Android解析XML的方式
android解析xml文件的方式:通常有三种方式:DOM,SAX,PULL
?
(1)DOM方式解析xml是先把xml文档都读到内存中,然后再用DOM API来访问树形结构,并获取数据的,但是这样一来,如果xml文件很大呢?手机CPU处理能力当然不能与PC机器比,因此在处理效率方面就相对差了,当然这是对于其他方式处理xml文档而言。
?
?
(2)SAX是基于事件驱动的。
当然android的事件机制是基于回调函数的,在用SAX解析xml文档时候,在读取到文档开始和结束标签时候就会回调一个事件,在读取到其他节点与内容时候也会回调一个事件。
????? 既然涉及到事件,就有事件源,事件处理器。在SAX接口中,
事件源是:org.xml.sax包中的XMLReader,它通过parser()方法来解析XML文档,并产生事件。
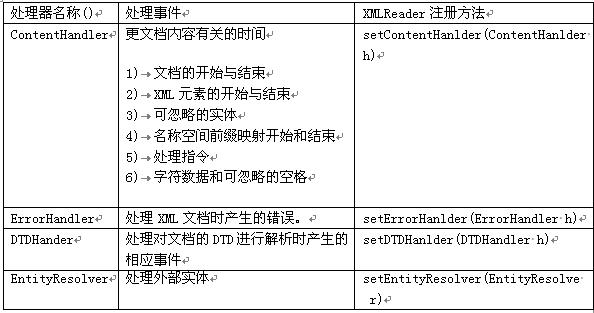
事件处理器是:org.xml.sax包中ContentHander、DTDHander、ErrorHandler,以及EntityResolver这4个接口
组织原理:XMLReader通过相应事件处理器注册方法setXXXX()来完成的与ContentHander、DTDHander、ErrorHandler,以及EntityResolver这4个接口的连接,详细介绍请见下表:
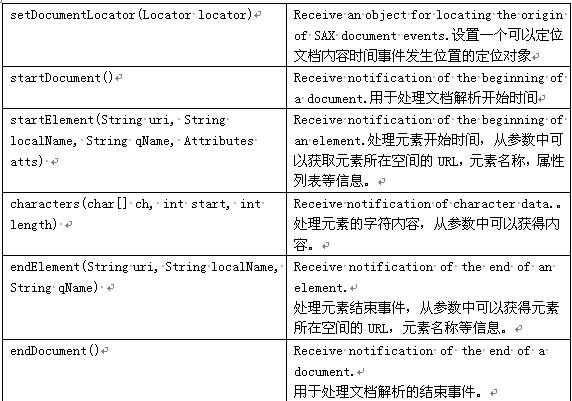
但是我们无需都继承这4个接口,SDK为我们提供了DefaultHandler类来处理,DefaultHandler类的一些主要事件回调方法如下:
?
?
由以上可知,我们需要XmlReader 以及DefaultHandler来配合解析xml。
处理思路是:
1:创建SAXParserFactory对象
2: 根据SAXParserFactory.newSAXParser()方法返回一个SAXParser解析器
3:根据SAXParser解析器获取事件源对象XMLReader
4:实例化一个DefaultHandler对象
5:连接事件源对象XMLReader到事件处理类DefaultHandler中
6:调用XMLReader的parse方法从输入源中获取到的xml数据
7:通过DefaultHandler返回我们需要的数据集合。
?
(3)PULL 也是基于事件驱动的,只不过PULL方式读xml回调方法返回的是数字。
?? 读取到xml的声明返回 ???? START_DOCUMENT;
?? 读取到xml的结束返回????? ?END_DOCUMENT ;
?? 读取到xml的开始标签返回 START_TAG
?? 读取到xml的结束标签返回 END_TAG
?? 读取到xml的文本返回?????? TEXT
采用PULL方式与SAX大同小异,重点在于我们需要知道导航到什么标签时候做什么就行了。
基本处理方式是:当PULL解析器导航到文档开始标签时就开始实例化list集合用来存贮数据对象。导航到元素开始标签时回判断元素标签类型,如果是river标签,则需要实例化River对象了,如果是其他类型,则取得该标签内容并赋予River对象。当然它也会导航到文本标签,不过在这里,我们可以不用。
?根据以上的解释,我们可以得出以下处理xml文档逻辑:
1:当导航到XmlPullParser.START_DOCUMENT,可以不做处理,当然你可以实例化集合对象等等。
2:当导航到XmlPullParser.START_TAG,则判断是否是river标签,如果是,则实例化river对象,并调用getAttributeValue方法获取标签中属性值。
3:当导航到其他标签,比如Introduction时候,则判断river对象是否为空,如不为空,则取出Introduction中的内容,nextText方法来获取文本节点内容
4:当然啦,它一定会导航到XmlPullParser.END_TAG的,有开始就要有结束嘛。在这里我们就需要判读是否是river结束标签,如果是,则把river对象存进list集合中了,并设置river对象为null.