分布式系统概述(Hadoop与HBase的前生今世)
古代,人们用牛来拉重物。当一头牛拉不动一根圆木时,他们不曾想过培育更大更壮的牛。
同样:我们也不需要尝试开发超级计算机,而应试着结合使用更多计算机系统。
—— Grace Hopper(计算机软件第一夫人,计算机历史上第一个BUG的发现者,也是史上最大BUG千年虫的制造者)
这就是分布式。
?
?
再来看一组令人瞠目结舌的数据:
2012年11月11日
支付宝总交易额191亿元,订单1亿零580万笔,生成15TB日志,访问1931亿次内存数据块,13亿个物理读……
从上面的资料中我们看到了:高性能!高并发!高一致性!高可用性!海量数据!
这就是海量数据处理。远远超出单台计算机的能力范畴。
这就是分布式集群能力的体现,更说明了采用分布式系统的必要性。
?
单台设备的性能、资源、可扩展性等限制 —— 分布式系统(Hadoop)
传统关系型数据库在面对海量数据时的乏力 —— 分布式数据库(HBase)
关系型数据库,顾名思义,善于处理数据模型间复杂的关系、逻辑、事务。
但在处理海量数据时速度、并发量、可扩展性却惨不忍睹。
当然,我们可以通过巧妙的设计与二次开发来解决上述问题。
速度:分表(减少单表数据量)、缓存查询、静态预生成、提高硬件性能。
并发量:打破单机(或双机)模式,组建数据库集群。
可扩展性:复杂的数据迁移方案。
这个过程想必相当痛苦,而且由于技术约束,造成的用户体验也不够好。
比如我们查银行账单、手机话费的历史记录,总要先选择指定的月份或时间范围,然后点提交。
这就是分表带来的用户体验下降。
?
而在原生的分布式系统中,整个集群的节点间共享计算、存储、IO资源,完美的解决了性能、并发、数据存储问题。
看一组关于Google的资料(约在2010年):
Google共有36个数据中心。其中美国有19个、欧洲12个、俄罗斯1个、南美1个和亚洲3个(北京-Google.cn<这个……>、香港-Google.com.hk和东京各1个)。
数据中心以集装箱为单位,每个数据中心有众多集装箱,每个集装箱里面有1160台服务器。
如何使这么多台服务器协同工作?
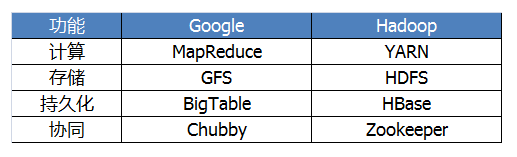
Google的三大核心元素:
1、Google文件系统(GFS)
2、Google大表;Bigtable:是Google一种对于半结构化数据进行分布存储与访问的接口或服务);由于Google的文件系统异常庞大,以至于甲骨文和IBM公司的商业数据库在方面无用武之地。另外,商业数据库都是按 CPU数量来收费,如果Google使用商业数据库,可想而知,这是一笔天文数字。所以,Google量体裁衣地设计了符合自身的大表。
3、Mapreduce 算法;它是Google开发的C++编程工具,用于大于1TB数据的大规模数据集并行运算。MapReduce能够找出一个词语在Google搜索目录中 出现的次数;一系列网页中特定词语出现的频率;链接到某个特定网站的所有网站数量等。
好用的东西,总能找到对应的开源实现,这就是Hadoop。
?
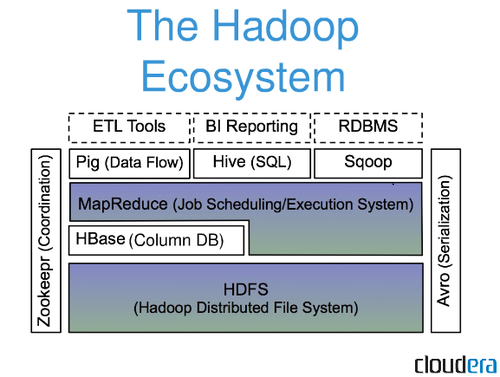
其中:
Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据
Hive,可以使用类似SQL语言来访问HBase,最终本质是编译成MapReduce Job来处理HBase表数据,适合做数据统计。
?
Amazon、Adobe、Ebay、Facebook、Twitter、Yahoo、IBM……
国内:淘宝和支付宝的数据仓库、华为、百度的搜索日志分析,腾讯……
这里有更多的资料可查?http://wiki.apache.org/hadoop/PoweredBy
Facebook实时消息存储系统于2010年下半年迁移到了HBase。
?
2006 年末 —— Google “BigTable: A Distributed Storage System for Structured Data”;
2007 02月 —— HBase的源代码初稿;
2007 10月 —— 第一个版本,随Hadoop 0.15.0 捆绑发布;
2010 05月 —— HBase从Hadoop子项目升级成Apache顶层项目;
?
HBase是一个在Hadoop上开发的面向列(同类软件还有Cassandra和HyperTable)的分布式数据库。
利用HDFS作为其文件存储系统
利用MapReduce来处理HBase中的海量数据
利用Zookeeper作为协同服务,主要用于实时随机读/写超大规模数据集
很多关系型数据库为了应对这种场景提供了复制(replication)和分区(partitioning)解决方案,让数据库能从单个节点上扩展出去。
但是难以安装和维护,且需要牺牲一些重要的RDBMS(Relational DataBase Management System)特性,连接、复杂查询、触发器、视图以及外键约束这些功能要么运行开销大,要么根本无法使用。
HBase从另一个方向来解决可伸缩性的问题。它自底向上的进行构建,能够简单的通过增加节点来达到线性扩展。
HBase并不是关系型数据库,它不支持SQL,但它能够做RDBMS不能做的事;
在廉价硬件构成的集群上管理超大规模的稀疏表。
?
面向列:列的动态、无限扩展 —— 内容评论的扩展,同类数据集中存储便于压缩
稀疏表:有数据时这个单元格才存在 —— 节省空间
?

? Row Key: 行键,Table的主键,Table中的记录按照Row Key排序
? Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的version number
? Column Family:列簇,Table在水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成,即Column Family支持动态扩展,无需预先定义Column的数量以及类型,所有Column均以二进制格式存储,用户需要自行进行类型转换。
?
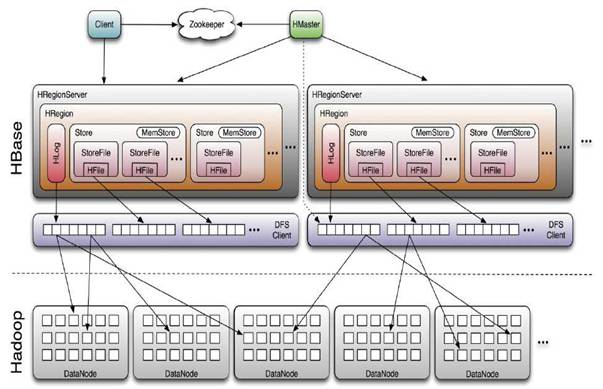
HBase的组件构成
HMaster (HA),负责Table和Region的管理工作
1、建表、删表、查看表格属性;
2、管理RegionServer负载均衡,调整Region分布;
3、Region Split后,负责新Region的分配;
4、在RegionServer失效后,负责失效节点上的Regions迁移;
RegionServer(x N),主要负责响应用户I/O请求,向HDFS文件系统中读写数据
?
一张表存储在[1-N)个HRegion中,每个HRegion保存某张表RowKey连续的一段记录。
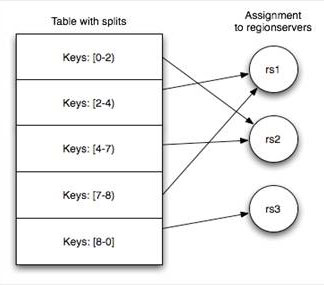
建表时可以预划分HRegion——提高并行度,进而提升读写速度
否则初始表存在单一HRegion中,随着数据增大HRegion会分裂为多个HRegion
HBase中有两张特殊的Table,-ROOT-和.META.
? ?.META.:记录了用户表的Region信息,.META.可以有多个regoin
? ?-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region
? ?Zookeeper中记录了-ROOT-表的location
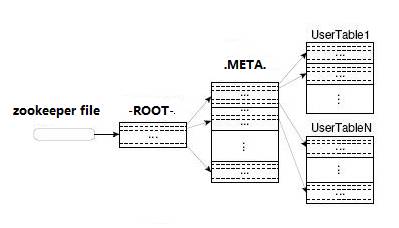
首先 HBase Client端会连接Zookeeper Qurom
通过 Zookeeper组件Client 能获知哪个 RegionServer管理-ROOT- Region 。
那么Client就去访问管理 -ROOT-的HRegionServer ,在META中记录了 HBase中所有表信息,(你可以使用 ? scan '.META.' 命令列出你创建的所有表的详细信息 ),从而获取Region 分布的信息。一旦 Client获取了这一行的位置信息,比如这一行属于哪个 Region,Client 将会缓存这个信息并直接访问 HRegionServer。
久而久之Client 缓存的信息渐渐增多,即使不访问 .META.表 也能知道去访问哪个 HRegionServer。
HBase读数据
HBase读取数据优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据,提高数据读取的性能。
HBase写数据
HBase写入数据会写到HMemcache和Hlog中,HMemcache建立缓存,Hlog同步Hmemcache和Hstore的事务日志,发起Flush Cache时,数据持久化到Hstore中,并清空HMemecache。
?
?
原文:http://blog.csdn.net/pirateleo/article/details/7956965