对实时分析与离线分析的思考(二)
接上一篇blog对实时分析与离线分析的思考
昨天看了S4与Storm的设计,再结合之前对Microsoft的Dryad的了解,感觉有些共性是需要明确的。
在MapReduce这种“分裂-合并”模型出世之前,我们都采用“一层计算”的方式。比如统计“What I Have Done”这句话中每个词的出现频度。因为这种问题简单,目标数据量小,所以对我们的计算没有挑战。
分治思想早就有了,但在我印象中比较深刻的例子就是网络计算。把大型计算分裂成小型任务,然后交给志愿者的电脑执行后再合并结果。这也是MapReduce所做的事情。可以把MapReduce称为“两层计算”。核心问题就是利用并行化,解决遇到的大数据量或大计算量的问题。MapReduce的思想只有两步,也限制了它在做一些复杂计算时挺麻烦,比如Join,Sort等,需要多步MapReduce任务。当前Hadoop MapReduce在解决这些复杂任务时的缺点也在于每个MapReduce Job之间相互独立,有始有终。在任务序列中,后面Job不能有效利用前面Job的输出结果(局部性)。
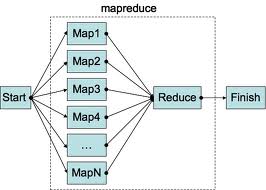
而对于这几种实时计算框架,同样是分治思想,但它的基本模型都是:有向无环图(DAG)。数据处理流程因为计算的复杂度,可以很方便地延伸。可以把这种模型称为“多层计算”。整个计算过程中,依然是并行化计算,数据不落地,在内存和网络中流动。用户可因计算的复杂度来规划计算流程的拓扑结构。它解决了MapReduce遇到的两个问题:1. 复杂计算硬套MapReduce时,流程冗长,很难编码。2. 任务有序列关系,但计算是独立的,不能利用局部化优势。
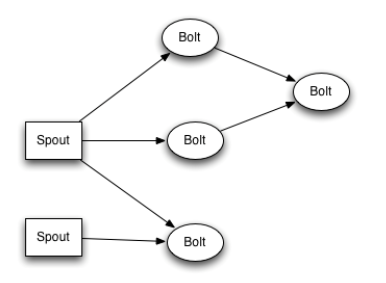
“两层模型”与“多层模型”在面对不同的业务场景时都是有价值的。我不太认同硬是将很多复杂的计算套在MapReduce模型上,这让理解起来挺困难,编码起来更恶心。好像这几种实时计算框架也提供了拓扑结构规划工具,这是很贴心的服务。
现在看来,对几种架构的共性总结就是:
1. 分析模型都是DAG
2. 依然并行化
3. 数据on the fly
继续学习中...