刘慈欣的自动作诗机核口算法
刘慈欣的自动作诗机核心算法?这是科幻作家刘慈欣早年用vb写的作品。像这种遣词造句的算法是怎样实现的,请大
刘慈欣的自动作诗机核心算法?
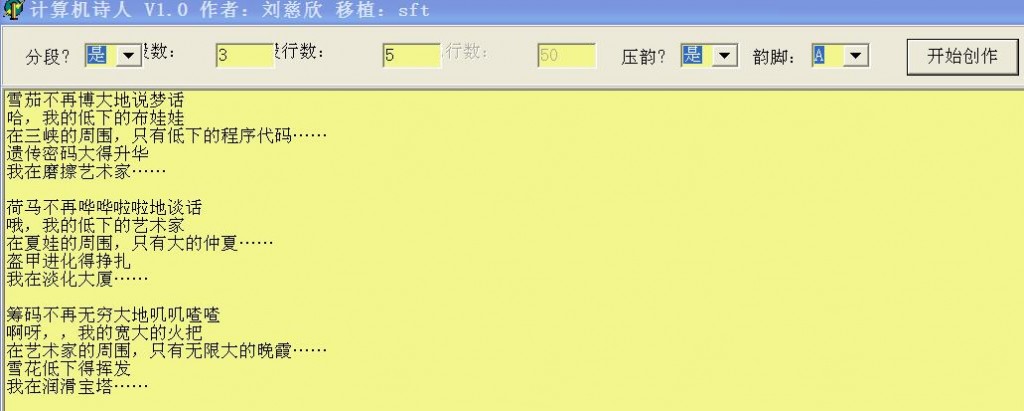
这是科幻作家刘慈欣早年用vb写的作品。像这种遣词造句的算法是怎样实现的,请大牛们指教。
[解决办法]
就是从现代诗歌里挑出若干个标准范型,如上面就是很明显的:
一切都在【动】着,只有XX在【动】
【名】在【动】【名】
到处都是【形】的【名】和【形】的【名】
【叹】,【名】
从【形】的【名】到【形】的【名】……
【叹】,这【形】的【名】啊!
我们都是【形】的【名】,我们要【动】!
你是我的【名】,我是你的【名】
把这些作为模板1,模板2,保存起来供随机调用(也可以让用户选择,只是失去了一点神秘性)。
然后从分类定性好的词库里按照是否押韵的要求随机查找符合的结果进行填空就是了。
这个表面神奇,其实根本就没有任何算法可言。
[解决办法]
这种东西的随机根本用不着多严格,每首诗只要发出一个随机数就可以了,然后给SELECT加两个TOP,用之前得到的随机数与它加上数量所得到的下一个数作区间截取符合词性要求记录,比如名词有三个,截取出从随机位置开始的三个连续记录就行,其他词性同样办理,效率上没什么问题。
你以为这种问题用得着运用什么神经网络算法?
[解决办法]数据库里的文字记录,尤其是多字词,根本不象数字1,2,3那样能看出是连续的,尤其是你还要加上是否压韵,压哪种韵这种条件,所以从符合WHERE条件的记录中某一处选择连续几条记录(就是两个TOP所确立的段),结果根本看不出是连续的。就算偶尔出现了能让人认为是连续的感觉,那对于诗来说,正好产生了一定的关联性。对现代诗来说,本来有时候就完全没有逻辑可言,作者们更不希望被什么逻辑限制,你还想加入什么额外算法呢?那就画蛇添足了。
[解决办法]可能你想增加更多组合的可能,比如这次是“A,B,C”,过后你还希望出现“A,E,G”的其它组合。
可是词库那么多,第一个词出现同样结果的时候都很少,何况你统计过那个自动作诗机有多少这样的不同组合吗?如果你确实发现它的效率比这种方法更好,还能出现局部相同结果的不同组合,再说吧。
