如何使用火车头采集器
?2、 以软件里自带的Discuz!X 2.0论坛 为模板进行修改。我试过了可以正常住Discuz!X 2.5发布文章。
?3、 设置为:对 [标签: 内容]做 UBB转换,如下图中的样子: 最后,另存为一个新的“发布模块”,起一个新名字,后面要使用。
?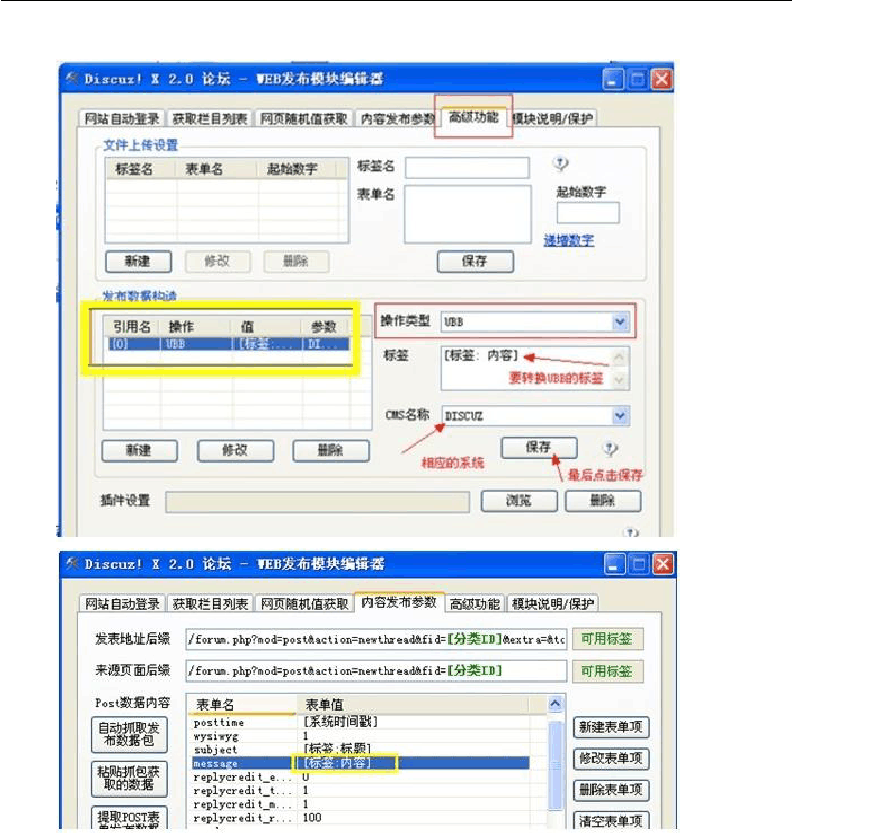
?4、在“内容发布参数”选项卡中修改: [标签: 内容] 的值可以用使用{0} 来替代。如上图
黄色框内的[标签: 内容]替换成{0} ?,
?
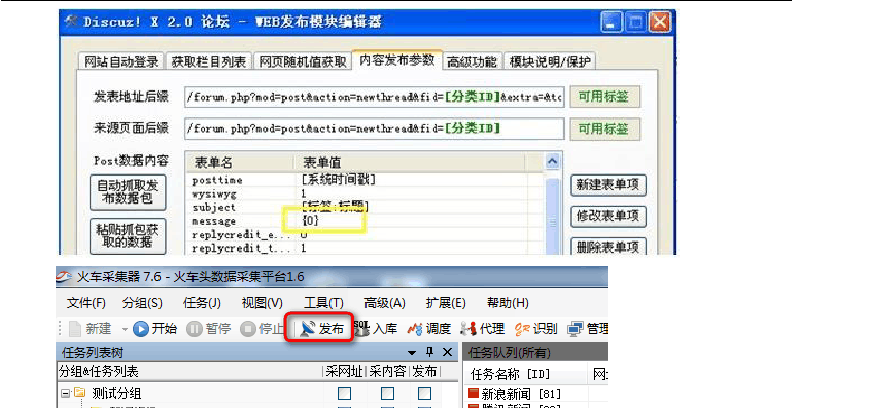
?第一部分工作就完成了。?
二、使用Web在线发布模块?
前面我新建了一个新的Web在线发布模块,下面就是使用它。 第一步:新一个“发布”,操作如上图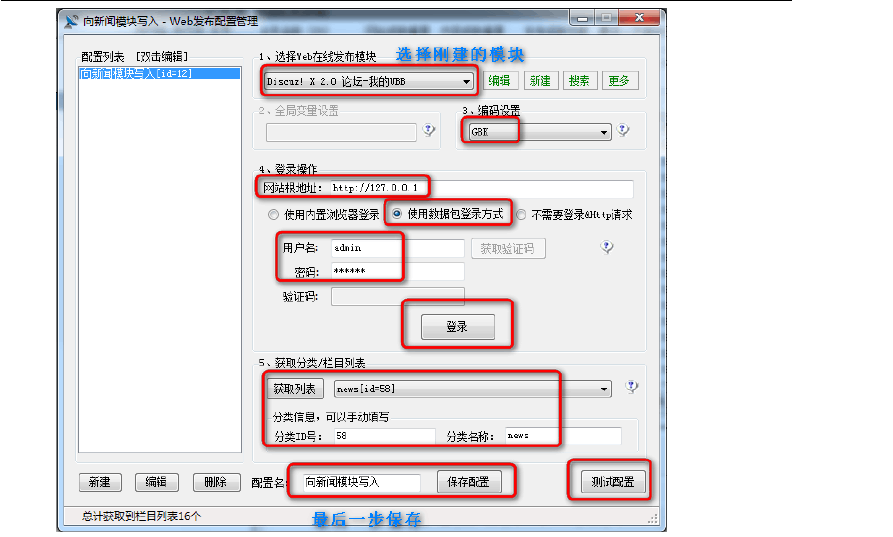
?注意:请到论坛的后台修改设置,要求登录时不需要输入验证码,才能登录成功,才能测试成功,记得以后要改回来啊。?
最后保存时要起个新名字。
?
三、准备采集?
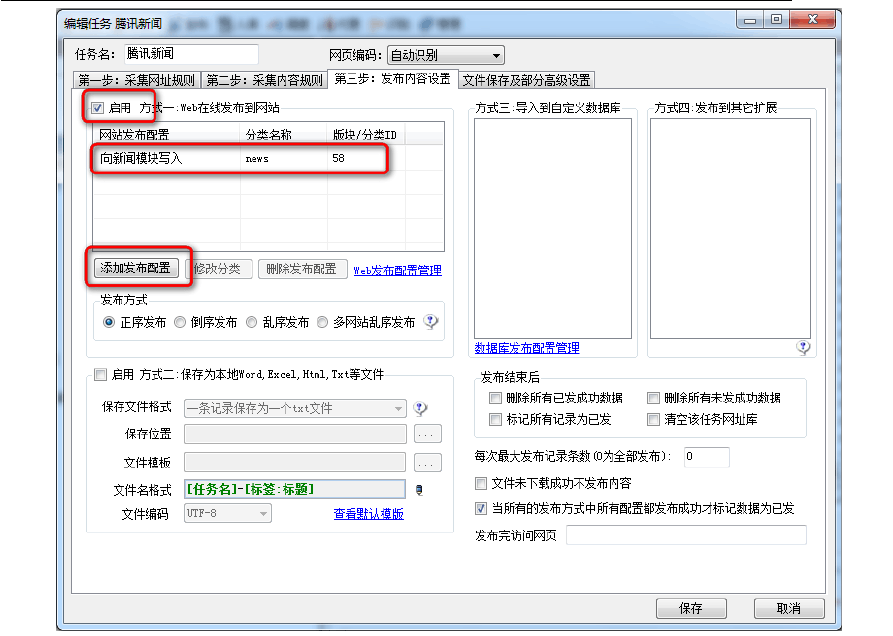
这里以火车自带的采集演示来说明 。鼠标右击“腾讯新闻”—“编辑任务”,打开如下窗口。 如下图设置,使用前一步 ?建立 的“发布模块”,可以把采集到的内容发布到论坛的某个栏目中。 ?
设置如下图:
?
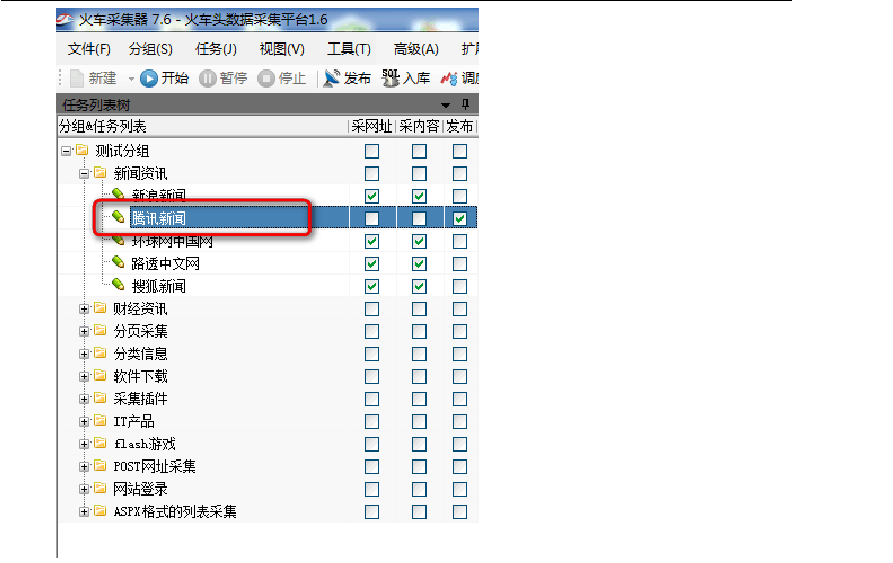
还有下图
?
?7?
对于采集工作,还有一些重要的设置,很重要。?
如果你不是使用火车头自带的演示任务,而是自己新建采集任务,下面的内容就很重要。 ?
下面的设置,是对采集的文章正文进行的设置。?
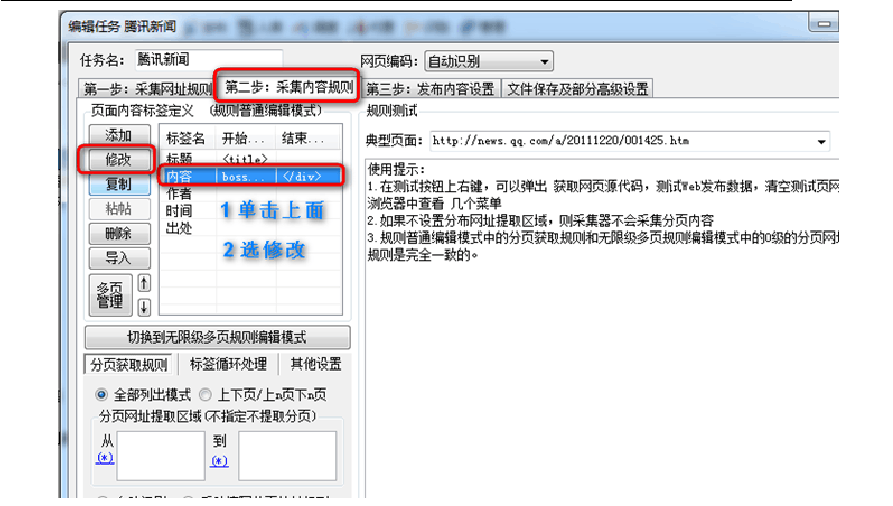
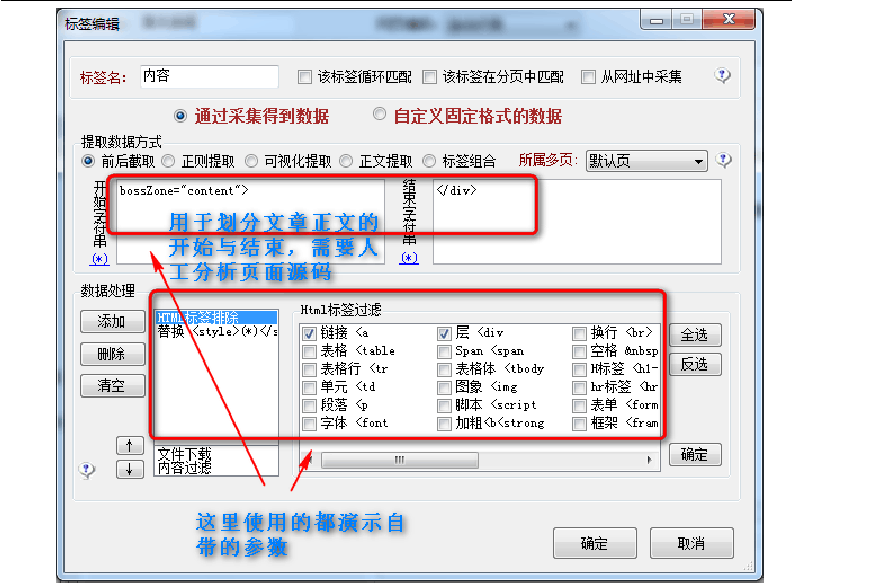
?“开始字符串”,“结束字符串”是所有设置中最重要的内容,它用来分析页面的HTML源码,找出文章正文的开始点与结束点。下图中使用的是火车头为腾讯准备默认值,不需要修改。 ?如果你不采集腾讯而采其它网站,这个就要你自己看HTML源码来人工分析了。 ?
采集时,可选择性的过滤掉一些HTML标签,如<script><iframe>, 如果你不知道要去掉哪些,就什么也不用改,使用默认值吧。
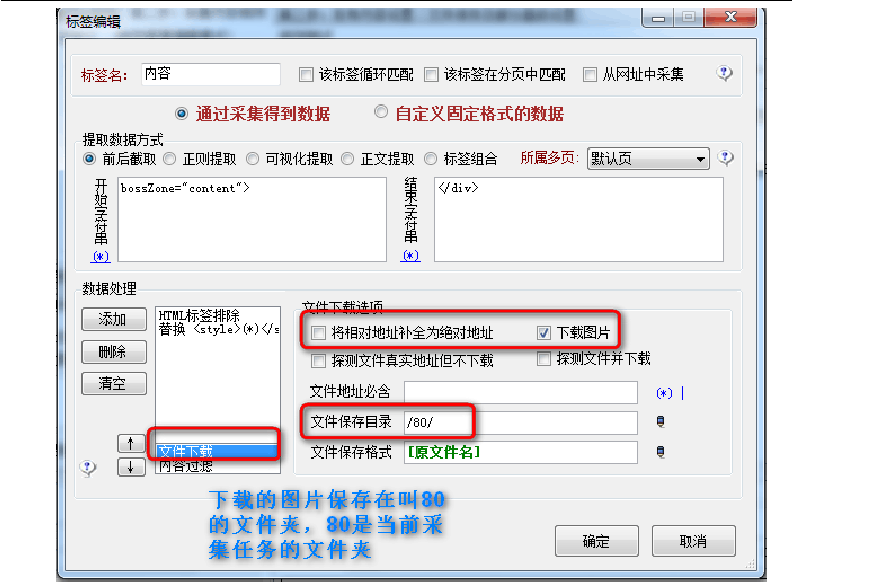
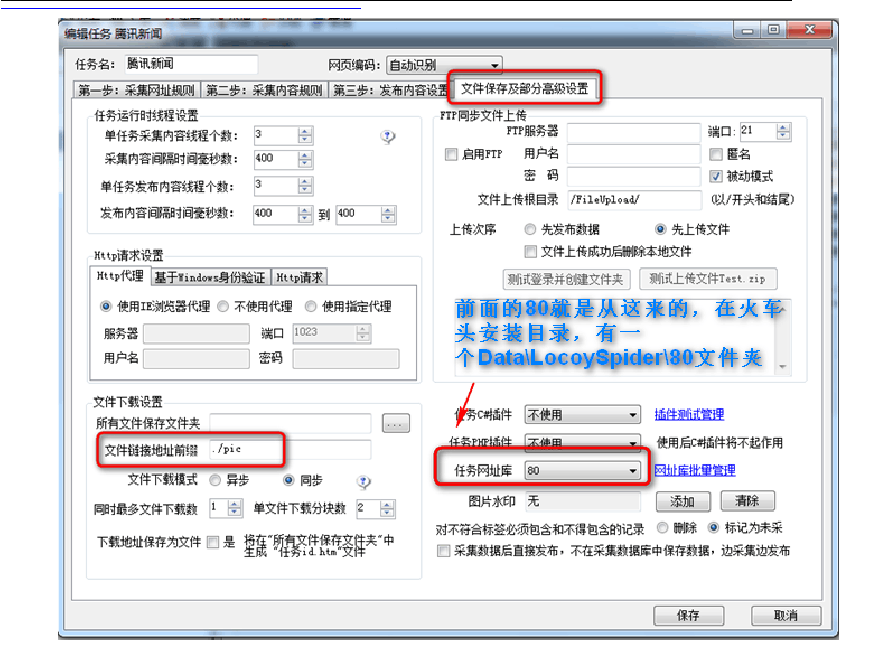
?下载的图片存目录设置?
图片下载后被保存在:?
火车头软件安装目录\Data\LocoySpider\80\ ?文件夹中。?
为什么叫80,其实叫什么都可以,但为了方便管理,这个腾讯采集任务编号是80,所以放在80文件夹中。以后是腾讯采集任务,采集下来图片都放在这里,方便管理。 ?
腾讯采集任务编号,请再后面一张图片中查看
?
客户通过浏览器访问我论坛的文章里的图片时,统一访问服务器上DZ程序的根目录下的./pic/目录,使用相对路径,pic目录下面我们再新建一个80目录, ?所以,把火车头安装目录下的\Data\LocoySpider\中的 80 文件夹,COPY到服务器DZ程序的根目录下的pic目录中, ?这样,图片就存储在了:服务器DZ程序的根目录\pic\80\ ?目录?
?
同时 ?文章中的图片的地址是指向 ?./pic/80/xxx.jpg ? 。文章就可以显示图片了。?
?
补充:后来经过实践,目录定为:/data/attachment/pic ? ,好处是:为了通过程序取文章中的第一张图片做为文章的“封面”,这个路径是合适的。