walter的dril笔记之一-简介
Drill:大数据的交互式分析
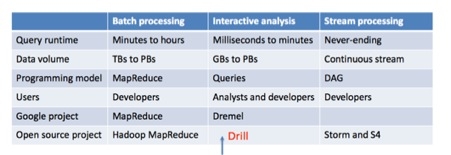
? ? ? ? Dril是开源世界中“交互式”的数据分析系统。目标是可以组建超过10000台机器的集群,并且可以在秒级处理PB级别或者万亿条数据。Hadoop作为大数据处理的事实标准,设计目标是实现大数据处理的高吞吐量。MapReduce处理一个数据,需要分钟级的时间。而业界对交互式的低延迟的数据分析和挖掘提出了新的需求,Google的Dremel希望将处理时间缩短到秒级。当前Dremel已经为Google的bigquery提供服务。Drill作为Google Dremel的开源实现,并非Hadoop的替代品,只是其补充。和Dremel一样,Drill可以高效的处理嵌套式数据格式。此外,Drill加入了额外的特性,支持更广泛的查询语言,数据格式和数据源。
 ?
?
??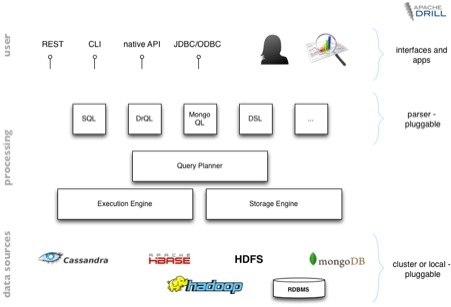
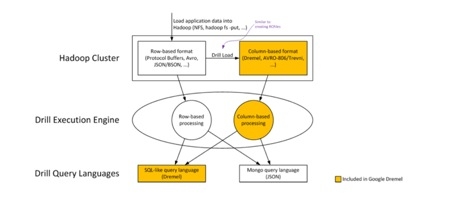
? ? ? ? 现在Drill的已经完成了初始的需求,架构。实现了一个包括一个执行引擎和DrQL的初始系统。和Hadoop一样,Drill想要支持多种存储系统(通过文件系统API)和文件格式(通过输入输出API)。同时,Drill希望支持多种查询语言,数据格式和数据源。
Drill的架构分为了四个组件:
?
? ? ? ? ? ? ? ? ? ?
Milestone 1: 基本功能 2013年9月份已发布
JDBC,分布式执行,Parquet and JSON可读
Milestone 2: 执行时验证
性能,全排序,节点缓存,诊断工具,度量,parquet写
Milestone 3:查询完善
TPC-H, Hive UDF, Hive read SerDe and HBase
Milestone 4:用户交互完善
Pushdown,优化,复杂的向量操作,Hive metastore,额外的文件格式
Milestone 5:产品质量
ODBC,额外的优化器,稳定性,资源调度
?
?
相关资料:相关资料
http://online.liebertpub.com/doi/pdfplus/10.1089/big.2013.0011