使用Hadoop har归档历史文件(小文件)
?申明:本文转自http://heipark.iteye.com/blog/1356063
我们的hdfs中保存大量小文件(当然不产生小文件是最佳实践),这样会把namenode的namespace搞的很大。namespace保存着hdfs文件的inode信息,文件越多需要的namenode内存越大,但内存毕竟是有限的(这个是目前hadoop的硬伤)。
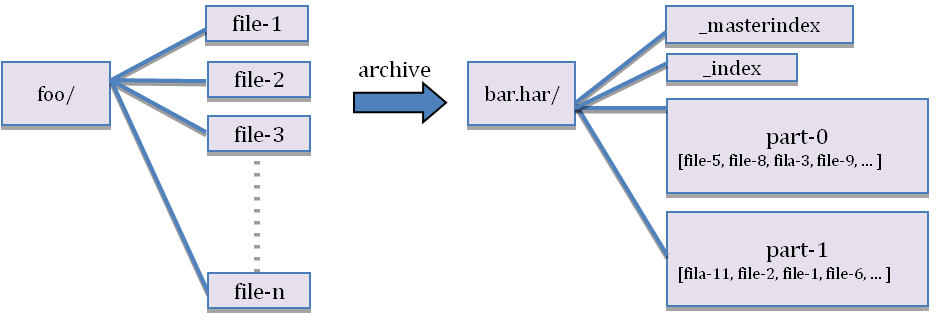
下面图片展示了,har文档的结构。har文件是通过mapreduce生成的,job结束后源文件不会删除。
?
?
?
archive -archiveName NAME -p <parent path> <src>* <dest>?
hadoop archive -archiveName 419.har -p /fc/src/20120116/ 419 /user/heipark?
?
?#使用hdfs文件系统查看har文件?
?
Java代码? ?
?
?
?
参考文章:
http://denqiang.com/?m=20111114
http://c.hocobo.net/2010/08/05/har/