用 IBM WebSphere DataStage 进行数据整合:第 1 部分
?
原文地址:http://www.ibm.com/developerworks/cn/data/library/techarticles/dm-0602zhoudp/
数据整合的核心内容是从数据源中抽取数据,然后对这些数据进行转化,最终加载的目标数据库或者数据仓库中去,这也就是我们通常所说的 ETL 过程。IBM WebSphere DataStage 为整个 ETL 过程提供了一个图形化的开发环境。
引言
传统的数据整合方式需要大量的手工编码,而采用 IBM WebSphere DataStage 进行数据整合可以大大的减少手工编码的数量,而且更加容易维护。数据整合的核心内容是从数据源中抽取数据,然后对这些数据进行转化,最终加载的目标数据库或者数据仓库中去,这也就是我们通常所说的ETL过程。IBM WebSphere DataStage 为整个 ETL 过程提供了一个图形化的开发环境。本文将从以下几个方面来介绍 IBM WebSphere DataStage:
1. 数据源连接能力
2. 完备的开发环境
3. ETL Job 的并行执行能力
4. 开发一个简单的 ETL Job
出色的数据源连接能力
数据整合工具的数据源连接能力是非常重要的,这将直接决定它能够应用的范围。IBM WebSphere DataStage 能够直接连接非常多的数据源,包括:
1、 文本文件
2、 XML 文件
3、 企业应用程序,比如 SAP、Siebel、Oracle 以及PeopleSoft
4、 几乎所有的数据库系统,比如 DB2、Oracle、SQL Server、Informix等
5、 Web services
6、 WebSphere MQ
正是因为这么好的连接能力,IBM WebSphere DataStage 使用户能够专注于数据转换的逻辑而不用太担心数据的抽取和加载。
完备的开发环境
IBM WebSphere DataStage 的开发环境是基于 C/S 模式的,通过 DataStage Client 连接到DataStage Server 上进行开发。这里有一点需要注意,DataStage Client 只能安装在 Windows 平台上面。而 DataStage Server 则支持多种平台,比如 Windows、Redhat Linux、AIX、HP-UNIX。
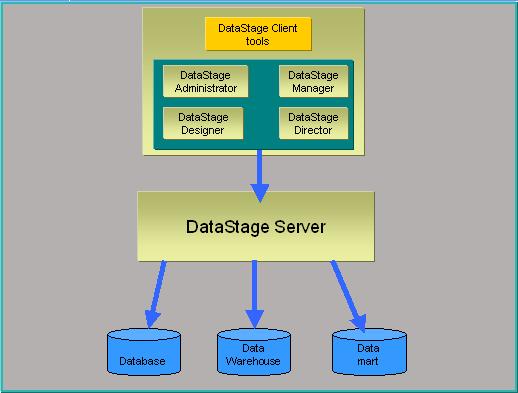
DataStage Client 有四种客户端工具。分别是 DataStage Administrator、DataStage Designer、DataStage Manager、DataStage Director。接下来首先介绍这几种客户端工具在 DataStage 架构中所处的位置以及它们如何协同工作来开发 ETL Job 的,接着再分别详细介绍每个工具的功能。
图 1 描述了 IBM WebSphere DataStage 的整个系统架构。DataStage 的客户端工具连接到DataStage Server 上进行 ETL Job 的开发,DataStage Server 再与后台的数据库连接起来进行数据处理。DataStage 的客户端工具之间的是一个相互合作的关系。下面通过介绍 ETL Job的开发过程来介绍他们之间的这种关系。
?
ETL Job开发流程
1. 用 DataStage Administrator 新建一个项目;
2. 用 DataStage Designer 连接到这个新建的项目上进行ETL Job的设计;
3. 用 DataStage Director 对设计好的ETL Job设置运行的模式,比如多长时间运行一次ETL Job;
4.用 DataStage Manager 进行ETL Job的备份等。
 ?
?DataStage Administrator
DataStage Administrator 的主要功能有以下几个:
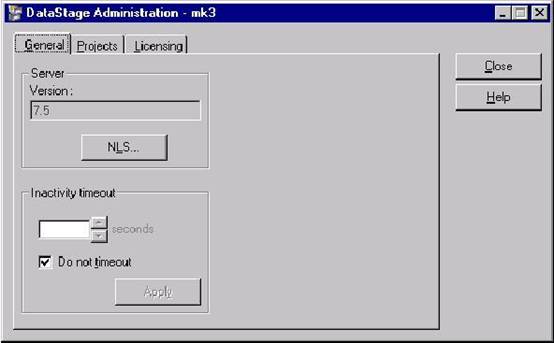
1. 设置客户端和服务器连接的最大时间。
以管理员的身份登陆 DataStage Administrator。你就会看到如下图所示的画面。在这里你可以设置客户端和服务器的最大连接时间,默认的最大连接时间是永不过期。最大连接时间的意思就是如果客户端和服务器的连接时间超过了最大连接时间,那么客户端和服务器之间的连接将被强行断开。
 ?
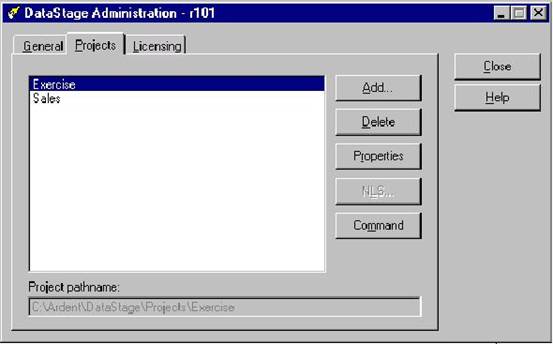
?2. 添加和删除项目
在 Projects 这个标签中,可以新建或者删除项目,以及设置已有项目的属性。这里有必要介绍一下项目的概念,要用 DataStage 进行 ETL 的开发,首先就要用 DataStage Administrator 新建一个项目,然后在这个项目里面进行 ETL Job 的开发。
 ?
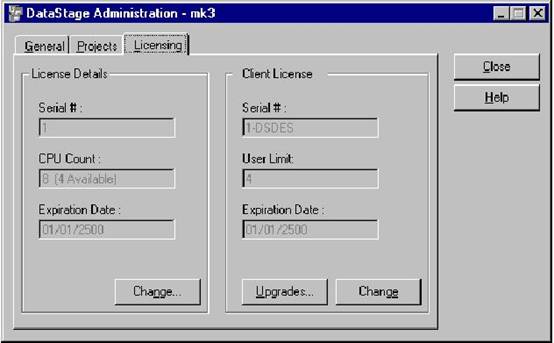
?3. License的管理
可以在Licensing标签中更新License。
 ?
?DataStage Designer
DataStage Designer是ETL Job开发的核心环境。值得注意的是,登陆DataStage Designer 的时候,不仅要指定DataStage Server 的IP,而且要指定连接到这个DataStage Server上的哪个项目上面,上面已经提到DataStage的项目是由DataStage Administrator 来创建的。DataStage Designer的主要功能可以概括为以下三个方面:
1. ETL Job的开发
DataStage Designer里面包含了DataStage为ETL开发已经构建好的组件, 主要分为两种,一种是用来连接数据源的组件,另一种是用来做数据转换的组件。利用这些组件,开发人员可以通过图形化的方式进行ETL Job的开发。
2. ETL Job的编译
开发好ETL Job后,可以直接在DataStage Designer里面进行编译。如果编译不通过,编译器会帮助开发人员定位到出错的地方。
3. ETL Job的执行
编译成功后,ETL Job就可以执行了,在DataStage Designer里面可以运行ETL Job。ETL Job的运行情况可以在DataStage Director中看到,这方面的内容将在介绍DataStage Director的时候提到。
DataStage Manager
DataStage Manager主要用来管理项目资源。一个项目可能包含多个ETL Job,可以用DataStage Manager把一个项目里面的ETL Job导出来。然后再用DataStage Manager导入到另外一个项目中去,利用这个功能一方面可以实现ETL Job的备份,另一方面就是可以在多个项目之间来重复使用开发好的ETL Job。在DataStage Manager里面可以把数据库中的表结构直接导入到项目中来,供这个项目中的所有ETL Job使用。DataStage Designer也提供了从数据库中直接导入表结构的功能。
DataStage Director
DataStage Director 主要有以下两个功能:
1. 监测ETL Job的运行状态
ETL Job在DataStage Designer中编译好后,可以通过DataStage Director来运行它。前面在介绍DataStage Designer的时候提到在DataStage Designer中也可以运行ETL Job,但是如果要监测ETL Job的运行情况还是要登陆到DataStage Director中。在这里,你可以看到ETL Job运行的详细的日志文件,还可以查看一些统计数据,比如ETL Job每秒所处理的数据量。
2. 设置何时运行ETL Job
ETL Job开发完成后,我们可能希望ETL Job在每天的某个时间都运行一次。DataStage Director为这种需求提供了解决方案。在DataStage Director中可以设置在每天、每周或者每月的某个时间运行ETL Job。
ETL Job的并行执行
ETL Job的并行执行是IBM WebSphere DataStage企业版的一大特色。ETL Job开发好以后,可以在多台装有DataStage Server的机器上并行执行,这也是传统的手工编码方式难以做到的。这样,DataStage就可以充分利用硬件资源。而且,当你的硬件资源升级的时候也不用修改已经开发好的ETL Job,只需要修改一个描述硬件资源的文件即可。并行执行能力是DataStage所能处理数据的速度可以得到趋近于线性的扩展,轻松处理大量数据
。开发一个简单的ETL Job
我们将要开发一个非常简单的ETL Job,使大家对用DataStage进行ETL开发有一个总体的认识。将要开发的ETL Job是把DB2数据库Source中的表employee的内容导入到另外一个DB2数据库Target中的表employee中去。其中两个数据库中的employee表的结构是相同的。employee表的结构为:
 ?
?这里需要说明的是,DB2数据库的Client端必须和DataStage Server装在同一台机器上面。如果要连接的DB2数据库的Server和DataStage Server不在同一台机器上面,那么就需要先用和DataStage Server装在同一台机器上的DB2的Client端提供的工具"配置助手"把要连接的数据库添加到DB2的Client端当中。这就为DataStage连接该数据库做好了准备。另外一点需要注意的是,如果你的DataStage Server是安装在Windows上的,那么做完上面所描述的事情后就可以用DataStage连接DB2数据库了,但是如果你的DataStage Server是安装在Linux或者Unix上面的,你还需要配置DataStage的一个名字叫dsenv文件。因为我们的例子当中DataStage Server是运行在Linux上面的。我们将以Linux为例讲述dsenv文件的配置方法。
?
1. 配置dsenv文件(Linux环境)
dsenv文件是主要是用来存放环境变量的,这些环境变量包含了DataStage要用到的类库,以及要连接的数据库的安装的路径等。dsenv文件位于位于文件夹 $DataStage/DSEngine里面,$DataStage/是DataStage的安装目录,例如:/home/dsadm/Ascential/DataStage/。
打开dsenv文件,在文件的最后加上如下内容:
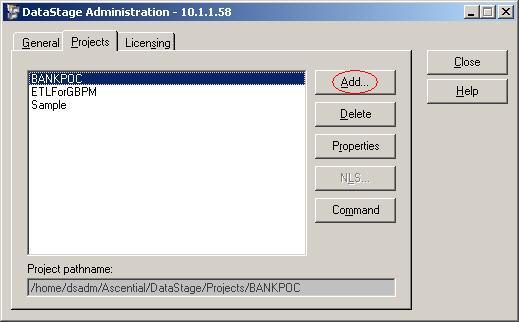
?(2)登录后,在标签Projects中可以看到目前这个DataStage Server上面所有的项目。单击按钮"Add"新建一个项目;
?
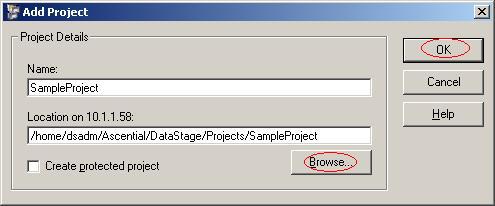
(3)在弹出的对话框中输入项目名SampleProject,项目存储的默认路径是DataStage安装路径的Projects目录下面,你可以通过单击按钮"Browse"来改变默认路径。注意不要钩上选择框"Create protected project",因为如果钩上的话你所创建的工程将没办法被改变。单击按钮"OK";
?
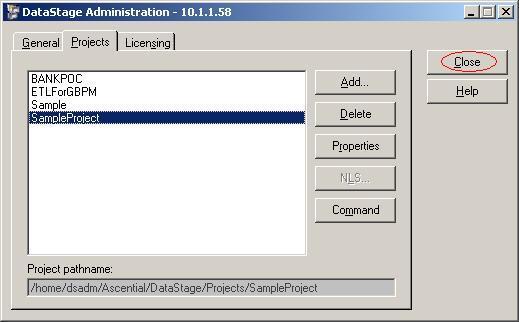
(4)你会看到在项目列表里面已经有了我们刚创建好的项目SampleProject,单击按钮"Close"关闭DataStage Administrator;
?
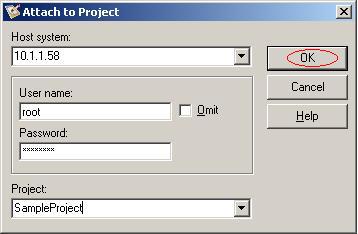
(5)用DataStage Designer登陆到DataSatge Server,输入DataStage Server的IP或主机名以及用户名和密码,并指定Project为我们刚才创建的项目SampleProject。单击按钮"OK";
?
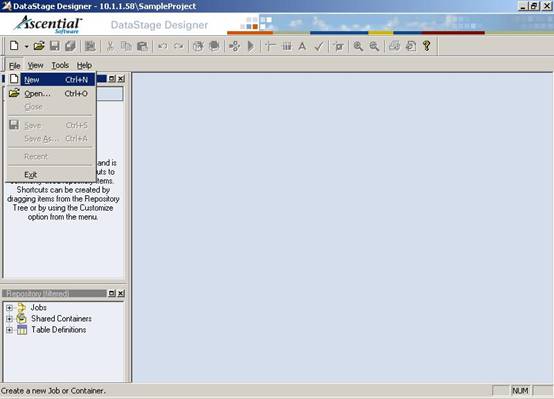
(6)在DataStage Designer当中单击File'New去创建一个新的ETL Job;
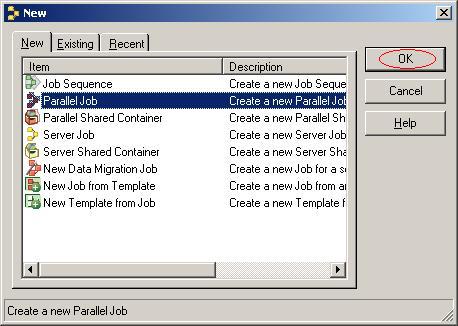
?
(7)选择"Parallel Job",单击按钮"OK";
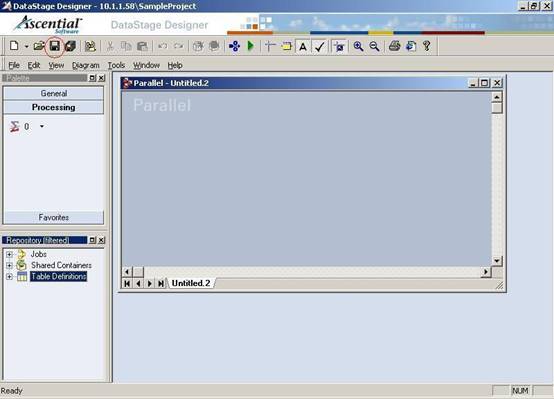
?
(8) 一个新的ETL Job已经创建了,单击工具栏上的图标"保存",或者用快捷键"Ctrl+S"来保存,这时候一个保存ETL Job的对话框会弹出来;
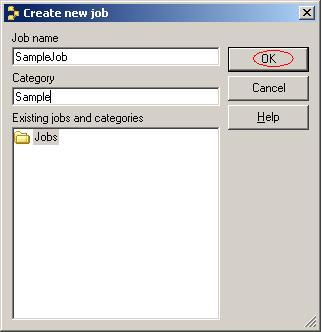
?
(9)在弹出的对话框中。在Job name一栏输入"SampleJob",在Category中输入"Sample"。单击按钮"OK";
?
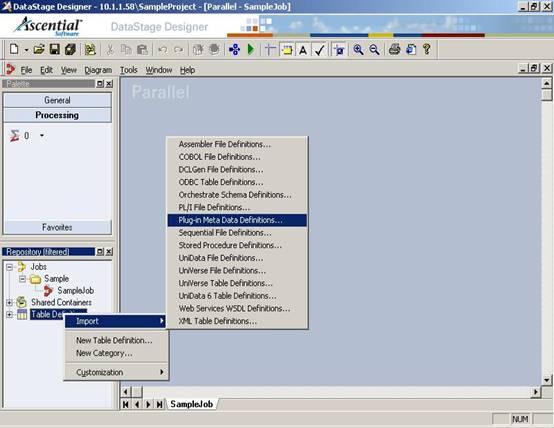
(10) 保存好刚创建的ETL Job后,我们用DataStage Designer来导入数据库的表结构。在DataStage Designer的左下方的Repository中右键单击"Table Definition"。然后选择 Import'Pug-in Meta Data Definitions…;
?
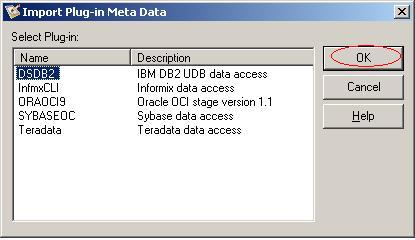
(11)在弹出的对话框中选择DSDB2,单击按钮OK;
?
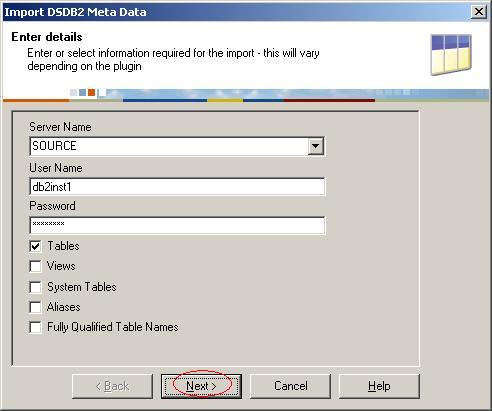
(12) 在弹出的对话框中,Server Name选择Source。输入用户名和密码,再钩上Tables选择框之后单击按钮Next;
?
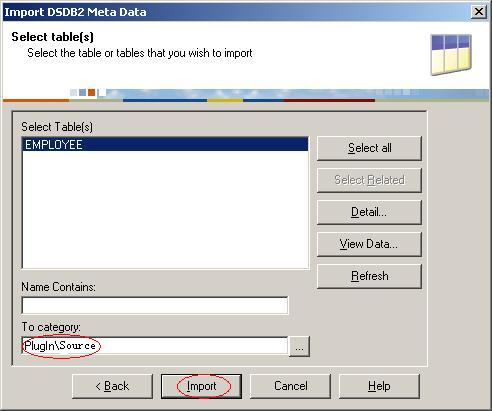
(13)选择表employee,把要保存到的目录改成PlugIn\Source。然后单击按钮 Import.;
?
(14)重复步骤 10-13把存储在Target数据库中的表employee的表结构导入进来,这次存放的路径改成PlugIn\Target。完成后,你会在Repository中看到你导入的表结构;
?
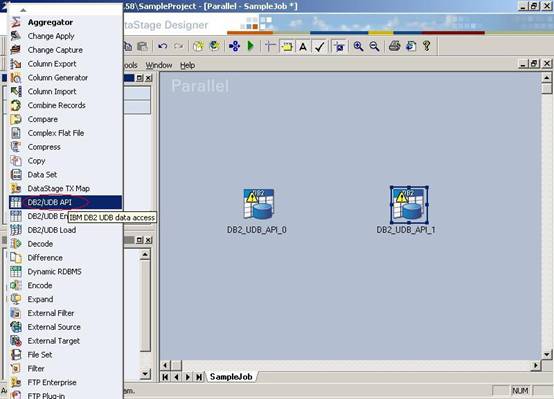
(15)从左边的palette中拖入两个DB2/UDB API Stage到右边的面板上。DB2/UDB2 API Stage是用来连接DB2数据库的,我们这两个DB2/UDB API Stage一个用来连接数据库source,另一个用来连接数据库Target;
?
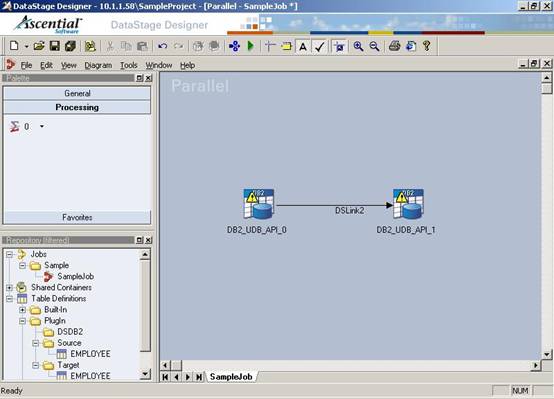
(16)右键单击左边的DB2/UDB API Stage不要放开,一直拖拽鼠标到右边的DB2/UDB2 API Stage上面。这时候在这两个Stage之间会出现一条连线,代表了数据的流向。下面我们将配置这两个Stage的属性;
?
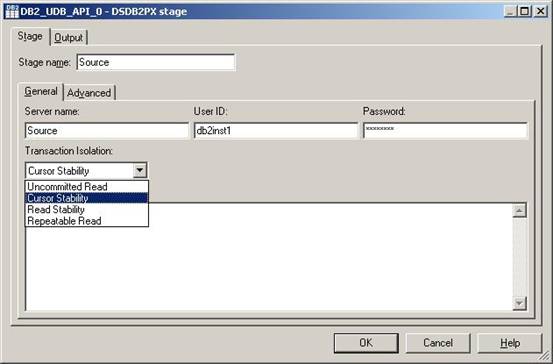
(17)左键双击左边的DB2/UDB API Stage,会弹出如下图所示的属性框。在标签Stage的子标签General中,设置Stage name为Source,Server name为Source,User ID和 Password设置为右权限访问这个数据库的用户名和密码。Transaction Isolation的默认的选项是Cursor Stability,保持默认选项然后单击标签Output;
?
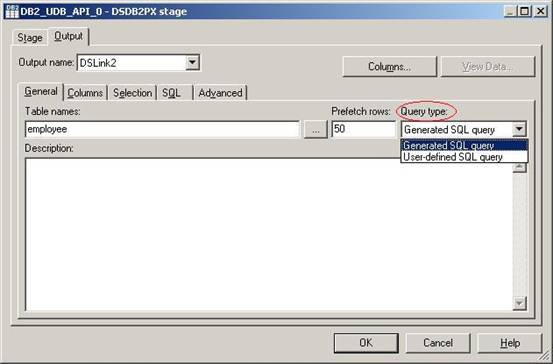
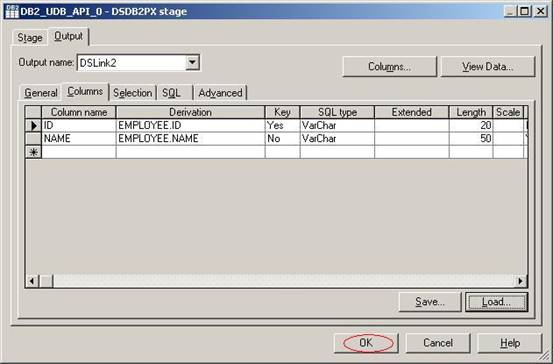
(18)在标签Output的子标签General中,输入Table names为employee,并在Query type下拉框中选择Generated SQL Query。这样DataStage会自动帮你生成大部分的SQL代码。然后单击子标签Columns;
?
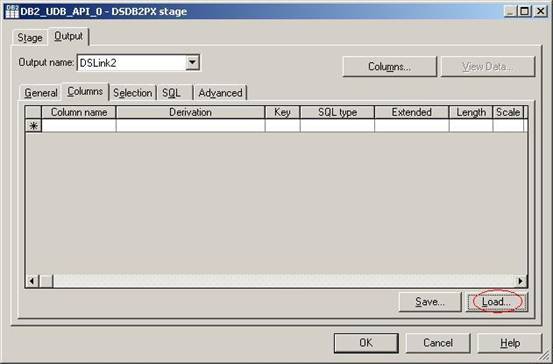
(19)在Columns子标签中单击按钮Load去导入刚才从数据库中导进来的表结构;
?
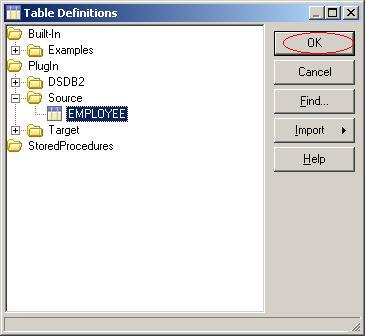
(20)在弹出的对话框中选择目录PlugIn\Source中的表结构employee,然后单击按钮OK;
?
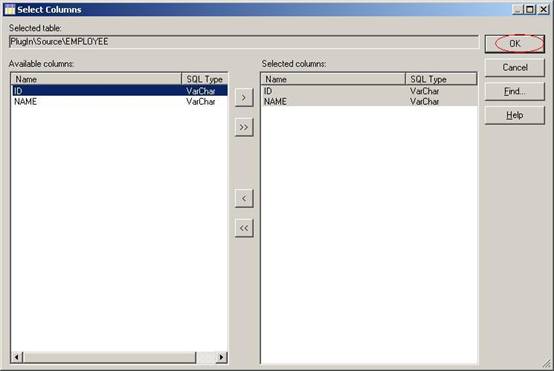
(21) 在弹出的对话框中选择要导入的表的列,默认是全选,保持默认并单击按钮OK;
?
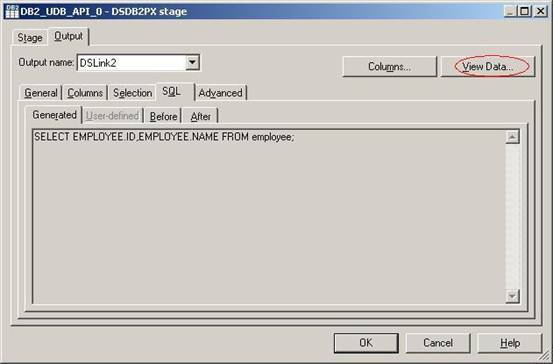
(22) 这时候你会看到表的字段已经被导入进来。单击子标签SQL;
?
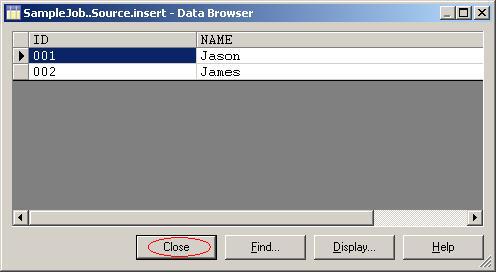
(23) 在子标签SQL中,你会看到系统自动生成的SQL语句。单击按钮 View Data查看表employee中的数据;
?
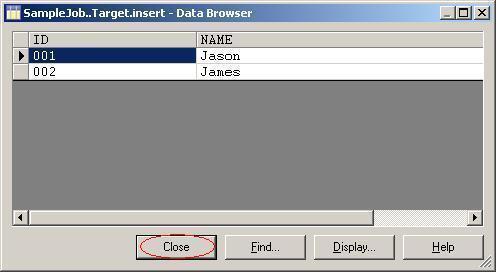
(24)当前employee表中有两条数据。单击按钮Close关掉数据查看窗口;
?
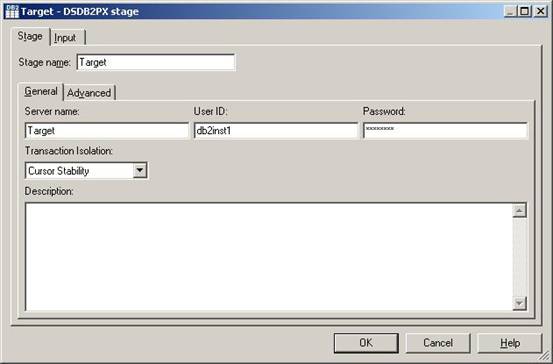
(25)现在我们开始编辑用来连接目标数据库的DB2/UDB API Stage的属性。双击这个Stage,弹出的属性设置窗口如下图所示。在标签Stage的子标签General中,Stage name设置为Target,Server name设置为Target,User ID和Password分别设置为有权限对Target数据库进行操作的用户名和密码。其他属性保持默认值,然后单击标签Input;
?
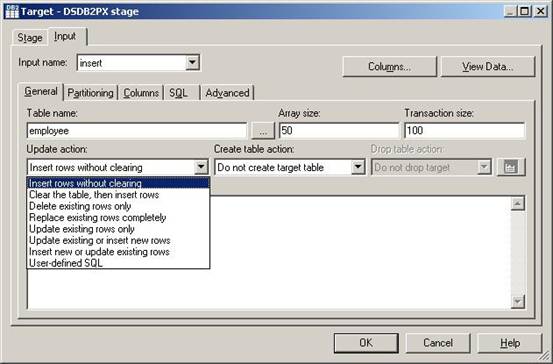
(26)在标签Input的子标签General中,设置Table name为employee,Update action选择 Insert rows without cleaning。Create table action选择Do not create target table。然后单击子标签Columns;
?
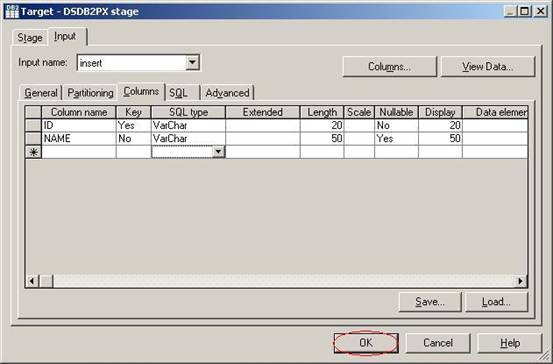
(27)在子标签Columns中,你会发现已经有表结构load进来了,这个表结构是和source数据库中的employee表的结构一致的。单击按钮OK并保存ETL Job;
?
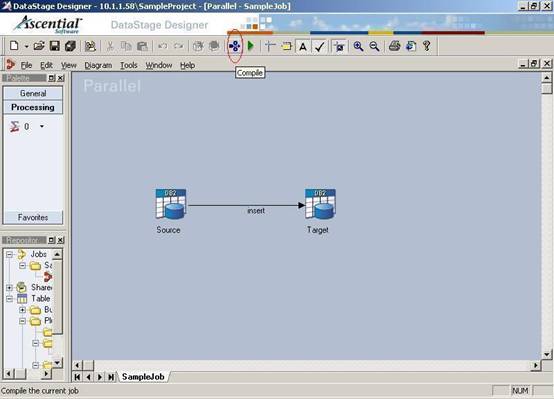
(28)在工具栏中单击图标"编译"对刚开发完的ETL Job进行编译;
?
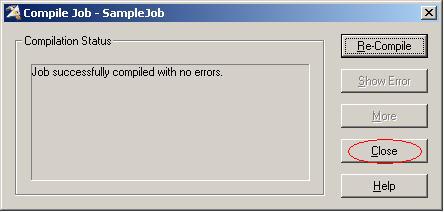
(29)编译过程中会弹出一个对话框显示编译的进行情况。最终ETL Job编译成功后对话框中会显示如下图中所示的消息:"Job successfully compiled with no errors";
?
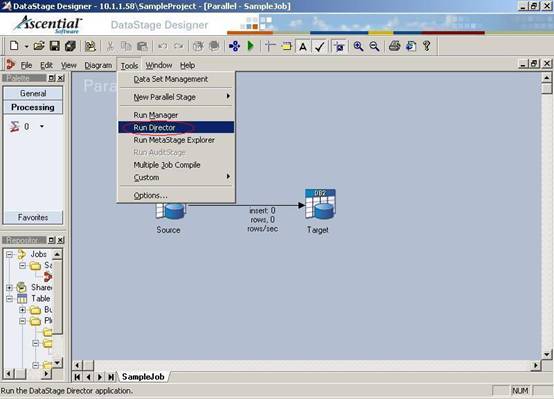
(30)编译成功后,我们打开DataStage Director来运行我们开发的ETL Job。从DataStage Designer中打开DataStage Director的方法为:从菜单栏中选择Tools'Run Director;
?
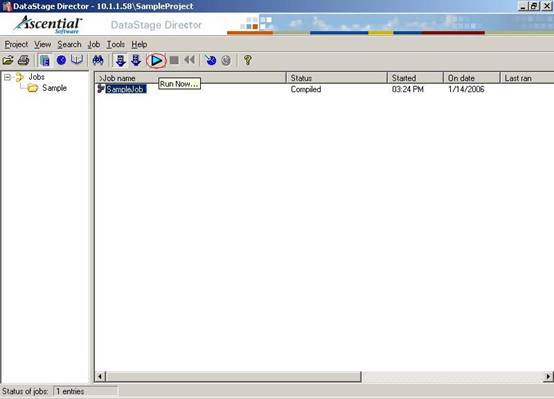
(31)打开DataStage Director后你会在Sample目录下面发现我们开发好的ETL Job SampleJob,状态为Compiled。选择SampleJob,然后单击工具栏中的"运行"按钮;
?
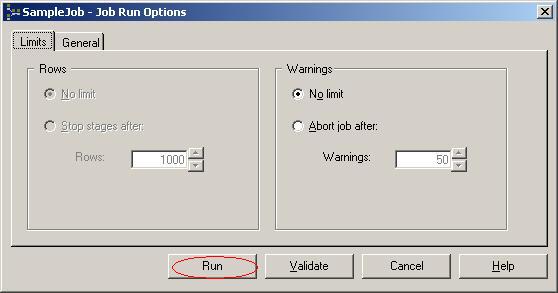
(32)在弹出的对话框中可以设置运行的参数,比如出现多少个warning后ETL Job会自动中止掉。我们保持这个对话框中的默认设置,单击按钮Run;
?
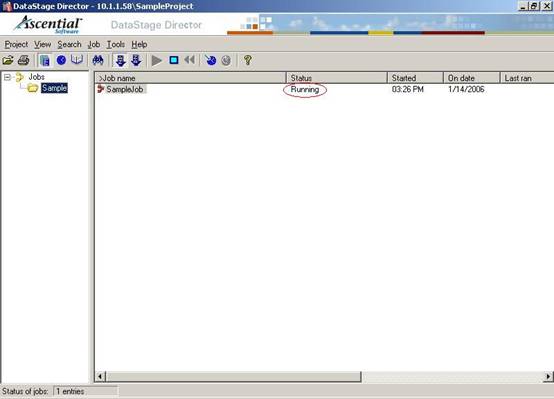
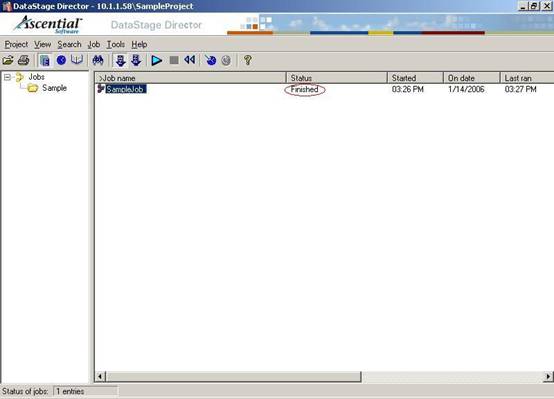
(33) 这时候你会注意到SampleJob的状态从Compiled变成了Running,等到SampleJob的状态变成Finished后,该ETL Job的运行就结束了;
?
(34)如下图所示,SampleJob的状态变成了Finished。SampleJob成功结束运行;
?
(35)到DataStage Designer中,用View Data功能查看目标数据库Target中employee表中的数据。你会发现和源数据库source中的employee表中的数据是一样的。也说明我们开发的ETL Job成功的完成了我们想要它完成的任务。
?
总结
本文首先介绍IBM WebSphere DataStage在数据源连接能力以及并行执行能力两方面的特性,接着介绍了它的开发环境。最后用一个简单的ETL Job演示了用IBM WebSphere DataStage进行ETL开发的过程,使大家对这个过程有了一个比较清楚的了解。IBM WebSphere DataStage提供的图形化的环境使我们更容易进行开发和维护。
?
?
 ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
?