开源LVS--使用简单的 5 个步骤设置 Web 服务器集群
如图 1 所示,外部客户机向单个 IP 地址发送通信量,而该 IP 地址可能存在于某个 LVS 控制器机器上。控制器机器积极地监控接收其发送工作的 Web 服务器池。
注意,图 1 左侧的工作负载进程指向右侧。此集群的浮动资源地址在一个给定时间将位于某个 LVS 控制器实例上。可以使用一个图形化的配置工具手动地移动服务地址,或者(这种方法更常见)自行管理服务地址,视 LVS 控制器的状态而定。如果某个控制器变得不合格(由于连接丢失、软件故障或类似原因),那么服务地址将自动地被重新分配给一个合格的控制器。
浮动服务地址必须跨越两个或多个离散的硬件实例,以便在一个物理机器连接丢失的情况下继续操作。使用本文展示的配置决策,每个 LVS 控制器都可以将包转发给任何的实际 Apache Web 服务器,并且与服务器的物理位置或服务器与提供浮动服务地址的活动控制器的接近程度无关。本文展示了每个 LVS 控制器如何积极地监控 Apache 服务器,以确保只向正常运作的后端服务器发送请求。
使用这种配置,技术人员可以成功地让整个 Linux 实例失效,而且不会中断在浮动服务地址上启用的用户服务(通常是 http 和 https Web 请求)。
确保每个 realserver 都正常地侦听 http 端口 (80) 的一个简单方法是,使用外部系统并执行扫描。在一些与您的服务器连网的其他系统中,可以使用 nmap 工具以确保服务器执行侦听操作。
清单 1. 使用 nmap 确保服务器执行侦听操作
?
respawn 指令在运行时指定某个程序的运行和监控。如果此程序退出时的退出码不是 100,程序将自动重启。第一个参数是运行程序的用户 id,第二个参数是要运行的程序。-m 参数将 pingd 属性设为从当前机器可获得的 ping 节点数的 100 倍,而 -d 参数在修改 CIB 中的 pingd 属性之前将延迟 5 秒。ping 指令用于声明 Heartbeat 的 PingNode,而 crm 指令指定了 Heartbeat 应运行 1.x-style 集群管理器或 2.x-style 集群管理器,后者支持 2 个以上的节点。
对于所有的控制器这个文件都应该相同。适当地设置权限使 hacluster 守护程序可以读取文件也绝对重要。否则将导致日志文件中出现大量难于调试的警告。
对于某个版本的 1-style Heartbeat 集群,haresources 文件指定了节点名和连网信息(浮动 IP、关联接口和广播)。对我们而言,此文件仍然没有变化:
litsha21 192.168.71.205/24/eth0/192.168.71.255
此文件将只用于生成 cib.xml 文件。
authkeys 文件指定了一个共享的密匙以允许控制器之间进行通信。共享密钥就是一个密码,所有的 heartbeat 节点都知道这个密码并使用它进行相互通信。密钥的使用避免了无关方对 heartbeat 服务器节点的影响。此文件也没有变化:
auth 1
1 sha1 ca0e08148801f55794b23461eb4106db
接下来的几步将向您展示如何将 version 1 的 haresources 文件转换为 version 2 的基于 XML 的配置格式 (cib.xml)。虽然可以直接复制并使用清单 4 中的配置文件作为起点,但是强烈建议您针对自己的部署进行配置调整。
为了将文件格式转换为部署中使用的基于 XML 的 CIB (Cluster Information Base) 文件,请发出以下命令:
python /usr/lib64/heartbeat/haresources2cib.py /etc/ha.d/haresources > /var/lib/heartbeat/crm/test.xml
将会生成一个类似清单 4 所示的配置文件,并置于 /var/lib/heartbeat/crm/test.xml 中。
清单 4. CIB.xml 样例文件
?
一旦生成配置文件后,将 test.xml 移到 cib.xml 中,将所有者改为 hacluster,将组改为 haclient,然后重启 heartbeat 进程。
现已完成 heartbeat 配置,对 heartbeat 进行设置,使其在每个控制器的引导阶段启动。为此,在每个控制器上发出以下命令(或相对您的发行版的等效命令):
# chkconfig heartbeat on
重启每个 LVS 控制器以确保 heartbeat 服务在引导阶段正常启动。通过首先暂停保存浮动资源 IP 地址的机器,您可以等候其他 LVS Director 映像建立 quorum,然后在几秒钟内实例化最新选择的主节点上的服务地址。当您将暂停的控制器映像重新联机时,机器将在所有的节点间重新建立 quorum,此时浮动资源 IP 可能传输回来。整个过程只会耗费几秒钟。
另外,此时,您可能希望使用图形化工具处理 heartbeat 进程 hb_gui(如图 2 所示),手动地将 IP 地址在集群中移动,方法是将各种节点设置为备用或活动状态。多次重试这些步骤,禁用并重新启用活动的或不活动的各种机器。因为先前选中了配置策略,只要可以建立 quorum,并且至少有一个节点合格,那么浮动资源 IP 地址就保持正常运作。在测试期间,您可以使用简单的 ping 确保不会发生丢失包的情况。当您完成试验后,应该对配置的健壮性有一个深刻的体会。在继续操作之前请确保浮动资源 IP 的 HA 配置适当。
图 2. 用于 heartbeat 进程的图形化配置工具 hb_gui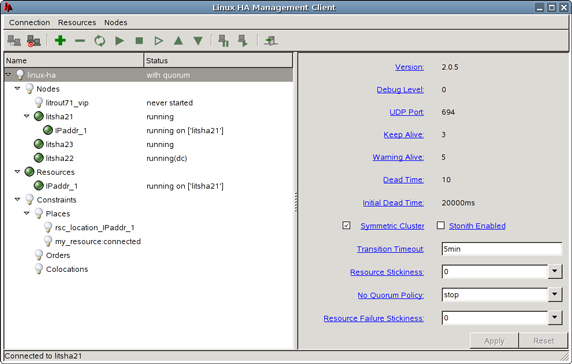
图 2 展示了登录后的图形控制台的外观,上面显示了托管资源和相关的配置选项。注意,当您首次启动应用程序时,必须登录到 hb_gui 控制台;使用何种凭证将取决于您的部署。
注意,图 2 中 litsha2* 系统集群中的每个节点都处于运行状态。标记为 litsha21 的系统目前是活动节点,如 (IPaddr_1) 正下方锯齿状的附加资源所示。
另外要注意标记为 “No Quorum Policy” 的选项的值为 “stop”。这指的是任何单独的节点将释放它所拥有的资源。这个决策的含义是,在任何给定时间,必须有 2 个 heartbeat 节点是活动状态,以便建立 quorum(换言之,一种 “少数服从多数” 的投票规则)。即使只有一个节点是活动的,完全运行的节点也会由于网络故障丢失它与同级系统之间的连接,或者,如果两个非活动的同级系统同时暂停,资源将被自动释放。
如果所有的操作都成功,那么第二个命令将返回一个 “1” 作为终端输出。要永久性地添加此选项,请添加:
'' IP_FORWARD="yes"
到 /etc/sysconfig/sysctl 中。
接下来,要通知控制器将引入的 HTTP 请求传递给 HA 浮动 IP 地址,接着再传给 realserver,使用 ipvsadm命令。
首先,清除旧的 ipvsadm 表:
# /sbin/ipvsadm -C
在配置新表之前,您需要决定希望 LVS 控制器使用何种工作负载分配。收到来自客户机的连接请求后,控制器根据一个 “进度表” 将 realserver 指派给客户机,然后使用 ipvsadm 命令设置调度程序类型。可用的调度程序包括:
使用 RR 调度进行测试是个不错的方法,因为易于确认。您可能希望将 WRR 和 LC 添加到测试例程中以确认它们能够按预期运作。此处给出的示例使用 RR 调度及类似调度。
接下来,创建脚本以启用转发至 realserver 的 ipvsadm 服务,并且在每个 LVS 控制器中放置一个副本。当完成 mon 的后续配置以自动监控活动的 realserver 后,就不需要再使用这个脚本,但在此之前它会有助于测试 ipvsadm 组件。请记住在执行此脚本之前重新检查网络和 http/https 与每个 realserver 之间的连接是否正常。
清单 5. HA_CONFIG.sh 文件
?
如清单 5 中所示,脚本只是启用了 ipvsadm 服务,然后实际上使用了相同的代码节以便将 Web 和 SSL 请求转发给每个单个的 realserver。我们使用了 -m 选项指定 NAT,并给每个 realserver 赋以权重 1(-w 1)。使用正常的轮循调度时,指定的权重会出现冗余(因为默认的权重总是 1)。显示此选项的惟一目的是让您倾向于选择加权的轮循。 为此,在关于使用轮循的注释下的 2 个连续的行中将 rr 改为 wrr,当然不要忘了相应地调整权重。有关各种调度程序的更多信息,请查询 ipvsadm 手册。
您现在已经配置了每个控制器,可以处理引入的对浮动服务 IP 的 Web 和 SSL 请求,方法是重写这些请求并连续地将工作传递给 realserver。但是为了从 realserver 收回通信量,并且为了在将请求返回给发出请求的客户机之前执行相反的过程,您需要对控制器更改几个连网设置。其原因是需要在平面网络拓扑结构中实现 LVS 控制器和 realserver(即,同一子网上的所有组件)。我们需要执行以下步骤以强制 Apache 通过控制器返回响应通信量,而不是自己直接应答:
echo "0" > /proc/sys/net/ipv4/conf/all/send_redirects
echo "0" > /proc/sys/net/ipv4/conf/default/send_redirects
echo "0" > /proc/sys/net/ipv4/conf/eth0/send_redirects
执行此操作的目的是为了防止活动的 LVS 控制器通知 realserver 和浮动服务 IP 直接相互通信,从而获取 TCP/IP 捷径(因为它们位于同一个子网中)。一般情况下,重定向是有用的,因为它们通过清除网络连接中不必要的中间件提高了性能。但是此时,它可能阻碍了响应通信量的重写,而这又是对客户机透明所必需的。实际上,如果在 LVS 控制器上没有禁用重定向,那么从 realserver 直接发往客户机的通信量将被客户机视为未被请求的网络响应而被丢弃。
此时,可将每个 realserver 的默认路由设为指向服务的浮动 IP 地址,从而确保所有的响应都被传回控制器以进行包重写,然后再传回最初发出请求的客户机。
一旦在控制器上禁用重定向,并且 realserver 被配置为通过浮动服务 IP 发送所有的通信量,那么您可能需要测试 HA LVS 环境。要测试迄今为止所做的工作,可让一个远端客户机上的 Web 浏览器指向 LVS 控制器的浮动服务地址。
为了在实验室进行测试,我们使用的是基于 Gecko 的浏览器(Mozilla),但是任何其他浏览器也可以满足要求。为了确保部署成功,在浏览器中禁用缓存,并多次单击刷新按钮。在每次刷新时,您应看见显示的 Web 页面是 realserver 上配置的一个自识别页面。如果您要使用 RR 调度,您应可以看到连续通过每个 realserver 的页面循环。
您是否正在思考确保 LVS 配置在引导时自动启动?现在千万别这样做!还有一个步骤尚未完成(步骤 5),此步骤将执行 realserver 的活动监控(因此保留一个动态 Apache 节点列表,其中的节点可以为工作请求提供服务)。
monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat2 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat3 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat4 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat5 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat6 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1?
清单 7 告知 mon 使用 http.monitor,默认情况下它由 mon 附带。另外,指定使用端口 80。清单 7 还提供了要请求的特殊页面;您可能会选择为 Web 服务器传输一小段更有效率的 html 作为操作成功的证明,而不是传输一个复杂的默认 html 页面。
alert 和 upalert 行调用的脚本必须置于配置文件顶部指定的 alertdir中。其目录通常是发行版所默认的目录,比如 “/usr/lib64/mon/alert.d”。警报负责告知 LVS 将 Apache 服务器添加到合格的列表中或从中删除(方法是调用 ipvsadm 命令,我们很快就要介绍到)。
当一个 realserver 的 http 测试失败时,dowem.down.alert 将由 mon 使用几个参数自动执行。同样地,当监视器确定 realserver 已经恢复联机时,mon 进程使用大量的参数自动执行 dowem.up.alert。您可以随意地修改警报脚本的名称以适应您的部署。
保存此文件,在 alertdir 中创建警报(使用简单的 bash 脚本编程)。清单 8 展示了一个 bash 脚本警报,重新建立 realserver 连接时由 mon 调用。
清单 8. 简单警报:已连接上
?
清单 9 展示了一个 bash 脚本警报,当 realserver 连接丢失时由 mon 调用。
清单 9. 简单警报:连接已丢失
?
这两组脚本都使用 ipvsadm 命令行工具动态地将 realserver 添加到 LVS 表中或从中删除。注意,这些脚本远谈不上完美。mon 只对于简单的 Web 请求监控 http 端口,此处阐述的架构在下述情形中容易受到攻击:给定的 realserver 对于 http 请求可能正常运作,但对于 SSL 请求却不行。在这些情况下,我们将无法从 https 备选列表中删除有问题的 realserver。当然,除了为 mon 配置文件中的每个 realserver 启用另一个 https 监视器外,构建更多专门针对每种类型的 Web 请求的高级警报也可以轻松地解决这个问题。这可以留给读者作为练习。
为确保监视器已被激活,依次为每个 realserver 启用并禁用 Apache 进程,观察每个控制器对事件的反应。只有当您确认每个控制器正常地监控每个 realserver 后,您才可以使用 chkconfig 命令确保 mon 进程可以在引导时自动启动。使用的特定命令为 chkconfig mon on,但是这可能随发行版的不同而有所区别。
完成这个最后的部分后,您就已完成构建跨系统的高度可用的 Web 服务器基础设施的任务。当然,您现在可能想要执行一些更高级的工作。例如,您可能已经注意到,mon 守护程序本身没有被监控(heartbeat 项目可以为您监控 mon),但是最后的步骤已为此打下基础。
litsha22:~ # tail -f /var/log/messages Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Heartbeat restart on node litsha21 Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Link litsha21:eth1 up. Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Status update for node litsha21: status init Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Status update for node litsha21: status up Jan 16 12:09:22 litsha22 heartbeat: [3892]: debug: get_delnodelist: delnodelist= Jan 16 12:09:22 litsha22 heartbeat: [3892]: info: Status update for node litsha21: status active Jan 16 12:09:22 litsha22 cib: [3900]: info: cib_client_status_callback:callbacks.c Status update: Client litsha21/cib now has status [join] Jan 16 12:09:23 litsha22 heartbeat: [3892]: WARN: 1 lost packet(s) for [litsha21] [36:38] Jan 16 12:09:23 litsha22 heartbeat: [3892]: info: No pkts missing from litsha21! Jan 16 12:09:23 litsha22 crmd: [3904]: notice: crmd_client_status_callback:callbacks.c Status update: Client litsha21/crmd now has status [online] .................... Jan 16 12:09:31 litsha22 crmd: [3904]: info: crmd_ccm_msg_callback:callbacks.c Quorum (re)attained after event=NEW MEMBERSHIP (id=16) Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c NEW MEMBERSHIP: trans=16, nodes=2, new=1, lost=0 n_idx=0, new_idx=2, old_idx=5 Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c CURRENT: litsha22 [nodeid=1, born=13] Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c CURRENT: litsha21 [nodeid=0, born=16] Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c NEW: litsha21 [nodeid=0, born=16] Jan 16 12:09:31 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Local-only Change (client:3904, call: 35): 0.54.600 (ok) Jan 16 12:09:31 litsha22 mgmtd: [3905]: debug: update cib finished .................... Jan 16 12:09:34 litsha22 crmd: [3904]: info: update_dc:utils.c Set DC to litsha22 (1.0.6) Jan 16 12:09:35 litsha22 cib: [3900]: info: sync_our_cib:messages.c Syncing CIB to litsha21 Jan 16 12:09:35 litsha22 crmd: [3904]: info: do_state_transition:fsa.c litsha22: State transition S_INTEGRATION -> S_FINALIZE_JOIN [ input=I_INTEGRATED cause=C_FSA_INTERNAL origin=check_join_state ] Jan 16 12:09:35 litsha22 crmd: [3904]: info: do_state_transition:fsa.c All 2 cluster nodes responded to the join offer. Jan 16 12:09:35 litsha22 attrd: [3903]: info: attrd_local_callback:attrd.c Sending full refresh Jan 16 12:09:35 litsha22 cib: [3900]: info: sync_our_cib:messages.c Syncing CIB to all peers ......................... Jan 16 12:09:37 litsha22 tengine: [5119]: info: send_rsc_command:actions.c Initiating action 4: IPaddr_1_start_0 on litsha22 Jan 16 12:09:37 litsha22 tengine: [5119]: info: send_rsc_command:actions.c Initiating action 2: probe_complete on litsha21 Jan 16 12:09:37 litsha22 crmd: [3904]: info: do_lrm_rsc_op:lrm.c Performing op start on IPaddr_1 (interval=0ms, key=2:c5131d14-a9d9-400c-a4b1-60d8f5fbbcce) Jan 16 12:09:37 litsha22 pengine: [5120]: info: process_pe_message:pengine.c Transition 2: PEngine Input stored in: /var/lib/heartbeat/pengine/pe-input-72.bz2 Jan 16 12:09:37 litsha22 IPaddr[5196]: INFO: /sbin/ifconfig eth0:0 192.168.71.205 netmask 255.255.255.0 broadcast 192.168.71.255 Jan 16 12:09:37 litsha22 IPaddr[5196]: INFO: Sending Gratuitous Arp for 192.168.71.205 on eth0:0 [eth0] Jan 16 12:09:37 litsha22 IPaddr[5196]: INFO: /usr/lib64/heartbeat/send_arp -i 500 -r 10 -p /var/run/heartbeat/rsctmp/send_arp/send_arp-192.168.71.205 eth0 192.168.71.205 auto 192.168.71.205 ffffffffffff Jan 16 12:09:37 litsha22 crmd: [3904]: info: process_lrm_event:lrm.c LRM operation (7) start_0 on IPaddr_1 complete Jan 16 12:09:37 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Update (client: 3904, call:46): 0.55.607 -> 0.55.608 (ok) Jan 16 12:09:37 litsha22 mgmtd: [3905]: debug: update cib finished Jan 16 12:09:37 litsha22 tengine: [5119]: info: te_update_diff:callbacks.c Processing diff (cib_update): 0.55.607 -> 0.55.608 Jan 16 12:09:37 litsha22 tengine: [5119]: info: match_graph_event:events.c Action IPaddr_1_start_0 (4) confirmed Jan 16 12:09:37 litsha22 tengine: [5119]: info: send_rsc_command:actions.c Initiating action 5: IPaddr_1_monitor_5000 on litsha22 Jan 16 12:09:37 litsha22 crmd: [3904]: info: do_lrm_rsc_op:lrm.c Performing op monitor on IPaddr_1 (interval=5000ms, key=2:c5131d14-a9d9-400c-a4b1-60d8f5fbbcce) Jan 16 12:09:37 litsha22 cib: [5268]: info: write_cib_contents:io.c Wrote version 0.55.608 of the CIB to disk (digest: 98cb6685c25d14131c49a998dbbd0c35) Jan 16 12:09:37 litsha22 crmd: [3904]: info: process_lrm_event:lrm.c LRM operation (8) monitor_5000 on IPaddr_1 complete Jan 16 12:09:38 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Update (client: 3904, call:47): 0.55.608 -> 0.55.609 (ok) Jan 16 12:09:38 litsha22 mgmtd: [3905]: debug: update cib finished
?
在清单 13 中,您可以看见 quorum 已被重新建立。重新建立 quorum 后,执行投票,而 litsha22 将变为具有浮动资源的活动节点。
回页首
结束语
高可用性被视为一系列挑战,本文介绍的解决方案描述了第一个步骤。从这里开始,在您的开发环境中有多种方法可以继续操作:您可以选择安装冗余的网络、集群文件系统以支持 realserver,或安装更高级的中间件直接支持集群。
<!-- CMA ID: 255753 -->?
<!-- Site ID: 10 -->?
<!-- XSLT stylesheet used to transform this file: dw-article-6.0-beta.xsl -->?
参考资料
学习
您可以参阅本文在 developerWorks 全球站点上的 英文原文。ipvsadm。站点包括了大量的教程和其他有用文档,并提供了 邮件列表。获得产品和技术
订购 SEK for Linux,它是两张 DVD 套装,其中包含来自 DB2?、Lotus?、Rational?、Tivoli? 和 WebSphere? 的最新的 IBM Linux 试用软件。讨论
通过参与新的 developerWorks 空间 中的开发者博客、论坛、网络广播和社区主题,加入 developerWorks 社区。作者简介
Eli Dow 是位于 Poughkeepsie, NY. 的 IBM Linux Test and Integration Center 的一名软件工程师。他拥有 Clarkson 大学的计算机科学和心理学学士学位,以及计算机科学硕士学位。他的兴趣包括 GNOME 桌面、人与计算机的交互以及 Linux 系统编程。您可以通过 emdow@us.ibm.com 与 Eli 联系。
Frank LeFevre 是位于纽约 Poughkeepsie 的 IBM Systems and Technology Group 的高级软件工程师。他拥有超过 28 年的 IBM 主机硬件和操作系统开发经验。目前,他是 Linux Virtual Server Platform Evaluation Test 的团队主管。