为啥把中断分为两部分来处理
为什么把中断分为两部分来处理中断服务例程一般都是在中断请求关闭的条件下执行的,以避免嵌套而使中断控制
为什么把中断分为两部分来处理
中断服务例程一般都是在中断请求关闭的条件下执行的,以避免嵌套而使中断控制复杂化。但是,中断是一个随机事件,它随时会到来,如果关中断的时间太长,CPU就不能及时响应其他的中断请求,从而造成中断的丢失。因此,内核的目标就是尽可能快的处理完中断请求,尽其所能把更多的处理向后推迟。例如,假设一个数据块已经达到了网线,当中断控制器接受到这个中断请求信号时,Linux内核只是简单地标志数据到来了,然后让处理器恢复到它以前运行的状态,其余的处理稍后再进行(如把数据移入一个缓冲区,接受数据的进程就可以在缓冲区找到数据)。因此,内核把中断处理分为两部分:前半部分(top half)和后半部分(bottom half),前半部分内核立即执行,而后半部分留着稍后处理,如图3.8所示: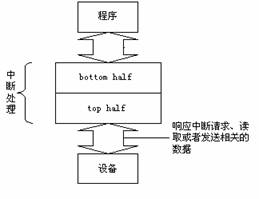
图3.8中断的分割
首先,一个快速的“前半部分”来处理硬件发出的请求,它必须在一个新的中断产生之前终止。通常地,除了在设备和一些内存缓冲区(如果你的设备用到了DMA,就不止这些)之间移动或传送数据,确定硬件是否处于健全的状态之外,这一部分做的工作很少。
然后,就让一些与中断处理相关的有限个函数作为“后半部分”来运行:
・ 允许一个普通的内核函数,而不仅仅是服务于中断的一个函数,能以后半部分的身份来运行。
・ 允许几个内核函数合在一起作为一个后半部分来运行。
后半部分运行时是允许中断请求的,而前半部分运行时是关中断的,这是二者之间的主要区别。
