[] [原创]JWFDv0.96工作流系统--流程XML文档结构说明

本文简要介绍了jwfdv0.96工作流系统的流程图xml模型结构,其中带有少量的专业语言,浅显易懂,适合初学工作流系统的设计和开发者,在了解这个结构之后就需要大家把注意力集中到流程图xml数据到后台sql数据库结构的建立过程中,以便大家理解jwfd工作流引擎的工作原理及其实现方式
1:使用jwfd流程设计器画出一个简单的串行流程图(保存为xxxx.gxl)
这里使用的流程图的数据结构是采用图论中的(顶点,边)模型来生成的,这方面的理论知识请参考清华大学的<数据结构>教程第七章-图-第二节-图形的存储结构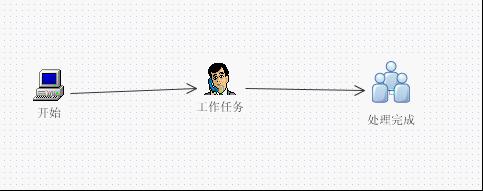
2:保持为gxl文件(xml)格式,可以点击流程图设计器下边的xxxx.gxl栏目,查看这个流程图的xml数据内容,下面我详细介绍下这个流程图的xml数据结构的意义,因为数据库的数据是以这个xml数据为基础的而生成的,所谓建模的过程就是指从设计流程图到最后数据进入数据库保存这一过程,而流程图的矩阵建模,可以参考我的另外一片文章(jwfd工作流引擎设计--简单矩阵建模和应用(初步讨论) http://www.iteye.com/topic/718562)
以流程图的第一个节点“开始”为例子,其它流程节点的xml结构都是一致的
(说明:一个流程图节点的xml数据结构主要有下面所描述的6个核心属性构成,实际上,一个商业的流程管理系统中的流程图的节点属性远远比jwfd里面的节点属性多,但是这些属性都是在这6个属性上面进行扩展而成的,具体的扩展方法我将在另外的文章中介绍)
<node id="node0">
<attr name="label">
<string>开始</string>
</attr>
<attr name="bounds">
<tup>
<int>120</int>
<int>180</int>
<int>42</int>
<int>60</int>
</tup>
</attr>
<attr name="font">
<tup>
<string>宋体</string>
<int>0</int>
<int>12</int>
</tup>
</attr>
<attr name="icon">
<tup>
<string>resources/pc04.gif</string>
</tup>
</attr>
<attr name="condition">
<tup>
<string>none</string>
</tup>
</attr>
</node>
属性名称node id :这个属性是节点的实际名称node0是流程图通过建模进入数据库之后的实际名称, 和属性label标签的名称是不一致的,这点需要注意,这个属性值由系统自动生成
属性名称 label :表示该节点显示的中文名称,这里是"开始",这个属性由用户自定义
属性名称 bounds :表示这个节点在流程图中的绝对坐标数据,从上到下分别是x坐标和y坐标和节点的长度与宽度,这个属性由系统自动生成
属性名称 font:表示该节点名称所使用的字体类型和字体大小,例子里面是宋体和12标号的字体大小
属性名称 icon:表示该节点所使用的图标icon,实际上jgraph的默认图标是很单调的,而jwfd里面的图标是我随意选择的,不是很正规,如果要做商业的流程系统,请用户选择一套比较标准的流程节点图标(具体的图标替换方法我会在另外一篇文章中介绍)
属性名称 condition:这个属性是jwfd自定义的属性,用于给节点添加嵌入式的公式和脚本数据,这个数据由用户通过节点属性编辑器自行添加和修改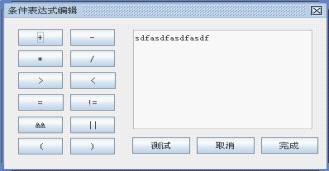
这个条件表达式所编辑的数据就保存在这个属性值中,经过系统的处理,最终这个条件表达式的数据就保存进入流程数据库中的cond字段中,具体的数据结构请参考jwfdv0.96的数据库结构
那么上面介绍了一个节点的xml数据结构,但是一个完整的流程图是由节点和连接节点的线段组成的,所以我们还需要了解连接节点的边的数据结构,才能够完成流程的数据结构。。。下面我们就介绍线段-边的xml数据结构
全部内容请下载附件的doc文档的压缩包,这里只选择本文的前半部