAX解析器采用了基于事件的模型,它在解析XML文档的时候可以触发一系列的事件,当发现给定的tag的时候,它可以激活一个回调方法,告诉该方法制定的标签已经找到。SAX对内存的要求通常会比较低,因为它让开发人员自己来决定所要处理的tag.特别是当开发人员只需要处理文档中所包含的部分数据时,SAX这种扩展能力得到了更好的体现。但用SAX解析器的时候编码工作会比较困难,而且很难同时访问同一个文档中的多处不同数据。
优点:所有的SAX处理都在一次遍历中完成的;因此,在解析同等大小的文档时SAX通常会相比DOM提供更好的性能(因为DOM必须遍历树结构)。此外,与DOM是比,因为在给定的时间之内只需要XML文档的一部分装入内存,所以SAX通常在处理更大文件时内存的利用效率也来得更高(DOM在开始解析文档之前必须把全部XML文档装入内存)。
缺点: SAX应用程序一般都比较长,程序中充斥着大量的if/else结构用来确定处理特定元素时所采用的运动。同样的,处理多个XML元素之间散布的数据结构也很成问题,因为解析事件之间必须保存中间数据。SAX应用程序的事件处理结构一般意味着SAX应用程序是针对特定文件结构定制构建的,而DOM应用程序则更具一般性。
3 StAXStAX是基于事件流的拉式是解析方式,与SAX不同之处在于 StAX 允许应用程序代码把这些事件逐个拉出来,而不用提供在解析器方便时从解析器中接收事件的处理程序。
StAX 实际上包括两套处理 XML 的 API,分别提供了不同程度的抽象。基于指针的 API 允许应用程序把 XML 作为一个标记(或事件)流来处理;应用程序可以检查解析器的状态,获得解析的上一个标记的信息,然后再处理下一个标记,依此类推。这是一种低层 API,尽管效率高,但是没有提供底层 XML 结构的抽象。较为高级的基于迭代器的 API 允许应用程序把 XML 作为一系列事件对象来处理,每个对象和应用程序交换 XML 结构的一部分。应用程序只需要确定解析事件的类型,将其转换成对应的具体类型,然后利用其方法获得属于该事件的信息。
StAX 所采用的基于拉的方法和其他方法相比有一些突出的优点。首先,不管使用哪种 API 风格,都是应用程序调用读取器(解析器)而不是相反。通过保留解析过程的控制权,可以简化调用代码来准确地处理它预期的内容。或者发生意外时停止解析。此外,由于该方法不基于处理程序回调,应用程序不需要像使用 SAX 那样模拟解析器的状态。
StAX 仍然保留了 SAX 相对于 DOM 的优点。通过把重心从结果对象模型转移到解析流本身,从理论上说应用程序能够处理无限的 XML 流,因为事件固有的临时性,不会在内存中累积起来。对于那些使用 XML 作为消息传递协议而非表示文档内容的那些应用程序尤其重要,比如 Web 服务或即时消息应用程序。比方说,如果只是将其转换成特定于应用程序的对象模型然后就将其丢弃,那么为 Web 服务路由器 servlet 提供一个 DOM 就没有多少用处。使用 StAX 直接转化成应用程序模型效率更高。对于 Extensible Messaging and Presence Protocol(XMPP)客户机,根本不能使用 DOM,因为 XMPP 客户机/服务器流是随着用户输入的消息实时生成。等待流的关闭标签(以便最终建立 DOM)就意味着等待整个会话结束。通过把 XML 作为一系列的事件来处理,应用程序能够以最合适的方式响应每个事件(比如显示收到的即时消息等等)。
由于其双向性,StAX 也支持链式处理,特别是在事件层上。接收事件(无论什么来源)的能力被封装在 XMLEventConsumer(XMLEventWriter 的扩展)接口中。因此,可以模块化地编写应用程序从 XMLEventReader(也是一个普通的迭代器,可以按迭代器处理)读取和处理 XML 事件、然后传递给事件消费者(如果需要可以进一步扩展处理链)。在第 2 部分将看到,也可使用应用程序提供的筛选器(实现了 EventFilter 接口的类)来定制 XMLEventReader 或者使用 EventReaderDelegate 修饰已有的 XMLEventReader。

总而言之,和 DOM 以及 SAX 相比,StAX 使应用程序更贴近底层的 XML。使用 StAX,应用程序不仅可以建立需要的对象模型(而不需要处理标准 DOM),而且可以随时这样做,而不必等到解析器回调。
4 XPPXPP是更底层的StAX解析方式, 只能适当支持 XML 文档的子集并且不提供验证的任何支持。它同样具有尺寸小的优势。这种优势再与拉回解析器方法结合,使它成为该比较中的良好替换项。
XPP 几乎独占地使用接口,但是它仅使用所有类中的一小部分。XPP 避免使用 API 中的 Collections 类。总的来说,它是本文中最简单的文档模型 API。
将 XPP 限制成 XML 文档子集的局限性是它不支持文档中的实体、注释或处理指示信息。XPP 创建仅包含元素、属性(包括“名称空间”)和内容文本的文档结构。这对于某些类型的应用程序来说是一种非常严格的限制。
XPP 中的拉回解析器支持(本文中称为 XPP 拉回)通过将解析实际上推迟到访问文档的一个组件时才进行,然后按照构造那个组件的需要对文档进行解析。该技术想实现允许非常快速的文档显示或分类应用,尤其在需要转发或除去(而不是对文档进行完全解析和处理)文档时。该方法的使用是可选的,如果以非拉回型方式使用 XPP,它对整个文档进行解析并且同时地构建完整的表示。
XPP 使用依据文本文档构建文档表示的集成语法解析器,并且除了通过文本方式外,它不提供从 DOM(或 SAX2)转换或转换成 SAX2(或 DOM)事件流的任何方式。
当我们选择处理 XML 文件的时候,正如上面介绍的那样,大致上有DOM、SAX、StAX和XPP四种选择。虽然它们都各有其利弊,但都不是特别好的解决方案,不难看出,DOM 与 SAX(StAX、XPP)是正好相反的两个极端,它们在解析效率上都存在一定的性能瓶颈,究其原因,在于它们都是基于提取解(extractive parsing)模式。所谓的提取解析就是说在解析 XML 时,解析器会提取一部分原文件,一般来说是一个字符串,然后在内存中进行解析构建,输出自然就是一个或一些对象了。以DOM 为例,DOM 会将每一个 element,attribute, processing-instruction, comment 等等都解析成对象并给与结构,这就是所谓的提取解析。提取解析将会带来三种RoundTrip,引起性能瓶颈:
1. 对象的创建与回收。提取解析模式注定了解析器都需要大量的创建或销毁对象,引起效率问题。
2. 编码与解码。无论是何种解析方法都需要能够处理 XML 的编码,也就是说,在读取的时候解码,在写入的时候编码。
3. Tokenize和Untokenize。无论是何种解析方法,都会将其中的Token输出为字符串以提供给应用程序,应用程序修改完毕,又将其字符untokenize成原始数据类型。
因此,在 DOM 或者SAX 、StAX和XPP的对象模型中,当每一次需要做改动时,我们要做的就是将对象的信息再解析回 XML 的字符串,注意这个解析是个完整的解析,也就是说,原文件并没有被利用,而是直接将对象模型重新完整解析成 XML 字符串。换句话讲,它们并不支持增量更新,而在这过程中,有很多不是应用程序所关心的,因而增加了不必要的性能开销。
总而言之, DOM、SAX、StAX和XPP的效率问题主要出在它的提取解析模式上, VTD-XML[25](Virtual Token Descriptor虚拟令牌描述符)便是对以上问题的思考后给出的答案,它是一个非提取的 XML解析器,由于它出色的机制,很好的解决了上面所提出的各种问题,并且还带来了非提取的其他好处,像快速的解析与遍历、对 XPath 的支持、增量更新等等。一条VTD记录的比特层格式如下所示:
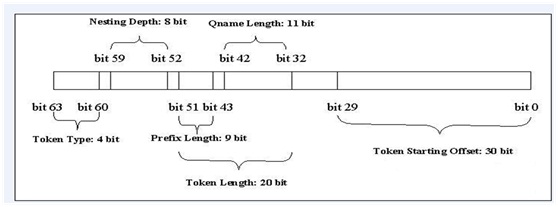
图8 VTD比特层格式
各字段的描述如下:
·开始偏移量:30bits(b29~b0)最大值是 2^30-1 = 1G-1;
·长度:20bits(b51~b32)最大值是 2^20-1 = 1M-1;
其中前缀长度:9bits(b51~b43)最大值是 511;
序列名长度:11bits(b42~b32)最大值是 1023;
·深度:8bits(b59~b52)最大值是 255;
·令牌类型:4bits(b63、b60);
·保留:2bits(b31、b30)。
由此可见VTD 是 64bits 固定长度的,这样做的目的就是为了提高性能,因为长度固定,在读取,查询等操作的时候格外的高效,也就是可以用数组这种高效的结构来组织 VTD,这大大减少了因为大量使用对象而产生的性能问题。