Entity Framework�����ۻ�֮����ȫ��
Entity Framework�����ۻ� ֮
=========================================
����һ��ϵ������
��һƪ��Entity Framework��������ϵ�п�ƪ������ ��
=========================================
������ѧϰij���֮ǰ��Ӧ��Ŭ���γɶԴ˼���������ӡ���˽������ԭ�������ĵ�Ŀ�ľ����ڴˡ�
һ������EF����ģ��EF��������һ��ORM��ܣ�����Ҫ�Ѷ���ӳ�䵽�ײ����ݿ��еı���Ϊ�ˣ���ʹ��������ģ������������ӳ���ϵ��
��1������ģ�ͣ�Conceptual Model������Ҫ����Ϊһ����Ա�Ӧ�ó���ֱ��ʹ�õ��ࡣ��Щ��Ҳ�������ڳ�����ֱ��ʹ�õ��࣬ͨ����֮Ϊ��ʵ�壨Entity����
��2���洢ģ�ͣ�Storage Model������Ҫ����Ϊһ����ײ����ݴ洢���ʣ��������ݿ�ϵͳ��ֱ�Ӷ�Ӧ���ࡣ
��3������-�洢ģ��ӳ�䣨Conceptual- Storage Mapping�������������ģ�͡��е�������롰�洢ģ�͡��е������Ӧ�����⡣
��2���ͣ�3���е�������EF�ڲ�ʹ�ã���ʵ�ʿ�����ͨ������������
����������ģ�Ͷ����з�����Ϊedmx�ļ��У���XML��ʽ���
VisualStudio�ṩ��һ������ɴ��������ݿEF����ģ�ͼ��ӳ��ת��������
���������֮��EF�ɹ��������ݿ��������ʹ�õĶ���֮�佨�������¶�Ӧ��ϵ��
��ϵ���ݿ������
���ݿ�Ӧ�ó��������
���ݿ�
DbContext��
��
DbContext�е�DbSet<ʵ������>
�������
ʵ����֮��Ĺ���
���е��ֶ�
ʵ����Ĺ�������
���еĵ�����¼
����ʵ����Ķ���
��ͼ
DbContext�е�DbSet<��ͼ����>
�洢����
DbContext�еĹ��з���
������Visual Studio ��ģ���������п���EF����ģ�͵ĸ���ģ�ͺʹ洢ģ�ͣ����ֱ����xml��ʽ��.edmx�ļ������Կ�����ԭ֭ԭζ����ȫ����������ģ�͡�
Visual Studio�ṩ��EF����������������������ģ�ͣ���ʹ��T4����ģ�壨���ļ���չ��Ϊ.tt��ֱ����������Ӧʵ���࣬����һ��������DbContext�����࣬�����а���������ʵ�弯�����Ժ͵���Ĵ洢���̵����ݿ�Ԫ�ء���һDbContext����������ʹ��EF��������ĺ������͡�
�ڽ��������Դ��������˫����edmx���ļ�����EF�����������һ����ǿ���Ĺ��ߣ��������еĵ�������ӳ���ϵ�Ĺ���������ʹ��������ɡ�
�������Database First��Model First��ʽ��������ôEF�����������Ҫ���Ķ������������ʽ�ܼ��һ���������ӵ����˵���ѡ����Ӧ������
EF������ṩ�ĸ�������;���ʹ�÷����кܶ����Ͻ��ܣ��ڴ˾Ͳ��ϻ��ˡ�
����ʹ��EF�������ݿ�Ļ�����ʽEF�п���ʹ���������ַ�ʽ�������ݿ⣺
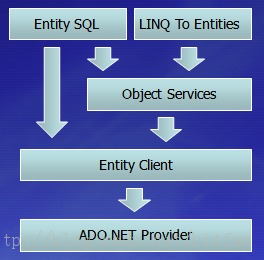
Entity SQL��ר��ΪEF��Ƶ�һ�ֲ�ѯ���ԣ��dz�������ͨ�õĹ�ϵ�����ݿ��ѯ����SQL���������ص����ݶ�����EF������ģ�͡���������ģ��������ݿ������ݵġ���ʵģ������
LINQ to Entities���Կ�����LINQ to Objects��һ�������֡���ͨ��LINQ����ѯEF����ģ�͡����ڵײ�ʹ�á��������Object services����������书�ܡ����������һ�����ڲ�ѯʵ������ģ�͵��࣬�����Խ���Щ��ѯ���ת��Ϊǿ���͵�CLR����
������ʹ��Entity SQL����LINQ to Entities�����ն���������Entity Client��������乤���ġ�
Entity Client����һ���࣬����EntityConnection��EntityDataReader�ȣ���ADO.NET����ģ�ͷdz����ƣ��书��Ҳ���ơ�Entity Client�Ὣ�����ݵ�CRUD����ת����ADO.NET�����ṩ�ߣ�ADO.NET Provider����������佫���SQL����ֱ�ӵط������ݿ⡣
��ʵ�ʿ����У���Ҷ�ʹ��LINQ to Entities�����IEnumerable<T>/IQueryable<T>��һ����չ����������ݲ�ѯ������������������ֱ��ʹ��Entity SQL�� Entity Client��
��ͼչʾ����Ӧ�ó������й�����EF��ѯ���ڲ��������̣�
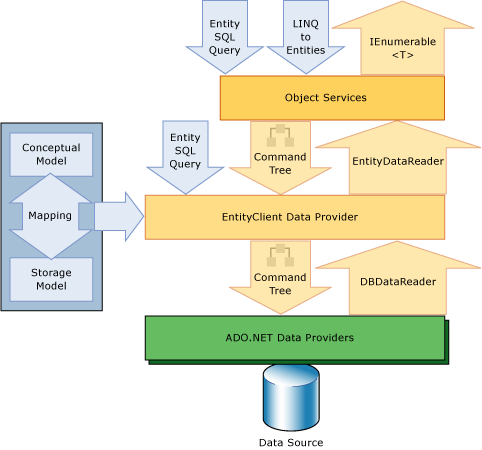
���Կ�����ʹ��EF�����ݲ�ѯ�ӷ���������ִ��Ҫ�������Ρ���������Command Tree��ת�������������ݿ��ж�ȡ�����ݣ�ҲҪ������DbDataReader-->EntityDataReader-->IEnmerable<T>��ת������ȻEF�����˻��桢Ԥ������ֶ��������ܣ�����ADO.NET��ȣ������м䴦�����ڸ��࣬������ѯ���������в���Ķ���Ҳ���࣬�����������һ��Ȳ���ADO.NET�����һ�ռ�ø�����ڴ棬��Ҳ������������EF�����ķ����ͬʱ������Ҫ�����Ĵ��ۡ�
���⣬�������в�ѯ���ջ���Ҫת��ΪSQL�����ˣ���ЩLINQ to Objects���õ���չ����������Last()����EF�н������ã���ΪEF��֪����ΰ����Ƿ���ɵײ����ݿ�֧�ֵ�SQL���
EF֧�����ֿ���ģʽ��
Code First��Database First��Model First��
����Ӧ������һ��ģʽ�����˾�������⡣
��ʽһ��Code First���ڳ��νӴ����ˣ�EF��Code Firstʵ�ں��е�ħ��ɫ�ʡ�����������������һ�¡�
���������ࣺBook���飩��BookReview����������һ��������ж�����������ˣ�������һ�Զ�Ĺ�ϵ��
public class Book
{
public virtual int Id {get;set;}
public virtual string Name { get; set; }
public virtual List<BookReview> Reviews { get; set; }
}
public class BookReview
{
public int Id{get;set;}
public int BookId { get; set; }
public virtual string Content { get; set; }
public virtual Book AssoicationWithBook { get; set; }
}
���ˣ����ڴ���һ��������DbContext�����ࣺ
public class BookDb : DbContext
{
public DbSet<Book> Books { get; set; }
public DbSet<BookReview> Reviews { get; set; }
}
���ڿ����ڳ���������д���д�������ݿ�����ȡ���ݣ�
static void Main(string[] args)
{
using (var context = new BookDb())
{
Console.WriteLine("���ݿ�����{0}����",context.Books.Count());
}
}
����һ�£����������ϰ�װ��SqlExpress����ô��������Ӧ�ó����ļ��У������Ǵ�SQL Server Management Studio��SSME���鿴����SQLServer����ͻᷢ�֣����ݿ⼺�������ã����еı������Ĺ���Ҳ����������ˣ�
ò����ʲôҲû�ɣ�һ�о�OK�ˣ����氡��
������Book�࣬��������һ��Authors���ԣ�����������ߣ�
public class Book
{
public virtual int Id {get;set;}
public virtual string Name { get; set; }
public virtual string Authors { get; set; }
public virtual List<BookReview> Reviews { get; set; }
}
����ǰ�����õĵ�һӡ����һ����ΪֻҪ�ٴ����г��ײ����ݿ�ͻ��Զ����£�Ȼ����EF����㵱ͷһ���������ѣ�
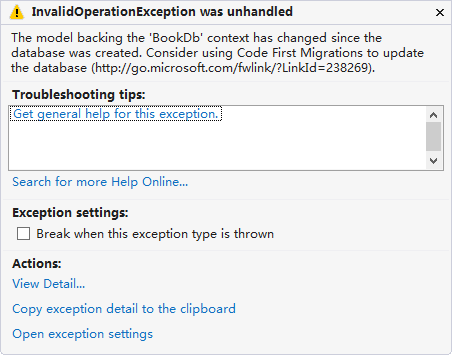
�����ԣ���Ϊ������ʵ���࣬���ݿ�ṹҲ��Ҫ�ģ��Ƚ����Ƶ��ǣ��㲻�ܴ����õ����ݿ�ֱ���ģ�����Ҫʹ��һ����Ϊ�����ݿ�Ǩ�ƣ�Database Migration�����Ĺ��ܣ��������ַ�ʽ���Զ�Ǩ�ƺ��ֶ�Ǩ�ƣ�֮һ��ɡ�
���Զ�Ǩ��Ϊ����
���ȴӴ�Tools�˵��д�Package Manager Console��Ȼ����룺
enable-migrations �CEnableAutomaticMigrations
�������������Ŀ������һ��Migrations�ļ��У����л���һ��Configuration�࣬Ϊ�˷��㣬����Ҫ���乹�캯�������ӡ�AutomaticMigrationDataLossAllowed = true;��һ�䣬�����Զ��ؽ����ݿ�ʱ��������ܵ����ݶ�ʧ��
internal sealed class Configuration :DbMigrationsConfiguration<EFCodeFirst.BookDb>
{
public Configuration()
{
AutomaticMigrationsEnabled = true;
AutomaticMigrationDataLossAllowed = true;
}
����
}
���ˣ���������update-database����������ݿ⣺
�ٴ����г������ڽ�һ��OK��
�Ժ�ÿ�θ���ʵ���࣬�������ֶ�����update-database����������ݿ⡣
�ֶ�Ǩ�Ʒ�ʽ���Զ�Ǩ�ƻ���һ�£���֮ͬ�����������¼ÿ�θ��µ�������Ӷ������ع����ݿij�������ϡ��İ汾��
�Զ���ʽ�Ƚ��ʺ��ڵ�����д��Ӧ�á����ֶ���ʽ���Կ������ݿ�ṹ�ĸ��£��Ƚ��ʺ����Ŷӿ�����
Code Firstģʽ���ŵ㡣������Ľ��ܣ����Կ���Code First����ͻ�����ŵ㡣
��1���Ǵ�����࣬�����Զ��������ס�
����ʹ��Code First���ĺô�
�ر���������WPF���ֿ��Ա��ֳ����ӵ�����Ӧ���У�������ʵ����ʵ��INotifyProperty�ӿڣ������Ƿ���ObservableCollection����ΪUI����İ�����Դ������Գ������WPF�����ݰ�EF�Զ�ά��ʵ��״̬���ص㣬����ȵ��������롣
��2������ʵ�ּ̳�
Code First��ʵ�ּ̳��Ϸdz����㣬�������ʵ�����д����ļ̳е������ʹ��Code First�ܷ��㣬����Ҫע�����Code First���������ݿ��ʱ��Ĭ��ʹ�á�TPH��Table Per Hierarchy����ʽ���Ѹ�����������ͬһ�ű��У����ڱ�������һ��Discriminator�ֶΣ������˼�¼�����ľ������͡�
������CodeFirstΪӵ�м̳й�ϵ������Parent/Child�����ɵ����ݿ�������Կ�����Discriminator�ֶα����˾�����������͡�
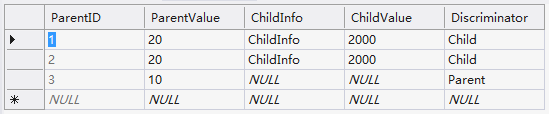
��Щ�������ܷ��Discriminator�ֶ������ĵ������ź�����û���ֿ��������ķ�����
�����ԣ�Code First���õ�����ʵ�ֲ���Υ���˹�ϵ���ݿ���Ʒ�ʽ���Դ���Ŀ��˵���ⲻ����ά�����ݵ�һ���ԡ�
ʵ�ּ̳е�����һ�ַ�ʽ��TPT��table pertype �����������ุ�࣬ÿ������һ�ű���
�����������࣬Instruct��Student������Person��������TPT���ԣ�EF�����������������������µĹ�����
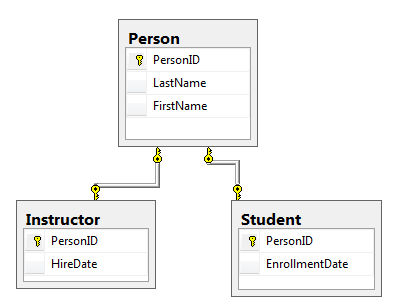
����TPH����дSQL��������ף����ܸߣ�������TPT��EF������SQL����ʱ���������Inner Joint�����ܵͣ����⣬�������ַ�ʽ�洢�����ݣ���дSQL����Ƚ��鷳��
Database First��Model FirstĬ������¶��Dz���TPH�ġ�
�ҵĽ��飺������ʵ���ȷʵ��IS_A��ϵ���������м����Ҫʹ�ö�̬���ڡ����ݴ�ȡ�㣨DAL�����������ü̳У��������鷳��
��3��һЩ���������ǻ�ΪEF�ṩ��һ��EntityFramework Power Tools����һ������ǿ��Code First�IJ��ٹ��ܣ����������Դ��������ݿ�ֱ����������ʵ������룬֮��Ϳ�������Щ���룬ΪCode First��ʽ���п���ʡȥ�˲��ٱ��빤����ͬʱ��������Ϊ��д��ʵ�����������ֻ��������ģ����ͼ����ͼ�εķ�ʽչʾ��ʵ�����Ĺ�����
Code First���ڵ�����CodeFirst��ͼ���ô�����һ�С����������������¼��㣺
��1����Model�ı�ʱ��������Ҫ��д����ʵ�����ݿ�ĸ��ģ�Զ����ֱ��ʹ�����ݿ����ṩ�Ĺ��������ݿⰲȫ��ֱ�ۣ����ٶ�ʧ���ݵĿ�����С�˺ܶࡣ
��2��������ʵ����и��ӵĹ���ʱ����Ҫʹ��Fluent API�ֶ���д���ٴ��붨����֮��Ĺ�������ʵ���鷳��
��3�������ݿ���������Ե�һЩ��������ĸ��ֶ����֣����ֶγ������Ƶȣ���ʹ�����ݿ���ƹ���������ʵ�֣���Code Firstֻ��ͨ����������ɣ����ұ���ʹ��EF������Ǩ�����ԣ���ʵ���鷳���������̻����׳�����
�����֮��Code FirstӦ�õij����ǣ����ٿ�����Ѹ�ٵ�����
��ʽ����Database First����EF��1.0��ʼ��֧�ֵ����ԣ���˼·�ǣ�����Ʋ��������ݿ⣬Ȼ��ʹ��Visual Studio������EF����ģ�Ͳ�����ʵ������롣
����������ȶ��ķ�ʽ����������൱�����ƣ�������������ʵ�ʿ����еĸ�������
�Ҹ�����Ϊ���ǿ�����ʽ��Ŀ����ʵķ�ʽ��
��Ȼ��DatabaseFirstҲ��һЩ���⣬��Ҫ����Ҫ����ʱ����Щ�鷳�����磺
��1��Ҫ���ʵ��������ɵ�DbContext��������һЩ�Զ����������Ӧ�÷ֲ��࣬��Ϊÿ�θ�������ģ�ͣ���Щ���붼�ᱻ��������Dz���д��
��2�����ɵ�ʵ�����в������κ�Data Annotation����ν��Data Annotation�����Ǹ���ʵ��������ϵ�����[Required]֮��Ķ��������������Ҫ��ת��Ϊ��һ���࣬���ܷ����������ASP.NET MVC֮�����Ŀ��ʹ�ã�����ASP.NET MVC��Ŀ�е���ͼģ�ͣ�ViewModel����������Ҫ��Data Annotation�������jQuery Validation���������ҳ�ϵ�������֤���룩��
��3��Ĭ�������ʵ������edmx�ļ�����ͬһ����Ŀ�У��뽫ʵ������뵽��������Ŀ����Ҫ���һЩ��������ù�������Ҫ�ǰ�T4ģ���ļ��Ƶ���һ����Ŀ������Ҫ�ʵ�����T4ģ���ļ��еĴ����Ա�֤�ļ�·��������ȷ����
��ʽ����Model First����ģʽ�����ڿ��ӻ�������д���ʵ������Ǽ�Ĺ�����Ȼ�����������SQL���������һ��SQL�ļ��У�ͨ��ִ����һSQL�ļ�������ݿ�Ĵ������Ĺ�����
�Ҹ��˸о���
���ַ�ʽ���ʺ���ȫ�¿�������Ŀ����ϵͳ������ʼ��������������������ģ�ͣ�֮����������������ݿ⣬���ģ�����ģ���������һ��SQL�ļ�����ִ��һ�μ��ɣ��dz��ʺ�������ĿOOAD�ε���Ҫ��
������OOP��ʱ���������ݿ⼺�����ڣ��Ϳ��Ժܷ����ת��Database First��ʽ����������������Ȼ��
����ģʽPK�����Code First:����С�Ļ������������Ŀ���ر������Ҿ���Ҫ���εģ���ѧʵ��ʹ��Code First�����ͱȽϺ��ʣ�����������ʱ���ݿ��Զ����ɣ��Ƚ�ʡ�¡�
DB First����Ϊ���죬��������Ŀ����ѡ��ʽ����Ϊ���ɿ������Լ���������ͨ��һ�ѡ���̫�ɿ����Ĵ��룩ֱ�Ӳ������ݿ⣬�������̸߶ȿɿأ��ܺܺõر�֤���ݰ�ȫ���᳹�ˡ����ݱȴ�����Ҫ�������
Model First������ʼһ��ȫ�µ���Ŀ����û��DB��Ҳû�д���ʱ��dz��ã���OOAD�ĺù��ߣ���Ҫʱ��������ֱ�����ɴ������ֲ�ͬ�������ݿ⣨����MySQL����SQL���룡
==============================================================
��ƪ���½�����һЩEF��ص�ͨ�û��⣬��һƪ���½�����һ��EFʵ��CRUD���ڲ�ԭ����