【译】性能调优之后,进一步的验证和分析
译者:原始文章依然有点性能测试工具软文的感觉,毕竟文章来源于某工具官方博客。高手请略过。
此文是前文的后续,内容是在前轮性能测试的调优后,进行的调优结果验证。 演示了如何对比两轮测试的结果,如何分析突然出现波动的原因,如何根据大量的数据验证调优的效果、验证能否达到预期性能目标,以及更重要的思考过程。 这是一个比较不错性能测试调优后验证的实例。可以清楚看到专业人事,对性能调优后的数据,进行客观的比较,分析,再进一步判断调优的效果。故分享之。
由于本人能力不够,很多术语,不太明确其中文翻译,如大家看到有错误,请不吝赐教。 例如,在文章图片中% Difference in XXXX 和5.Per.Mov.Avg不知道是如何计算,又该如何翻译的好。
Spike - 数据增加明显,形成一个尖,暂译:波动 Peak - 数据到达最大值,暂译:高峰或者峰值 Degradation / Degrade - 性能变差,暂译:退化 Job - 定期执行的后台程序或服务,暂译:作业原文连接: http://apmblog.compuware.com/2013/07/11/an-integrated-approach-to-load-test-analysis-part-2-the-follow-up-test/
以下为正文
本文由Andreas Grabner共同撰写, 他是Compuware的APM卓越中心的团队负责人(Team Lead for the Compuware APM Center of Excellence)。
在之前的一篇文章 中, 我演示了如何做更深入的分析 - 合并了由Compuware APM网络负载测试工具(Compuware APM Web Load Test,以下简称WLT)得到的外部网络负载测试结果 和由Compuware PureStack技术收集硬件设备的状态数据。 但是,现在我们已经测试过系统一次,在“解决”我们发现的问题之后,如果我们再次进行测试,那又会出现什么呢? 使用前一轮测试时相同的参数,再运行一轮测试,就知道性能得到显著改善?我们系统能够达到期望的负载目标吗 - 支持200个虚拟用户,很少或者没有性能退化?
此文将带领你一步一步,比较两次负载测试的结果再判断调优之后性能的改善(或退化)。
在4月14日的负载测试期间,我和Andreas Grabner发现我们网站在高负载下,有显着的性能问题,这时的负载已远超目前水平,即使是在APM社区网站人气最高时的负载水平。 这些问题是造成负载水平达不到开发团队想要达到的目标 - 200个虚拟用户。

汇总的数据视图展现4月14日的负载测试中的外部和内部性能指标(点击图片见大图)
在4月14日负载测试执行时,我们发现了一些环境问题。系统团队记录下关键问题包括:
部署关键的APM社区程序到其他的机器,以防止某一层的性能负面地影响到其他层(Deployment of critical APM Community applications to different machines to prevent the application performance of one layer negatively affecting another laye)优化应用程序层 - APM社区网站的页面生成方式,以降低CPU使用率 优化Confluence的缓存设置,当加载常用的对象时,可以减少来回查询数据库次数 增加虚拟机的CPU分配,以便他们能够处理更多的负载。一旦这些调整完成后,根据第二轮测试的结果,在调优后的环境上,验证是否能够达到预期的目标 - 200 虚拟用户并发,且没有响应时间退化的现象。 第二轮负载测试被安排在整整1周后,即4月21日,并使用第一轮测试时相同的参数( 负载增压(load ramping)的细节设置参考前一篇文章)。 使用相同的测试参数(负载增压,测试脚本,测试位置,测试数据等)是至关重要的,只有如此,测试结果的对比才有意义(Using the same test parameters (load ramp, test scripts, testing locations, databanks, etc.) is critical in order to allow a like-for-like comparison to occur.)。 任何测试参数的偏差,会影响到最终结果,影响对应用程序环境的判断,可能导致对调优的不真实的信任(或怀疑)。
当4月21日这轮负载测试完成后,我们开始分析测试结果,初步的数据(更高的吞吐量,更快的响应时间,更低的CPU占用率和更低的数据库负载), 表明这轮负载测试比前一轮的测试更为成功。这个初步结论是基于性能图表(包含了我们分析4月14日测试时曾使用的相同的数据),这个图表直接对比其关键数据,突出在两轮测试执行之间,性能表现是否存在了巨大的变化。
好了,开始对比分析,我们从4月14日和4月21日两轮测试的结果中采取了三个关键指标,并把两轮数据放在一起比较对比:外部负载测试(External WLT)的平均响应时间;负载测试(WLT)的每分钟事务数;网络服务器的CPU利用率 。 只需对比这三组数据,很显然,这两轮负载测试有非常不同的性能表现。
从WLT测试的平均响应时间(负载测试中脚本里事务汇总后,完全下载的所有内容所需的时间 - the time required to completely download all of the content in the scripted synthetic transactions used in the load test), 很明显,在08:50 - 测试开始后的40分钟,响应时间的线开始出现分支,随后也分得越来越远,表现两轮测试的不同结果。从这个数据上看,21日的平均响应时间比14日的短50%左右(注:移动平均线,5分钟平均响应时间的变化差值的百分比,是一条更清晰的走向 - the Moving Average of percentage change averages 5 minutes of response time change to produce an clearer trend line)。 21日的测试中,又花了近20分钟,平均事务响应时间才达到20秒,即使当时负载水平跟14日时是一样的。
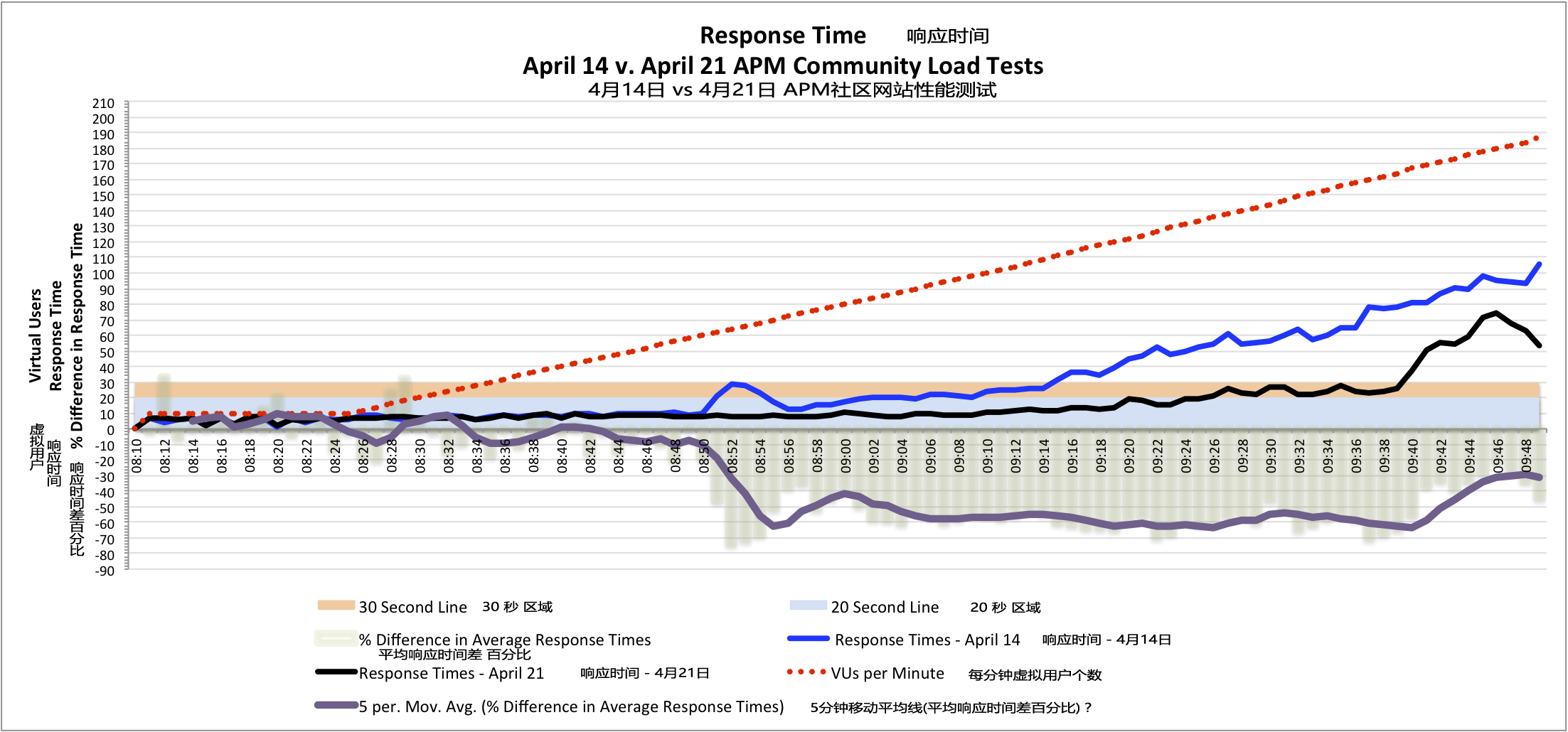
响应时间的对比表明在4月21日的APM社区网站负载测试的提升 - 更短的平均响应时间(点击图片见大图)
WLT每分钟事务数(负载测试中,WLT的一分钟内事务执行的数量)显示出一个共同点,其中21日测试和14日测试的数据也是在08:50出现差异。 由于从08:50开始,直到测试结束,一直保持更短的WLT平均响应时间,4月21日测试中系统每分钟处理的事务数量比4月14日测试中的要多出40%~50%。
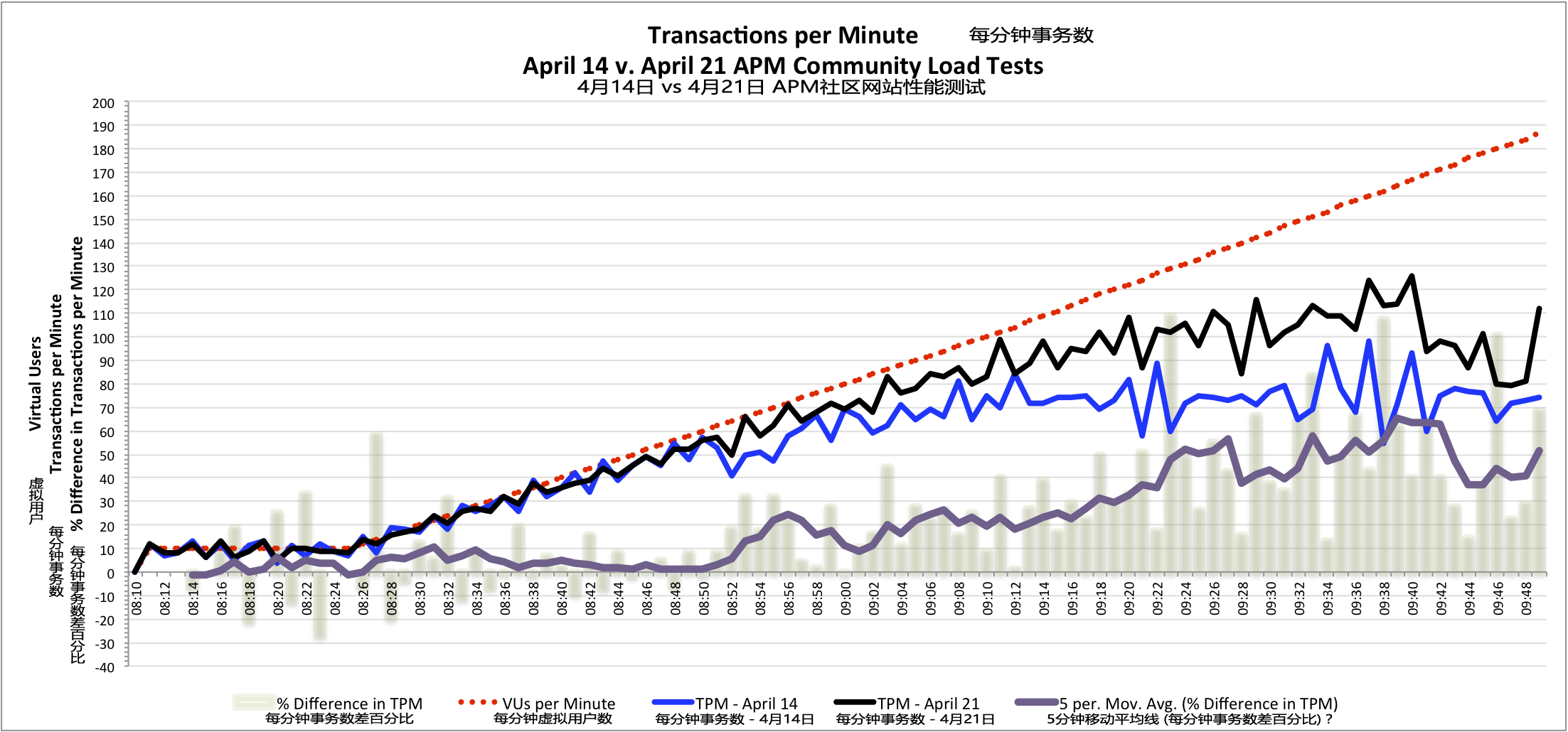
每分钟事务数对比表明在4月21日的APM社区网站负载测试的提升 - 更多的每分钟事务数(点击图片见大图)
第三个指标也显示出明显提升:网络服务器的CPU利用率(机器上系统和应用程序的执行所有必要的任务所使用的CPU百分比)。 纵观4月21日的测试中,网络服务器,经由更多的硬件和优化网页渲染方式的帮助,CPU在整个测试过程的压力有所减小,达到100%的使用率时远远晚于4月14日测试时的表现。
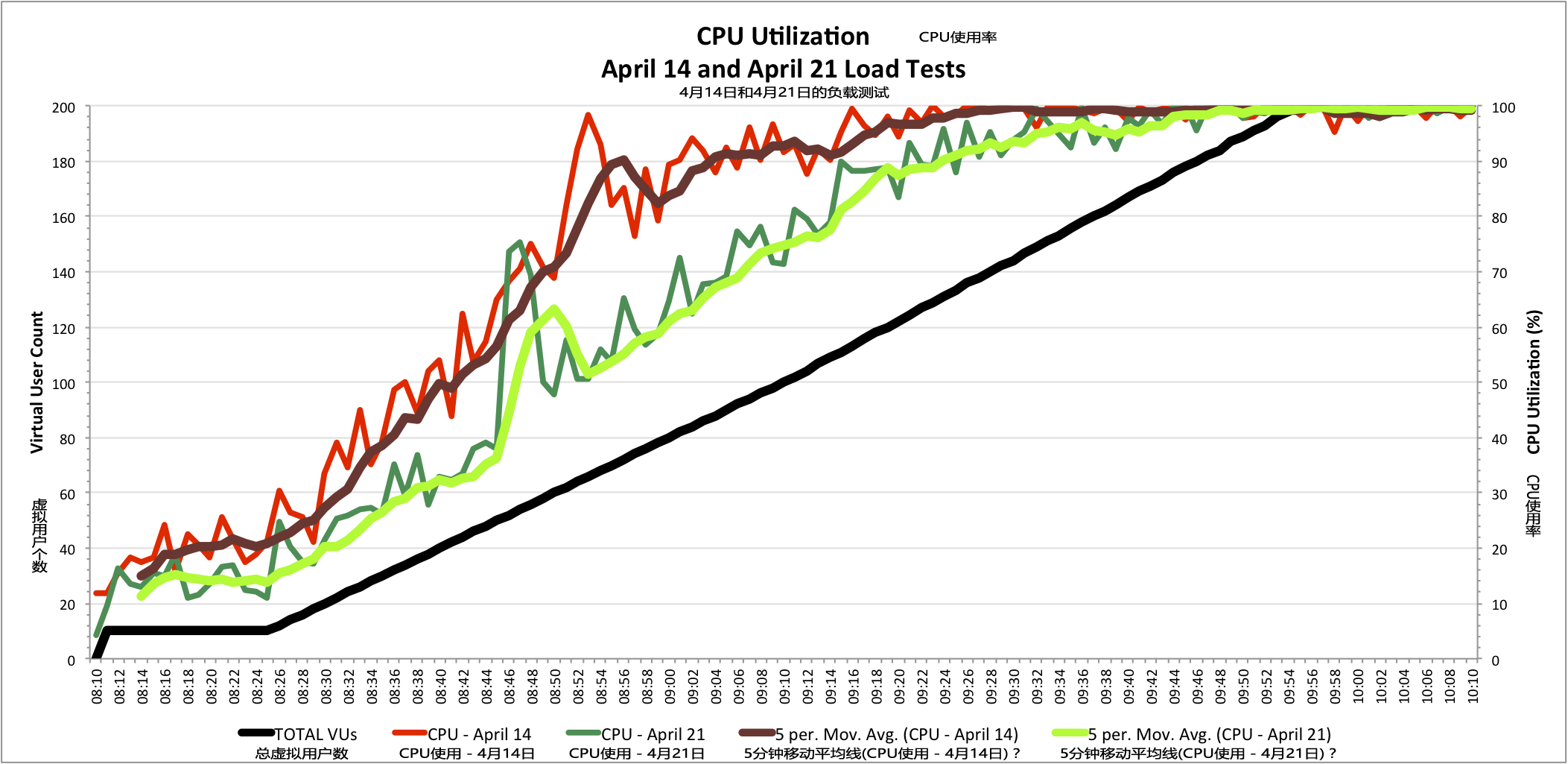
CPU使用率对比表明在4月21日的APM社区网站负载测试的提升 - 09:40之前的更低的CPU使用率(点击图片见大图)
这三个指标直接关系到每分钟网络请求数量(记录于4月21日测试的Confluence 应用程序层)。这个数据在4月21日的测试中高峰时达到每分钟125~140个, 而相比4月14日的测试,其中高峰时每分钟约100 个请求。
尽管看似成功的4月21日的第二轮负载测试,仍然存在有一些问题。4月21日负载测试的综合数据图表, 显示当CPU使用率达到100%的边界后(下图中的红色竖线),出现了多个性能数据波动。这表明,尽管上面所讨论的环境有所改善,但在较高负载时还存在着CPU瓶颈。
在数据库结果中记录了两轮测试之间一个极端反差。4月14日的测试中数据库的统计数据清晰显然 (请参考在第1步中的性能指标图),包含在程序达到CPU的瓶颈前,查询的数量和执行时间都出现大波动。 但想要在4月21日测试中,找到同一指标,你得用上你的显微镜和非常贴近地看向图表的底部(you have to break out your microscope and look very closely at the bottom of the chart)。
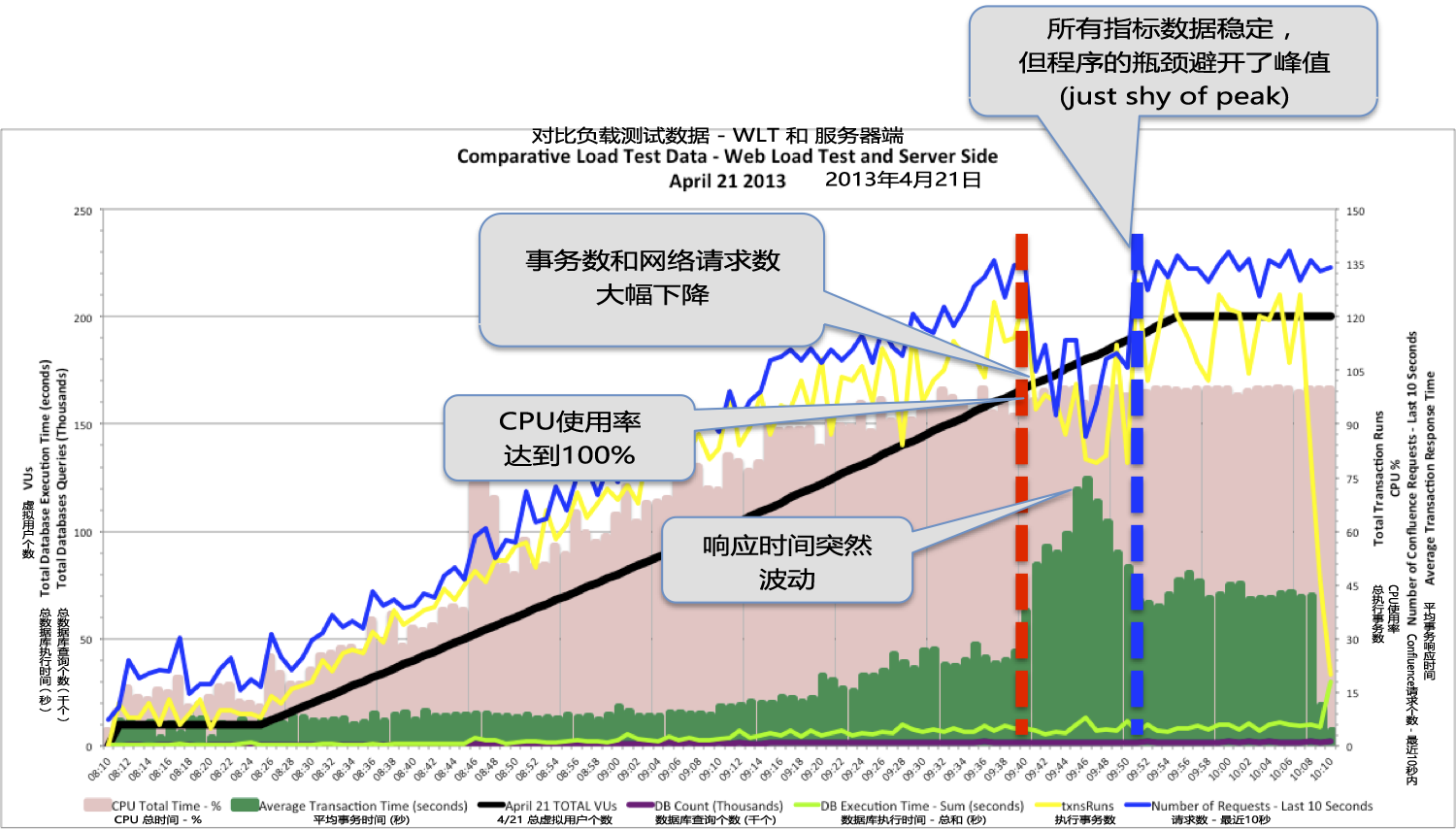
4月21日负载测试的外部与内部性能表现数据(点击图片见大图)
数据库负载的减少,是4月14日负载测试后,启用优化的缓存设置的直接结果。随着更多的数据被存储在应用程序缓存中,需要直接在数据库中查询的数量下降,此数据层在此目前负载量下不能再算为一个潜在的瓶颈。
在4月21日测试Confluence / Atlassian的处理过程没有突然的波动(连同数据库的波动)的,是由于在运行的负载测试期间, 移除了应用程序层定期执行的作业(job)。这个作业会影响到系统和用户体验,当Andreas审查他的数据,很快就确认出这个作业问题。 一旦这个作业被确认是造成这个问题的元凶,4月21日测试时它就被移除掉了,完全消除了这个早在4月14日测试时遇到的性能瓶颈。
教训:不要在流量高峰期安排会影响系统的作业;找到流量最低的一个时间段,并在此时间段执行这些作业,以便尽可能最少的游客受到影响。
正如我们在这篇文章的开始说的,表面上看,4月21日的负载测试比4月14日的测试,更加成功。 然而目前,尽管21日的负载测试性能表现有所提升,结果仍然显示出还有其他性能问题有待解决。 问题表现在负载测试运行后90分钟,在09:40和09:50之??间,响应时间出现非常奇怪的波动。
当系统开始性能退化,它会体现在这3个关键指标:WLT平均响应时间;WLT每分钟的交易;CPU利用率。 当正在运行的事务开始需要更长的时间来执行,同时网络到应用层请求数下降和测试工具中每分钟执行事务数下降,在下面的图表可以看到它的根本原因,此图去掉了一些数据(decreasing both the number of incoming web requests to the application layer and the number of transactions per minute executed by the load generation system, the root cause can be seen in the chart below, which removes some of the data series)。
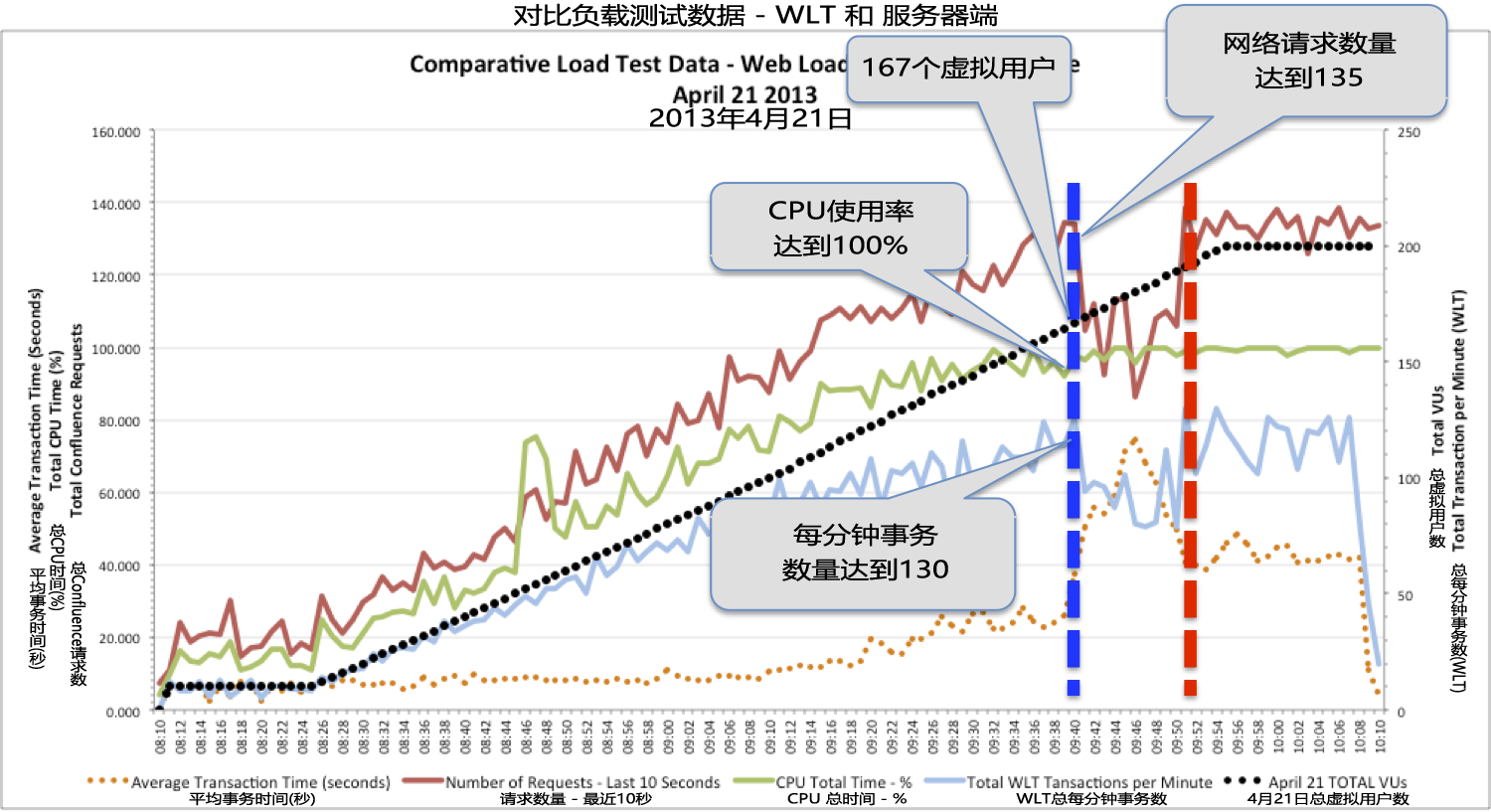
当167个虚拟用户时,是系统的临界值,之后突然10分钟内性能下降,然后恢复后,测试稳定在200个虚拟用户(点击图片见大图)
在负载测试进行到09:40时,这个性能下降期间被检测出来,同时:
WLT工具达到167个虚拟用户 网络服务器的CPU使用率达到100% WLT工具的每分钟事务数为平均130 Confluence的网络请求达到每分钟135次(这是APM社区网站的应用程序)有趣的是,10分钟后,这个问题彻底消失了,除了事务响应时间。响应时间没有回到波动前的水平,而是现在的平均响应时间比波动前的平均值要高出近20秒。随着系统到了200个虚拟用户顶峰时,并没有额外的负载增加,看着其他指标立即回到波动前的水平 - 尤其是每分钟事务数和每分钟请求数,非常有趣。 因此,波动后随着这33个虚拟用户增加,系统表现出又直接受到CPU瓶颈的影响,更高的负载并不能增加在应用程序层处理的请求数量。
抛开这些数据(Out of this sea of metrics),我们看到的是对比4月14日的测试,4月21日的负载测试时程序性能变现的确有所提升, 但第二轮测试仍无法达到预期目标 - 200个虚拟用户,存在一个瓶颈,导致性能急剧下降。
要找到阻碍4月21日测试达到目标(200个虚拟用户并且没有或很少性能退化)的CPU瓶颈的根源,我们必须更深入一些,检查服务器端的指标,特别是那些和应用程序服务器的健康状态相关的指标。 事务数下降是伴随系统出现的问题,当系统达到167个虚拟用户(The dip in transactions throughout the system is aligned with the issue captured when the system hit 167 VUs.)。 现在的问题是:事务处理数下降和事务响应时间增加是这种负载下的结果?还是性能下降真正根源的一个症状?
服务器端的数据显示,高垃圾回收(Garbage Collection)可能是一个问题,因为当系统性能下降,这个自动的过程凑巧地也同时发生了。很显然,当网络服务器的CPU已经被耗尽时,再执行一个非常有影响的任务,会导致性能大幅下降。
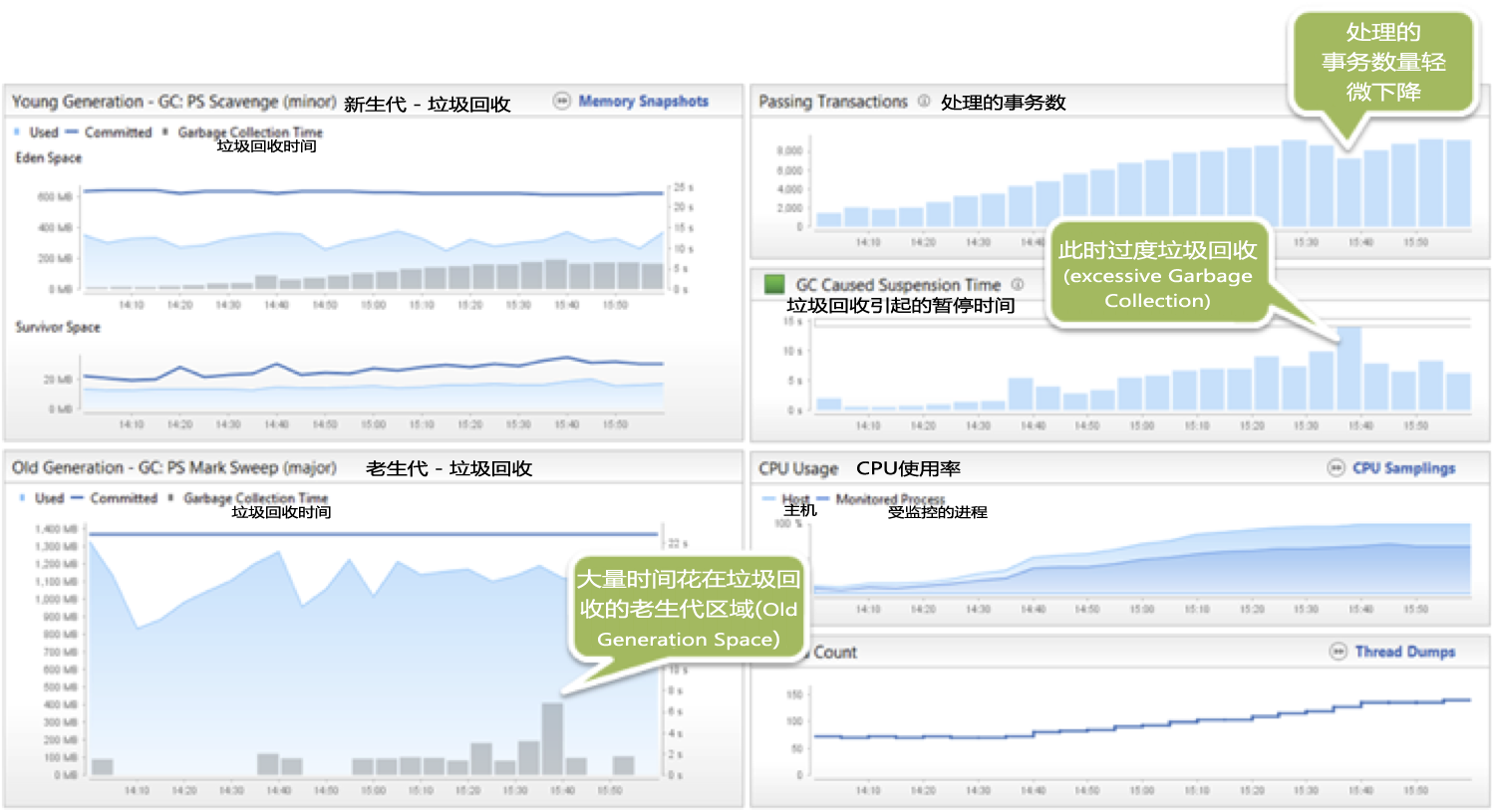
当负载增加,GC的增加是正常的 - 但有一个不寻常的波动正是当我们看到的这个事务数量下降(点击图片见大图)
检查在应用程序服务器具体的事务响应时间,很容易发现潜在问题。下面的图表显示,“又一个”后台作业依然在每隔一小时周期性地压榨已经被耗尽系统的CPU。

当虚拟用户经历性能下降时,后台作业每隔一小时执行一次,占用CPU的300S(点击图片见大图)
检查这些事务,该作业是每小时执行的更新作业,同步缓存的用户对象以及用户目录数据库(user directory database)。 这需要相当长的也值得重视的时间,因为我们APM社区系统中有65000多个用户。该更新的作业导致了很多对象的创建和销毁 - 因此增加的内存和GC活动。

同步作业是性能下降的根本原因,导致高GC活动,消耗了大量的CPU以及增加内存分配(点击图片见大图)
通过4月14日,4月21日的两轮负载测试,找出系统无达到200虚拟用户目标的不少的问题。 但是现在,我们知道阻碍达成这个目标的罪魁祸首,因此努力在高负载下,集中精力减少或消除此更新作业对系统的影响。
在这两轮测试中,无论你是如何衡量“成功的”负载测试,通过汇总测试中内部和外部硬件的指标, 我们现在知道,4月14日的负载测试之后进行的调优,使得系统在预定作业会导致了严重性能下降的情况下, 能够每分钟处理额外40%~50%的事务,支持多达167个虚拟用户。
只有有了这个数据才能转为可操作项,因为我们有一个程序能将防火墙内部采集到的数据, 很轻松地整合外部负载测试工具的结果数据。 这样,尽管是在非常受控的情况,也成为分析系统性能的一个因素。(This data was only able to be turned into actionable information because we had a process in place that allowed results captured from inside the firewall to be easily aligned with the external results from the load test system. By doing this, the customer, albeit in a very controlled form, becomes a factor in the analysis of system performance.)
通过创建一个完整的性能角度,PureStack比只提供负载下系统技术指标的,提供得更多。 当进行结果分析时,PureStack视用户体验的重要性如CPU,数据库和应用程序处理请求数一般。 根据用户体验的重要性,然后决定如何划分问题的优先级和如何解决他们。 这些对最终用户有影响的问题提供了真实世界的反馈 - 您的应用程序在峰值期间所出现性能问题的真实成本(The importance of the user experience then dictates how infrastructure issues are prioritized and resolved, as the effect these issues have on end users provides real-world feedback into the true cost of performance issues that occur to your application during peak periods)。
根据负载测试中的数据,可以确定系统需要的额外修改,特别是页面呈现方面,需要进一步降低CPU负荷, 使系统能够达到和保持负载峰值为200的虚拟用户。随着Confluence应用软件的升级 - 2013年7月初部署的程序 - 达到预期的目标。 但假设这是不够的,一旦系统已经稳定运行,2013年7月将会有对新Confluence系统的额外负载测试。 并且通过使用4月14日和21日的负载测试中同样事务的路径,将对新系统进行验证,以确认升级能带来所期望的性能表现。