Nginx����ԭ�����Ż�
http://blog.csdn.net/hguisu/article/details/8930668
?
1. ?Nginx��ģ���빤��ԭ��
Nginx���ں˺�ģ����ɣ����У��ں˵���Ʒdz�С�ͼ�࣬��ɵĹ���Ҳ�dz�������ͨ�����������ļ����ͻ�������ӳ�䵽һ��location block��location��Nginx�����е�һ��ָ�����URLƥ�䣩���������location�������õ�ÿ��ָ���������ͬ��ģ��ȥ�����Ӧ�Ĺ�����
Nginx��ģ��ӽṹ�Ϸ�Ϊ����ģ�顢����ģ��͵�����ģ�飺
����ģ�飺HTTPģ�顢EVENTģ���MAILģ��
����ģ�飺HTTP Accessģ�顢HTTP FastCGIģ�顢HTTP Proxyģ���HTTP Rewriteģ�飬
������ģ�飺HTTP Upstream Request Hashģ�顢Noticeģ���HTTP Access Keyģ�顣
�û������Լ�����Ҫ������ģ�鶼���ڵ�����ģ�顣����������ô��ģ���֧�ţ�Nginx�Ĺ��ܲŻ����ǿ��
Nginx��ģ��ӹ����Ϸ�Ϊ�������ࡣ
Handlers��������ģ�飩������ģ��ֱ�Ӵ�����������������ݺ���headers��Ϣ�Ȳ�����Handlers������ģ��һ��ֻ����һ����
Filters ��������ģ�飩������ģ����Ҫ������������ģ����������ݽ����IJ����������Nginx�����
Proxies ��������ģ�飩������ģ����Nginx��HTTP Upstream֮���ģ�飬��Щģ����Ҫ����һЩ�������FastCGI�Ƚ��н�����ʵ�ַ���������ؾ���ȹ��ܡ�
ͼ1-1չʾ��Nginxģ�鳣���HTTP�������Ӧ�Ĺ��̡�
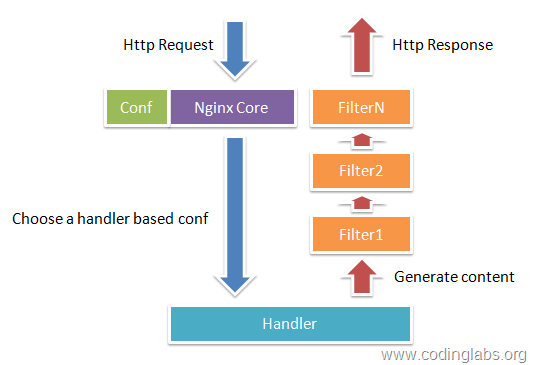
? ? ? ? ? ? ? ? ? ? ? ?ͼ1-1չʾ��Nginxģ�鳣���HTTP�������Ӧ�Ĺ��̡�
Nginx�������Ĺ���ʵ�ʺ��٣������ӵ�һ��HTTP����ʱ����������ͨ�����������ļ����˴�����ӳ�䵽һ��location block������location�������õĸ���ָ�����������ͬ��ģ��ȥ��ɹ��������ģ����Կ���Nginx�������Ͷ������ߡ�ͨ��һ��location�е�ָ����漰һ��handlerģ��Ͷ��filterģ�飨��Ȼ�����location���Ը���ͬһ��ģ�飩��handlerģ�鸺�������������Ӧ���ݵ����ɣ���filterģ�����Ӧ���ݽ��д�����
Nginx��ģ��ֱ�ӱ������Nginx��������ھ�̬���뷽ʽ������Nginx��Nginx��ģ�鱻�Զ����أ�����Apache�����Ƚ�ģ�����Ϊһ��so�ļ���Ȼ���������ļ���ָ���Ƿ���м��ء��ڽ��������ļ�ʱ��Nginx��ÿ��ģ�鶼�п���ȥ����ij��������ͬһ����������ֻ����һ��ģ������ɡ�?
�ڹ�����ʽ�ϣ�Nginx��Ϊ���������̺Ͷ����������ģʽ���ڵ���������ģʽ�£����������⣬����һ���������̣����������ǵ��̵߳ģ��ڶ������ģʽ�£�ÿ���������̰�������̡߳�NginxĬ��Ϊ����������ģʽ��
?
?
2. ?Nginx+FastCGI����ԭ��
?
FastCGI��һ���������ء����ٵ���HTTP server�Ͷ�̬�ű����Լ�ͨ�ŵĽӿڡ��������е�HTTP server��֧��FastCGI������Apache��Nginx��lighttpd�ȡ�ͬʱ��FastCGIҲ������ű�����֧�֣����о���PHP��
FastCGI�Ǵ�CGI��չ�Ľ������ġ���ͳCGI�ӿڷ�ʽ����Ҫȱ�������ܺܲ��Ϊÿ��HTTP������������̬����ʱ����Ҫ���������ű���������ִ�н�����Ȼ������ظ�HTTP�����������ڴ����߲�������ʱ�����Dz����õġ����ͳ��CGI�ӿڷ�ʽ��ȫ��Ҳ�ܲ�����Ѿ�����ʹ���ˡ�
FastCGI�ӿڷ�ʽ����C/S�ṹ�����Խ�HTTP�������ͽű������������ֿ���ͬʱ�ڽű�����������������һ�����߶���ű������ػ����̡���HTTP������ÿ��������̬����ʱ�����Խ���ֱ�ӽ�����FastCGI������ִ�У�Ȼ�õ��Ľ�����ظ�����������ַ�ʽ������HTTP������רһ�ش�����̬������߽���̬�ű��������Ľ�����ظ��ͻ��ˣ����ںܴ�̶������������Ӧ��ϵͳ�����ܡ�
Nginx��֧�ֶ��ⲿ�����ֱ�ӵ��û��߽��������е��ⲿ������PHP������ͨ��FastCGI�ӿ������á�FastCGI�ӿ���Linux����socket�����socket�������ļ�socket��Ҳ������ip socket����
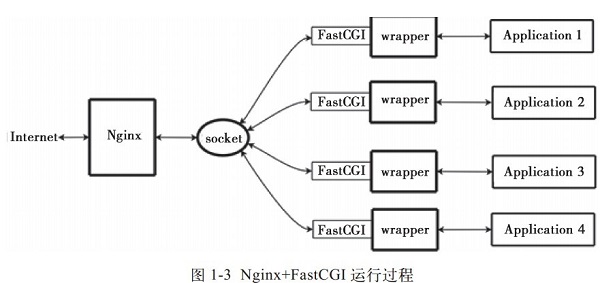
wrapper��Ϊ�˵���CGI������Ҫһ��FastCGI��wrapper��wrapper��������Ϊ����������һ������ij������wrapper����ij���̶�socket�ϣ���˿ڻ����ļ�socket����Nginx��CGI���������socket��ʱ��ͨ��FastCGI�ӿڣ�wrapper���յ�����Ȼ��Fork(��������һ���µ��̣߳�����̵߳��ý����������ⲿ�������ű�����ȡ�������ݣ����ţ�wrapper�ٽ����ص�����ͨ��FastCGI�ӿڣ����Ź̶���socket���ݸ�Nginx�����Nginx�����ص����ݣ�htmlҳ�����ͼƬ�������ͻ��ˡ������Nginx+FastCGI�������������̣���ͼ1-3��ʾ��
? ? ? ?
?
?
? ? ? ���ԣ�����������Ҫһ��wrapper�����wrapper��Ҫ��ɵĹ�����
?????����nginx֧�ֵ��¼�ģ�����£�nginx��wiki��:
?????? Nginx֧�����´������ӵķ�����I/O���÷���������Щ��������ͨ��useָ��ָ����
select?�C �������� �����ǰƽ̨û�и���Ч�ķ��������DZ���ʱĬ�ϵķ����������ʹ�����ò��� �Cwith-select_module �� �Cwithout-select_module �����û�������ģ�顣poll?�C �������� �����ǰƽ̨û�и���Ч�ķ��������DZ���ʱĬ�ϵķ����������ʹ�����ò��� �Cwith-poll_module �� �Cwithout-poll_module �����û�������ģ�顣kqueue?�C ��Ч�ķ�����ʹ���� FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0 �� MacOS X. ʹ��˫��������MacOS Xϵͳʹ��kqueue���ܻ�����ں˱�����epoll?�C ��Ч�ķ�����ʹ����Linux�ں�2.6�汾���Ժ��ϵͳ����ijЩ���а汾�У���SuSE 8.2, ����2.4�汾���ں�֧��epoll�IJ�����rtsig?�C ��ִ�е�ʵʱ�źţ�ʹ����Linux�ں˰汾2.2.19�Ժ��ϵͳ��Ĭ�����������ϵͳ�в��ܳ��ִ���1024��POSIXʵʱ(�Ŷ�)�źš�������� ���ڸ߸��صķ�������˵�ǵ�Ч�ģ������б�Ҫͨ�������ں˲��� /proc/sys/kernel/rtsig-max �����Ӷ��еĴ�С�����Ǵ�Linux�ں˰汾2.6.6-mm2��ʼ�� ��������Ͳ���ʹ���ˣ����Ҷ���ÿ��������һ���������źŶ��У�������еĴ�С������ RLIMIT_SIGPENDING �������ڡ���������й���ӵ����nginx�ͷ��������ҿ�ʼʹ�� poll ��������������ֱ���ָ�������/dev/poll?�C ��Ч�ķ�����ʹ���� Solaris 7 11/99+, HP/UX 11.22+ (eventport), IRIX 6.5.15+ �� Tru64 UNIX 5.1A+.eventport?�C ��Ч�ķ�����ʹ���� Solaris 10. Ϊ�˷�ֹ�����ں˱��������⣬ �б�Ҫ��װ?���?��ȫ������??????? ��linux���棬ֻ��epoll�Ǹ�Ч�ķ���
??????? ������������epoll��������θ�Ч��
?????? Epoll��Linux�ں�Ϊ������������������˸Ľ���poll�� Ҫʹ��epollֻ��Ҫ������ϵͳ���ã�epoll_create(2)�� epoll_ctl(2)�� epoll_wait(2)��������2.5.44�ں��б�������(epoll(4) is a new API introduced in Linux kernel 2.5.44)����2.6�ں��еõ��㷺Ӧ�á�
??????? epoll���ŵ�
֧��һ�����̴���Ŀ��socket������(FD)??????? select ������ܵ���һ����������FD����һ�����Ƶģ���FD_SETSIZE���ã�Ĭ��ֵ��2048��������Щ��Ҫ֧�ֵ�����������Ŀ��IM��������˵�� Ȼ̫���ˡ���ʱ����һ�ǿ���ѡ���������Ȼ�����±����ںˣ���������Ҳͬʱָ���������������Ч�ʵ��½������ǿ���ѡ�����̵Ľ������(��ͳ�� Apache����)��������Ȼlinux���洴�����̵Ĵ��۱Ƚ�С�����Ծ��Dz��ɺ��ӵģ����Ͻ��̼�����ͬ��Զ�Ȳ����̼߳�ͬ���ĸ�Ч������Ҳ����һ���� ���ķ��������� epoll��û��������ƣ�����֧�ֵ�FD�����������Դ��ļ�����Ŀ���������һ��Զ����2048,�ٸ�����,��1GB�ڴ�Ļ����ϴ�Լ��10���� �ң�������Ŀ����cat /proc/sys/fs/file-max�쿴,һ����˵�����Ŀ��ϵͳ�ڴ��ϵ�ܴ�
IOЧ�ʲ���FD��Ŀ���Ӷ������½�???????? ��ͳ��select/poll��һ������������ǵ���ӵ��һ���ܴ��socket���ϣ���������������ʱ����һʱ��ֻ�в��ֵ�socket�ǡ���Ծ���ģ��� ��select/pollÿ�ε��ö�������ɨ��ȫ���ļ��ϣ�����Ч�ʳ��������½�������epoll������������⣬��ֻ��ԡ���Ծ����socket���в� ����������Ϊ���ں�ʵ����epoll�Ǹ���ÿ��fd�����callback����ʵ�ֵġ���ô��ֻ�С���Ծ����socket�Ż�������ȥ���� callback����������idle״̬socket�ᣬ������ϣ�epollʵ����һ����α��AIO����Ϊ��ʱ���ƶ�����os�ںˡ���һЩ benchmark�У�������е�socket�����϶��ǻ�Ծ�ġ�����һ������LAN������epoll������select/poll��ʲôЧ�ʣ��� �����������ʹ��epoll_ctl,Ч����Ȼ��������½�������һ��ʹ��idle connectionsģ��WAN����,epoll��Ч�ʾ�Զ��select/poll֮���ˡ�
ʹ��mmap�����ں����û��ռ����Ϣ���ݡ�??????? �� ��ʵ�����漰��epoll�ľ���ʵ���ˡ�������select,poll����epoll����Ҫ�ں˰�FD��Ϣ֪ͨ���û��ռ䣬��α��ⲻ��Ҫ���ڴ濽���ͺ� ��Ҫ��������ϣ�epoll��ͨ���ں����û��ռ�mmapͬһ���ڴ�ʵ�ֵġ������������һ����2.5�ں˾�עepoll�Ļ���һ�����������ֹ� mmap��һ���ġ�
�ں���???????? ��һ����ʵ����epoll���ŵ��ˣ���������linuxƽ̨���ŵ㡣Ҳ������Ի���linuxƽ̨�����������ر�linuxƽ̨���������ں˵����������磬�ں�TCP/IPЭ ��ջʹ���ڴ�ع���sk_buff�ṹ����ô����������ʱ�ڶ�̬��������ڴ�pool(skb_head_pool)�Ĵ�С�� ͨ��echo XXXX>/proc/sys/net/core/hot_list_length��ɡ��ٱ���listen�����ĵ�2������(TCP���3������ �����ݰ����г���)��Ҳ���Ը�����ƽ̨�ڴ��С��̬��������������һ�����ݰ�����Ŀ��ͬʱÿ�����ݰ�������Сȴ��С������ϵͳ�ϳ������µ�NAPI���������ܹ���
??? (epoll���ݣ��ο�epoll_�����ٿ�)
?
4. ? Nginx�Ż�
1��.��СNginx�������ļ���С
�ڱ���Nginxʱ��Ĭ����debugģʽ���У�����debugģʽ�»����ܶ���ٺ�ASSERT֮�����Ϣ��������ɺ�һ��NginxҪ�кü����ֽڡ����ڱ���ǰȡ��Nginx��debugģʽ��������ɺ�Nginxֻ�м���ǧ�ֽڡ���˿����ڱ���֮ǰ�������Դ�룬ȡ��debugģʽ�����巽�����£�
��NginxԴ���ļ�����ѹ���ҵ�Դ��Ŀ¼�µ�auto/cc/gcc�ļ����������ҵ����¼��У�
?
?
ע�͵���ɾ�������У�����ȡ��debugģʽ��
2.Ϊ�ض���CPUָ��CPU���ͱ����Ż�
�ڱ���Nginxʱ��Ĭ�ϵ�GCC��������ǡ�-O����Ҫ�Ż�GCC���룬����ʹ����������������
?
?
Ҫȷ��CPU���ͣ�����ͨ���������
?
TCMalloc��ȫ��ΪThread-Caching Malloc���ǹȸ迪���Ŀ�Դ����google-perftools�е�һ����Ա�������glibc���Malloc��ȣ�TCMalloc�����ڴ����Ч�ʺ��ٶ���Ҫ�ߺܶ࣬���ںܴ�̶�������˷������ڸ߲�������µ����ܣ��Ӷ�������ϵͳ�ĸ��ء�����������ΪNginx����TCMalloc��֧�֡�
Ҫ��װTCMalloc�⣬��Ҫ��װlibunwind��32λ����ϵͳ����Ҫ��װ����google-perftools������������libunwind��Ϊ����64λCPU�Ͳ���ϵͳ�ij����ṩ�˻��������������ͺ������üĴ������ܡ������������TCMalloc�Ż�Nginx�ľ���������̡�
1).��װlibunwind��
���Դ�http://download.savannah.gnu.org/releases/libunwind������Ӧ��libunwind�汾���������ص���libunwind-0.99-alpha.tar.gz����װ�������£�
?
?
2).��װgoogle-perftools
���Դ�http://google-perftools.googlecode.com������Ӧ��google-perftools�汾���������ص���google-perftools-1.8.tar.gz����װ�������£�
?
���ˣ�google-perftools��װ��ɡ�
3).���±���Nginx
Ϊ��ʹNginx֧��google-perftools����Ҫ�ڰ�װ���������ӡ��Cwith-google_perftools_module��ѡ�����±���Nginx����װ�������£�
?
������Nginx��װ��ɡ�
4).Ϊgoogle-perftools�����߳�Ŀ¼
����һ���߳�Ŀ¼�����ォ�ļ�����/tmp/tcmalloc�¡��������£�
?
5).��Nginx�������ļ�
��nginx.conf�ļ�����pid���е������������´��룺
?
���ţ�����Nginx�������google-perftools�ļ��ء�
6).��֤����״̬
Ϊ����֤google-perftools�Ѿ��������أ���ͨ����������鿴��
?
������Nginx�����ļ�������worker_processes��ֵΪ4����˿�����4��Nginx�̣߳�ÿ���̻߳���һ�м�¼��ÿ���߳��ļ����������ֵ����������Nginx��pidֵ��
���ˣ�����TCMalloc�Ż�Nginx�IJ�����ɡ�
?
�ں˲������Ż�����Ҫ����Linuxϵͳ�����NginxӦ�ö����е�ϵͳ�ں˲����Ż���
�������һ���Ż�ʵ���Թ��ο���
?
?
?
��������ں˲���ֵ����/etc/sysctl.conf�ļ��У�Ȼ��ִ����������ʹ֮��Ч��
�����ʵ����ѡ��ĺ�����н��ܣ�
net.ipv4.tcp_max_tw_bucketsѡ�������趨timewait��������Ĭ����180 000��������Ϊ6000��
net.ipv4.ip_local_port_rangeѡ�������趨����ϵͳ�Ķ˿ڷ�Χ��
net.ipv4.tcp_tw_recycleѡ��������������timewait���ٻ��ա�
net.ipv4.tcp_tw_reuseѡ���������ÿ������ã�������TIME-WAIT sockets���������µ�TCP���ӡ�
net.ipv4.tcp_syncookiesѡ���������ÿ���SYN Cookies��������SYN�ȴ��������ʱ������cookies���д�����
net.core.somaxconnѡ���Ĭ��ֵ��128�� ����������ڵ���ϵͳͬʱ�����tcp���������ڸ߲����������У�Ĭ�ϵ�ֵ���ܻᵼ�����ӳ�ʱ�����ش�����ˣ���Ҫ��ϲ��������������ڴ�ֵ��
net.core.netdev_max_backlogѡ���ʾ��ÿ������ӿڽ������ݰ������ʱ��ں˴�����Щ�������ʿ�ʱ���������͵����е����ݰ��������Ŀ��
net.ipv4.tcp_max_orphansѡ�������趨ϵͳ������ж��ٸ�TCP���ֲ����������κ�һ���û��ļ�����ϡ��������������֣��������ӽ���������λ����ӡ��������Ϣ���������ֻ��Ϊ�˷�ֹ��DoS���������ܹ��������������������Ϊ��С���ֵ������������Ӧ���������ֵ��
net.ipv4.tcp_max_syn_backlogѡ�����ڼ�¼��Щ��δ�յ��ͻ���ȷ����Ϣ��������������ֵ��������128MB�ڴ��ϵͳ���ԣ��˲�����Ĭ��ֵ��1024����С�ڴ��ϵͳ����128��
net.ipv4.tcp_synack_retries������ֵ�������ں˷�������֮ǰ����SYN+ACK����������
net.ipv4.tcp_syn_retriesѡ���ʾ���ں˷�����������֮ǰ����SYN����������
net.ipv4.tcp_fin_timeoutѡ����������ֱ�����FIN-WAIT-2״̬��ʱ�䡣Ĭ��ֵ��60�롣��ȷ�������ֵ�dz���Ҫ����ʱ��ʹһ�����غ�С��Web��������Ҳ����ִ����������ֶ������ڴ�����ķ��ա�
net.ipv4.tcp_syn_retriesѡ���ʾ���ں˷�����������֮ǰ����SYN����������
������Ͷ�Ҫ��ر����֣�net.ipv4.tcp_fin_timeoutѡ����������ֱ�����FIN-WAIT-2״̬��ʱ�䡣���ն˿��Գ�������Զ���ر����ӣ���������崻���
net.ipv4.tcp_fin_timeout��Ĭ��ֵ��60�롣��Ҫע����ǣ���ʹһ�����غ�С��Web��������Ҳ�������Ϊ�����������ֶ������ڴ�����ķ��ա�FIN-WAIT-2��Σ���Ա�FIN-WAIT-1ҪС����Ϊ�����ֻ������1.5KB���ڴ棬�����������ڳ�Щ��
net.ipv4.tcp_keepalive_timeѡ���ʾ��keepalive���õ�ʱ��TCP����keepalive��Ϣ��Ƶ�ȡ�Ĭ��ֵ��2����λ��Сʱ����
������߸�����վʹ��PHP-FPM����FastCGI����Щ����Ҳ����������:
1������FastCGI������
��PHP FastCGI�ӽ���������100�����ϣ���4G�ڴ�ķ�������200�Ϳ��Խ���ͨ��ѹ�����Ի�ȡ���ֵ��
2������?PHP-FPM���ļ�������������
��ǩrlimit_files��������PHP-FPM�Դ��ļ������������ƣ�Ĭ��ֵΪ1024�������ǩ��ֵ�����Linux�ں˴��ļ����������������磬Ҫ����ֵ����Ϊ65 535���ͱ�����Linux������ִ�С�ulimit -HSn 65536����
?????? Ȼ��?����?PHP-FPM���ļ�������������:
???? # vi /path/to/php-fpm.conf
??? �ҵ���<valuename="rlimit_files">1024</value>��
��1024����Ϊ?4096���߸���.
����?PHP-FPM.
?
?????????3���ʵ�����max_requests
??? ��ǩmax_requestsָ����ÿ��children��ദ�����ٸ�������ᱻ�رգ�Ĭ�ϵ�������500��
????<value name="max_requests"> 500 </value>