使用分页方式读取超大文件的性能试验
Read extreme large files using paging
by Nobi Conmajia (conmajia@gmail.com)
May 15th, 2012
(注:本文使用FileStream类的Seek()和Read()方法完成文件读取,未使用特别读取方式。)
我们在编程过程中,经常会和计算机文件读取操作打交道。随着计算机功能和性能的发展,我们需要操作的文件尺寸也是越来越大。在.NET Framework中,我们一般使用FileStream来读取、写入文件流。当文件只有数十kB或者数MB时,一般的文件读取方式如Read()、ReadAll()等应用起来游刃有余,基本不会感觉到太大的延迟。但当文件越来越大,达到数百MB甚至数GB时,这种延迟将越来越明显,最终达到不能忍受的程度。
通常定义大小在2GB以上的文件为超大文件(当然,这个数值会随着科技的进步,越来越大)。对于这样规模的文件读取,普通方法已经完全不能胜任。这就要求我们使用更高效的方法,如内存映射法、分页读取法等。
内存映射(Memory Mapping)
内存映射的方法可以使用下面的Windows API实现。
157 //}158 159 }160 }161 /// <summary>162 /// 获取高32位163 /// </summary>164 /// <param name="intValue"></param>165 /// <returns></returns>166 private static uint GetHighWord( UInt64 intValue )167 {168 return Convert.ToUInt32( intValue >> 32 );169 }170 /// <summary>171 /// 获取低32位172 /// </summary>173 /// <param name="intValue"></param>174 /// <returns></returns>175 private static uint GetLowWord( UInt64 intValue )176 {177 178 return Convert.ToUInt32( intValue & 0x00000000FFFFFFFF );179 }180 181 /// <summary>182 /// 获取下一个文件块 块大小为20M183 /// </summary>184 /// <returns>false 表示已经是最后一块文件</returns>185 public uint GetNextblock()186 {187 if ( !this.m_bInit ) throw new Exception( "文件未初始化。" );188 //if ( m_offsetBegin + m_MemSize >= m_FileSize ) return false;189 190 uint m_Size = GetMemberSize();191 if ( m_Size == 0 ) return m_Size;192 193 // 更改缓冲区大小194 m_MemSize = m_Size;195 196 //卸载前一个文件197 //bool l_result = UnmapViewOfFile( m_pwData );198 //m_pwData = IntPtr.Zero;199 200 201 m_pwData = MapViewOfFile( m_hSharedMemoryFile, FILE_MAP_READ, GetHighWord( ( UInt64 )m_offsetBegin ), GetLowWord( ( UInt64 )m_offsetBegin ), m_Size );202 if ( m_pwData == IntPtr.Zero )203 {204 m_bInit = false;205 throw new Exception( "映射文件块失败" + GetLastError().ToString() );206 }207 m_offsetBegin = m_offsetBegin + m_Size;208 209 return m_Size; //创建成功210 }211 /// <summary>212 /// 返回映射区大小213 /// </summary>214 /// <returns></returns>215 private uint GetMemberSize()216 {217 if ( m_offsetBegin >= m_FileSize )218 {219 return 0;220 }221 else if ( m_offsetBegin + m_MemSize >= m_FileSize )222 {223 long temp = m_FileSize - m_offsetBegin;224 return ( uint )temp;225 }226 else227 return m_MemSize;228 }229 230 /// <summary>231 /// 关闭内存映射232 /// </summary>233 public void Close()234 {235 if ( m_bInit )236 {237 UnmapViewOfFile( m_pwData );238 CloseHandle( m_hSharedMemoryFile );239 File.Close();240 }241 }242 243 /// <summary>244 /// 从当前块中获取数据245 /// </summary>246 /// <param name="bytData">数据</param>247 /// <param name="lngAddr">起始数据</param>248 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>249 /// <param name="Unmap">读取完成是否卸载缓冲区</param>250 /// <returns></returns>251 public void Read( ref byte[] bytData, int lngAddr, int lngSize, bool Unmap )252 {253 if ( lngAddr + lngSize > m_MemSize )254 throw new Exception( "Read操作超出数据区" );255 if ( m_bInit )256 {257 // string bb = Marshal.PtrToStringAuto(m_pwData);//258 Marshal.Copy( m_pwData, bytData, lngAddr, lngSize );259 }260 else261 {262 throw new Exception( "文件未初始化" );263 }264 265 if ( Unmap )266 {267 bool l_result = UnmapViewOfFile( m_pwData );268 if ( l_result )269 m_pwData = IntPtr.Zero;270 }271 }272 273 /// <summary>274 /// 从当前块中获取数据275 /// </summary>276 /// <param name="bytData">数据</param>277 /// <param name="lngAddr">起始数据</param>278 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>279 /// <exception cref="Exception: Read操作超出数据区"></exception>280 /// <exception cref="Exception: 文件未初始化"></exception>281 /// <returns></returns>282 public void Read( ref byte[] bytData, int lngAddr, int lngSize )283 {284 if ( lngAddr + lngSize > m_MemSize )285 throw new Exception( "Read操作超出数据区" );286 if ( m_bInit )287 {288 Marshal.Copy( m_pwData, bytData, lngAddr, lngSize );289 }290 else291 {292 throw new Exception( "文件未初始化" );293 }294 }295 296 /// <summary>297 /// 从当前块中获取数据298 /// </summary>299 /// <param name="lngAddr">缓存区偏移量</param>300 /// <param name="byteData">数据数组</param>301 /// <param name="StartIndex">数据数组开始复制的下标</param>302 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>303 /// <exception cref="Exception: 起始数据超过缓冲区长度"></exception>304 /// <exception cref="Exception: 文件未初始化"></exception>305 /// <returns>返回实际读取值</returns>306 public uint ReadBytes( int lngAddr, ref byte[] byteData, int StartIndex, uint intSize )307 {308 if ( lngAddr >= m_MemSize )309 throw new Exception( "起始数据超过缓冲区长度" );310 311 if ( lngAddr + intSize > m_MemSize )312 intSize = m_MemSize - ( uint )lngAddr;313 314 if ( m_bInit )315 {316 IntPtr s = new IntPtr( ( long )m_pwData + lngAddr ); // 地址偏移317 Marshal.Copy( s, byteData, StartIndex, ( int )intSize );318 }319 else320 {321 throw new Exception( "文件未初始化" );322 }323 324 return intSize;325 }326 327 /// <summary>328 /// 写数据329 /// </summary>330 /// <param name="bytData">数据</param>331 /// <param name="lngAddr">起始地址</param>332 /// <param name="lngSize">个数</param>333 /// <returns></returns>334 private int Write( byte[] bytData, int lngAddr, int lngSize )335 {336 if ( lngAddr + lngSize > m_MemSize ) return 2; //超出数据区337 if ( m_bInit )338 {339 Marshal.Copy( bytData, lngAddr, m_pwData, lngSize );340 }341 else342 {343 return 1; //共享内存未初始化344 }345 return 0; //写成功346 }347 }348 internal class FileReader349 {350 const uint GENERIC_READ = 0x80000000;351 const uint OPEN_EXISTING = 3;352 System.IntPtr handle;353 354 [DllImport( "kernel32", SetLastError = true )]355 public static extern System.IntPtr CreateFile(356 string FileName, // file name357 uint DesiredAccess, // access mode358 uint ShareMode, // share mode359 uint SecurityAttributes, // Security Attributes360 uint CreationDisposition, // how to create361 uint FlagsAndAttributes, // file attributes362 int hTemplateFile // handle to template file363 );364 365 [System.Runtime.InteropServices.DllImport( "kernel32", SetLastError = true )]366 static extern bool CloseHandle367 (368 System.IntPtr hObject // handle to object369 );370 371 372 373 public IntPtr Open( string FileName )374 {375 // open the existing file for reading 376 handle = CreateFile377 (378 FileName,379 GENERIC_READ,380 0,381 0,382 OPEN_EXISTING,383 0,384 0385 );386 387 if ( handle != System.IntPtr.Zero )388 {389 return handle;390 }391 else392 {393 throw new Exception( "打开文件失败" );394 }395 }396 397 public bool Close()398 {399 return CloseHandle( handle );400 }401 }402 }分页读取法(Paging)
另外一种高效读取文件的方法就是分页法,也叫分段法(Segmentation),对应的读取单位被称作页(Page)和段(Segment)。其基本思想是将整体数据分割至较小的粒度再进行处理,以便满足时间、空间和性能方面的要求。分页法的概念使用相当广泛,如嵌入式系统中的分块处理(Blocks)和网络数据的分包传输(Packages)。

在开始研究分页法前,先来看看在超大文件处理中,最为重要的问题:高速随机访问。桌面编程中,分页法通常应用于文字处理、阅读等软件,有时也应用在大型图片显示等方面。这类软件的一个特点就是数据的局部性,无论需要处理的文件有多么大,使用者的注意力(也可以称为视口ViewPort)通常只有非常局部的一点(如几页文档和屏幕大小的图片)。这就要求了接下来,我们要找到一种能够实现高速的随机访问,而这种访问效果还不能和文件大小有关(否则就失去了高速的意义)。事实上,以下我们研究的分页法就是利用了「化整为零」的方法,通过只读取和显示用户感兴趣的那部分数据,达到提升操作速度的目的。

参考上图,假设计算机上有某文件F,其内容为「01234567890123456」(引号「」中的内容,不含引号,下同),文件大小为FileLength=17字节,以PageSize=3对F进行分页,总页数PageCount=6,得到页号为0~5的6个页面(图中页码=页号+1)。各页面所含数据如下表所示。
页号页码内容至头部偏移量 (Hex)长度0101200 01 0231234503 04 0532367806 07 0833490109 0a 0b3452340c 0d 0e356560f 102可以看到,最后一页的长度为2(最后一页长度总是小于PageSize)。
当我们要读取「第n页」的数据(即页码=n)时,实际上读取的是页号PageNumber=n-1的内容。例如n=3时,PageNumber=2,数据为「678」,该页数据偏移量范围从0x06至0x08,长度为3(PageSize)。为便于讲述,在此约定:以下文字中,均只涉及页号,即PageNumber。
参考图2,设当PageNumber=x时,页x的数据范围为[offsetStart, offsetEnd],那么可以用如下的代码进行计算(C#2.0)。
1 offsetStart = pageNumber * pageSize; 2 3 if(offsetStart + pageSize < fileSize) 4 { 5 offsetEnd = offsetStart + pageSize; 6 } 7 else 8 { 9 offsetEnd = fileSize - 1;10 }我们常用的System.IO.FileStream类有两个重要的方法:Seek()和Read()。
1 // 将该流的当前位置设置为给定值。 2 public override long Seek ( 3 long offset, 4 SeekOrigin origin 5 ) 6 7 // 从流中读取字节块并将该数据写入给定缓冲区中。 8 public override int Read ( 9 [InAttribute] [OutAttribute] byte[] array,10 int offset,11 int count12 )
利用这两个方法,我们可以指定每次读取的数据起始位置(offsetStart)和读取长度(offsetEnd - offsetStart),这样就可以读到任意指定的页数据。我们可以遍历读取所有页,这就相当于普通读取整个文件(实际操作中,一般不会有需求一次读取上GB的文件)。
下面是为了测试分页法而制作的超大文件读取器界面截图,图中读取的是本次试验的用例之一Windows8消费者预览版光盘镜像(大小:3.40GB)。
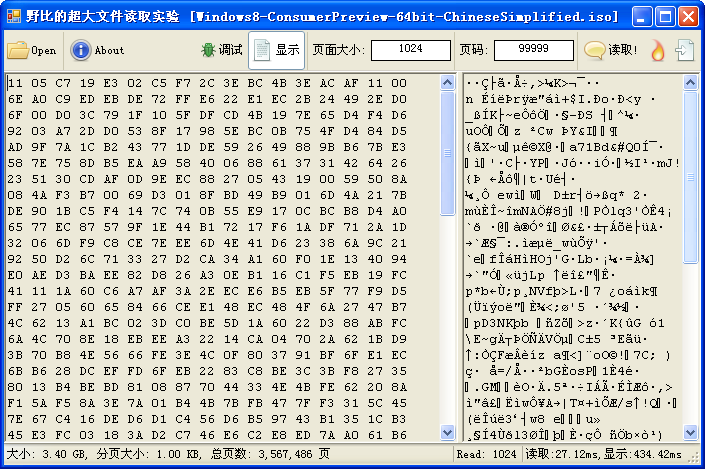
本次测试选择了「大、中、小」3种规格的测试文件作为测试用例,分别为:
#文件名文件内容大小(KB)1AlishaHead.pngPoser Pro 6贴图11,6112ubuntu-11.10-desktop-i386.isoUbuntu11.10桌面版镜像711,9803Windows8-ConsumerPreview-64bit-ChineseSimplified.isoWindows8消费者预览版64位简体中文版镜像3,567,486通过进行多次读取,采集到如下表A所示的文件读取数据结果。表中项目「分页(单页)」表示使用分页读取法,但设置页面大小为文件大小(即只有1页)进行读取。同样的,为了解分页读取的性能变化情况,使用普通读取方法(一次读取)采集到另一份数据结果,如下表B所示。
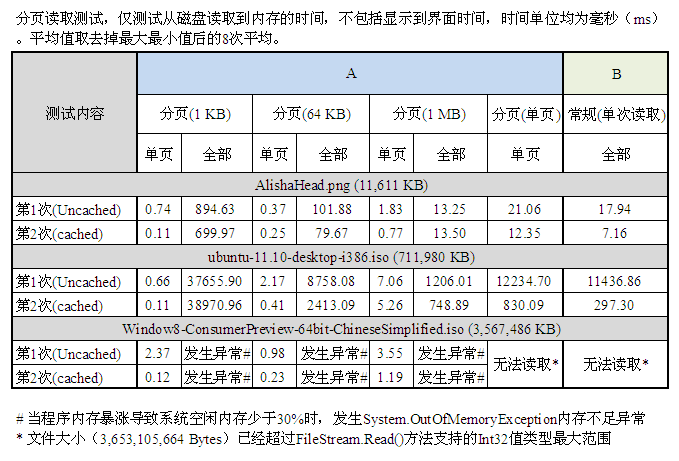
对用例#1,该用例大小仅11MB,使用常规(单次)读取方法,仅用不到20ms即将全部内容读取完毕。而当采用分页法,随着分页大小越来越小,文件被划分为更多的页面,尽管随机访问文件内容使得文件操作更加方便,但在读取整个文件的时候,分页却带来了更多的消耗。例如当分页大小为1KB时,文件被分割为11,611个页面。读取整个文件时,需要重复调用11,611次FileStream.Read()方法,增加了很多消耗,如下图所示。(图中数据仅为全文读取操作对比)
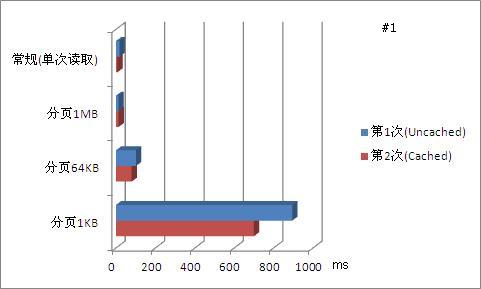
从图中可以看到,当分页尺寸过分的小(1KB)时,这种过度追求微粒化反而导致了操作性能下降。可以看到,即实现了微粒化,能够进行随机访问,同时仍保有一定量的操作性能,分页大小为64KB和1MB是不错的选择。实际上,上文介绍的MapViewOfFile函数的推荐分页大小正是64KB。
对用例#2,该用例大小为695.29MB,达到较大的尺寸,因此对读取缓存(cache)需求较高,同时也对合适的分页尺寸提出了要求。可以看到,和用例#1不同,当文件尺寸从11.34MB增加到近700MB时,分页尺寸随之相应的扩大,是提高操作性能的好方法(下图中1MB分页)。
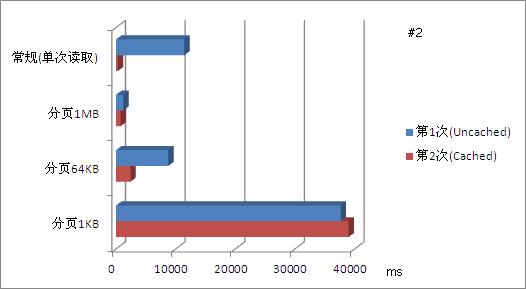
对用例#3,该用例达到3.4GB大小,符合我们对超大文件的定义。通过前述2个用例的分析,可以推测,为获得最佳性能,分页大小需继续提高(比如从1MB提高到4MB)。由于本次试验时间仓促,考虑不周,未使用「边读取、边丢弃」的测试算法,导致分页读取用例#3的数据时,数据不断在内存中积累,最终引发System.OutOfMemoryException异常,使得分页读取完整文件这项测试不能正常完成。这一问题,需在下次的试验当中加以解决和避免。
 157 //}158 159 }160 }161 /// <summary>162 /// 获取高32位163 /// </summary>164 /// <param name="intValue"></param>165 /// <returns></returns>166 private static uint GetHighWord( UInt64 intValue )167 {168 return Convert.ToUInt32( intValue >> 32 );169 }170 /// <summary>171 /// 获取低32位172 /// </summary>173 /// <param name="intValue"></param>174 /// <returns></returns>175 private static uint GetLowWord( UInt64 intValue )176 {177 178 return Convert.ToUInt32( intValue & 0x00000000FFFFFFFF );179 }180 181 /// <summary>182 /// 获取下一个文件块 块大小为20M183 /// </summary>184 /// <returns>false 表示已经是最后一块文件</returns>185 public uint GetNextblock()186 {187 if ( !this.m_bInit ) throw new Exception( "文件未初始化。" );188 //if ( m_offsetBegin + m_MemSize >= m_FileSize ) return false;189 190 uint m_Size = GetMemberSize();191 if ( m_Size == 0 ) return m_Size;192 193 // 更改缓冲区大小194 m_MemSize = m_Size;195 196 //卸载前一个文件197 //bool l_result = UnmapViewOfFile( m_pwData );198 //m_pwData = IntPtr.Zero;199 200 201 m_pwData = MapViewOfFile( m_hSharedMemoryFile, FILE_MAP_READ, GetHighWord( ( UInt64 )m_offsetBegin ), GetLowWord( ( UInt64 )m_offsetBegin ), m_Size );202 if ( m_pwData == IntPtr.Zero )203 {204 m_bInit = false;205 throw new Exception( "映射文件块失败" + GetLastError().ToString() );206 }207 m_offsetBegin = m_offsetBegin + m_Size;208 209 return m_Size; //创建成功210 }211 /// <summary>212 /// 返回映射区大小213 /// </summary>214 /// <returns></returns>215 private uint GetMemberSize()216 {217 if ( m_offsetBegin >= m_FileSize )218 {219 return 0;220 }221 else if ( m_offsetBegin + m_MemSize >= m_FileSize )222 {223 long temp = m_FileSize - m_offsetBegin;224 return ( uint )temp;225 }226 else227 return m_MemSize;228 }229 230 /// <summary>231 /// 关闭内存映射232 /// </summary>233 public void Close()234 {235 if ( m_bInit )236 {237 UnmapViewOfFile( m_pwData );238 CloseHandle( m_hSharedMemoryFile );239 File.Close();240 }241 }242 243 /// <summary>244 /// 从当前块中获取数据245 /// </summary>246 /// <param name="bytData">数据</param>247 /// <param name="lngAddr">起始数据</param>248 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>249 /// <param name="Unmap">读取完成是否卸载缓冲区</param>250 /// <returns></returns>251 public void Read( ref byte[] bytData, int lngAddr, int lngSize, bool Unmap )252 {253 if ( lngAddr + lngSize > m_MemSize )254 throw new Exception( "Read操作超出数据区" );255 if ( m_bInit )256 {257 // string bb = Marshal.PtrToStringAuto(m_pwData);//258 Marshal.Copy( m_pwData, bytData, lngAddr, lngSize );259 }260 else261 {262 throw new Exception( "文件未初始化" );263 }264 265 if ( Unmap )266 {267 bool l_result = UnmapViewOfFile( m_pwData );268 if ( l_result )269 m_pwData = IntPtr.Zero;270 }271 }272 273 /// <summary>274 /// 从当前块中获取数据275 /// </summary>276 /// <param name="bytData">数据</param>277 /// <param name="lngAddr">起始数据</param>278 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>279 /// <exception cref="Exception: Read操作超出数据区"></exception>280 /// <exception cref="Exception: 文件未初始化"></exception>281 /// <returns></returns>282 public void Read( ref byte[] bytData, int lngAddr, int lngSize )283 {284 if ( lngAddr + lngSize > m_MemSize )285 throw new Exception( "Read操作超出数据区" );286 if ( m_bInit )287 {288 Marshal.Copy( m_pwData, bytData, lngAddr, lngSize );289 }290 else291 {292 throw new Exception( "文件未初始化" );293 }294 }295 296 /// <summary>297 /// 从当前块中获取数据298 /// </summary>299 /// <param name="lngAddr">缓存区偏移量</param>300 /// <param name="byteData">数据数组</param>301 /// <param name="StartIndex">数据数组开始复制的下标</param>302 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>303 /// <exception cref="Exception: 起始数据超过缓冲区长度"></exception>304 /// <exception cref="Exception: 文件未初始化"></exception>305 /// <returns>返回实际读取值</returns>306 public uint ReadBytes( int lngAddr, ref byte[] byteData, int StartIndex, uint intSize )307 {308 if ( lngAddr >= m_MemSize )309 throw new Exception( "起始数据超过缓冲区长度" );310 311 if ( lngAddr + intSize > m_MemSize )312 intSize = m_MemSize - ( uint )lngAddr;313 314 if ( m_bInit )315 {316 IntPtr s = new IntPtr( ( long )m_pwData + lngAddr ); // 地址偏移317 Marshal.Copy( s, byteData, StartIndex, ( int )intSize );318 }319 else320 {321 throw new Exception( "文件未初始化" );322 }323 324 return intSize;325 }326 327 /// <summary>328 /// 写数据329 /// </summary>330 /// <param name="bytData">数据</param>331 /// <param name="lngAddr">起始地址</param>332 /// <param name="lngSize">个数</param>333 /// <returns></returns>334 private int Write( byte[] bytData, int lngAddr, int lngSize )335 {336 if ( lngAddr + lngSize > m_MemSize ) return 2; //超出数据区337 if ( m_bInit )338 {339 Marshal.Copy( bytData, lngAddr, m_pwData, lngSize );340 }341 else342 {343 return 1; //共享内存未初始化344 }345 return 0; //写成功346 }347 }348 internal class FileReader349 {350 const uint GENERIC_READ = 0x80000000;351 const uint OPEN_EXISTING = 3;352 System.IntPtr handle;353 354 [DllImport( "kernel32", SetLastError = true )]355 public static extern System.IntPtr CreateFile(356 string FileName, // file name357 uint DesiredAccess, // access mode358 uint ShareMode, // share mode359 uint SecurityAttributes, // Security Attributes360 uint CreationDisposition, // how to create361 uint FlagsAndAttributes, // file attributes362 int hTemplateFile // handle to template file363 );364 365 [System.Runtime.InteropServices.DllImport( "kernel32", SetLastError = true )]366 static extern bool CloseHandle367 (368 System.IntPtr hObject // handle to object369 );370 371 372 373 public IntPtr Open( string FileName )374 {375 // open the existing file for reading 376 handle = CreateFile377 (378 FileName,379 GENERIC_READ,380 0,381 0,382 OPEN_EXISTING,383 0,384 0385 );386 387 if ( handle != System.IntPtr.Zero )388 {389 return handle;390 }391 else392 {393 throw new Exception( "打开文件失败" );394 }395 }396 397 public bool Close()398 {399 return CloseHandle( handle );400 }401 }402 }
157 //}158 159 }160 }161 /// <summary>162 /// 获取高32位163 /// </summary>164 /// <param name="intValue"></param>165 /// <returns></returns>166 private static uint GetHighWord( UInt64 intValue )167 {168 return Convert.ToUInt32( intValue >> 32 );169 }170 /// <summary>171 /// 获取低32位172 /// </summary>173 /// <param name="intValue"></param>174 /// <returns></returns>175 private static uint GetLowWord( UInt64 intValue )176 {177 178 return Convert.ToUInt32( intValue & 0x00000000FFFFFFFF );179 }180 181 /// <summary>182 /// 获取下一个文件块 块大小为20M183 /// </summary>184 /// <returns>false 表示已经是最后一块文件</returns>185 public uint GetNextblock()186 {187 if ( !this.m_bInit ) throw new Exception( "文件未初始化。" );188 //if ( m_offsetBegin + m_MemSize >= m_FileSize ) return false;189 190 uint m_Size = GetMemberSize();191 if ( m_Size == 0 ) return m_Size;192 193 // 更改缓冲区大小194 m_MemSize = m_Size;195 196 //卸载前一个文件197 //bool l_result = UnmapViewOfFile( m_pwData );198 //m_pwData = IntPtr.Zero;199 200 201 m_pwData = MapViewOfFile( m_hSharedMemoryFile, FILE_MAP_READ, GetHighWord( ( UInt64 )m_offsetBegin ), GetLowWord( ( UInt64 )m_offsetBegin ), m_Size );202 if ( m_pwData == IntPtr.Zero )203 {204 m_bInit = false;205 throw new Exception( "映射文件块失败" + GetLastError().ToString() );206 }207 m_offsetBegin = m_offsetBegin + m_Size;208 209 return m_Size; //创建成功210 }211 /// <summary>212 /// 返回映射区大小213 /// </summary>214 /// <returns></returns>215 private uint GetMemberSize()216 {217 if ( m_offsetBegin >= m_FileSize )218 {219 return 0;220 }221 else if ( m_offsetBegin + m_MemSize >= m_FileSize )222 {223 long temp = m_FileSize - m_offsetBegin;224 return ( uint )temp;225 }226 else227 return m_MemSize;228 }229 230 /// <summary>231 /// 关闭内存映射232 /// </summary>233 public void Close()234 {235 if ( m_bInit )236 {237 UnmapViewOfFile( m_pwData );238 CloseHandle( m_hSharedMemoryFile );239 File.Close();240 }241 }242 243 /// <summary>244 /// 从当前块中获取数据245 /// </summary>246 /// <param name="bytData">数据</param>247 /// <param name="lngAddr">起始数据</param>248 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>249 /// <param name="Unmap">读取完成是否卸载缓冲区</param>250 /// <returns></returns>251 public void Read( ref byte[] bytData, int lngAddr, int lngSize, bool Unmap )252 {253 if ( lngAddr + lngSize > m_MemSize )254 throw new Exception( "Read操作超出数据区" );255 if ( m_bInit )256 {257 // string bb = Marshal.PtrToStringAuto(m_pwData);//258 Marshal.Copy( m_pwData, bytData, lngAddr, lngSize );259 }260 else261 {262 throw new Exception( "文件未初始化" );263 }264 265 if ( Unmap )266 {267 bool l_result = UnmapViewOfFile( m_pwData );268 if ( l_result )269 m_pwData = IntPtr.Zero;270 }271 }272 273 /// <summary>274 /// 从当前块中获取数据275 /// </summary>276 /// <param name="bytData">数据</param>277 /// <param name="lngAddr">起始数据</param>278 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>279 /// <exception cref="Exception: Read操作超出数据区"></exception>280 /// <exception cref="Exception: 文件未初始化"></exception>281 /// <returns></returns>282 public void Read( ref byte[] bytData, int lngAddr, int lngSize )283 {284 if ( lngAddr + lngSize > m_MemSize )285 throw new Exception( "Read操作超出数据区" );286 if ( m_bInit )287 {288 Marshal.Copy( m_pwData, bytData, lngAddr, lngSize );289 }290 else291 {292 throw new Exception( "文件未初始化" );293 }294 }295 296 /// <summary>297 /// 从当前块中获取数据298 /// </summary>299 /// <param name="lngAddr">缓存区偏移量</param>300 /// <param name="byteData">数据数组</param>301 /// <param name="StartIndex">数据数组开始复制的下标</param>302 /// <param name="lngSize">数据长度,最大值=缓冲长度</param>303 /// <exception cref="Exception: 起始数据超过缓冲区长度"></exception>304 /// <exception cref="Exception: 文件未初始化"></exception>305 /// <returns>返回实际读取值</returns>306 public uint ReadBytes( int lngAddr, ref byte[] byteData, int StartIndex, uint intSize )307 {308 if ( lngAddr >= m_MemSize )309 throw new Exception( "起始数据超过缓冲区长度" );310 311 if ( lngAddr + intSize > m_MemSize )312 intSize = m_MemSize - ( uint )lngAddr;313 314 if ( m_bInit )315 {316 IntPtr s = new IntPtr( ( long )m_pwData + lngAddr ); // 地址偏移317 Marshal.Copy( s, byteData, StartIndex, ( int )intSize );318 }319 else320 {321 throw new Exception( "文件未初始化" );322 }323 324 return intSize;325 }326 327 /// <summary>328 /// 写数据329 /// </summary>330 /// <param name="bytData">数据</param>331 /// <param name="lngAddr">起始地址</param>332 /// <param name="lngSize">个数</param>333 /// <returns></returns>334 private int Write( byte[] bytData, int lngAddr, int lngSize )335 {336 if ( lngAddr + lngSize > m_MemSize ) return 2; //超出数据区337 if ( m_bInit )338 {339 Marshal.Copy( bytData, lngAddr, m_pwData, lngSize );340 }341 else342 {343 return 1; //共享内存未初始化344 }345 return 0; //写成功346 }347 }348 internal class FileReader349 {350 const uint GENERIC_READ = 0x80000000;351 const uint OPEN_EXISTING = 3;352 System.IntPtr handle;353 354 [DllImport( "kernel32", SetLastError = true )]355 public static extern System.IntPtr CreateFile(356 string FileName, // file name357 uint DesiredAccess, // access mode358 uint ShareMode, // share mode359 uint SecurityAttributes, // Security Attributes360 uint CreationDisposition, // how to create361 uint FlagsAndAttributes, // file attributes362 int hTemplateFile // handle to template file363 );364 365 [System.Runtime.InteropServices.DllImport( "kernel32", SetLastError = true )]366 static extern bool CloseHandle367 (368 System.IntPtr hObject // handle to object369 );370 371 372 373 public IntPtr Open( string FileName )374 {375 // open the existing file for reading 376 handle = CreateFile377 (378 FileName,379 GENERIC_READ,380 0,381 0,382 OPEN_EXISTING,383 0,384 0385 );386 387 if ( handle != System.IntPtr.Zero )388 {389 return handle;390 }391 else392 {393 throw new Exception( "打开文件失败" );394 }395 }396 397 public bool Close()398 {399 return CloseHandle( handle );400 }401 }402 }