Java内存模型3
1)方法区(Method Area) 在JVM实例中,对装载的类型信息是存储在一个逻辑方法内存区中,当Java虚拟机加载了一个类型的时候,它会跟着这个Class的类型去路径里面查找对应的Class文件,类加载器读取类文件(线性二进制数据),然后将该文件传递给Java虚拟机,JVM从二进制数据中提取信息并且将这些信息存储在方法区,而类中声明(静态)变量就是来自于方法区中存储的信息。在JVM里面用什么样的方式存储该信息是由JVM设计的时候决定的,例如:当数据进入方法的时候,多类文件字节的存储量以Big-Endian(第一次最重要的字节)的顺序存储,尽管如此,一个虚拟机可以用任何方式针对这些数据进行存储操作,若它存储在一个Little-Endian处理器上,设计的时候就有可能将多文件字节的值按照Little-Endian顺寻存储。 ――【$Big-Endian和Little-Endian】―― 程序存储数据过程中,如果数据是跨越多个字节对象就必须有一种约定:
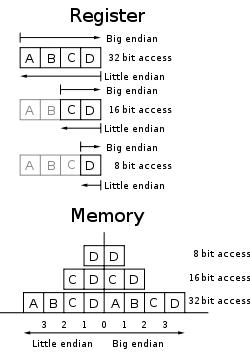 由上图可以看到,映射访问(“写32位地址的0”)主要是由寄存器到内存、由内存到寄存器的一种数据映射方式,Big-Endian在上图可以看出的原子内存单位(Atomic Unit)在系统内存中的增长方向为从左到右,而Little-Endian的地址增长方向为从右到左。举个例子: 若要存储数据0x0A0B0C0D: Big-Endian: 以8位为一个存储单位,其存储的地址增长为:
由上图可以看到,映射访问(“写32位地址的0”)主要是由寄存器到内存、由内存到寄存器的一种数据映射方式,Big-Endian在上图可以看出的原子内存单位(Atomic Unit)在系统内存中的增长方向为从左到右,而Little-Endian的地址增长方向为从右到左。举个例子: 若要存储数据0x0A0B0C0D: Big-Endian: 以8位为一个存储单位,其存储的地址增长为: 上图中可以看出MSB的值存储了0x0A,这种情况下数据的高位是从内存的低地址开始存储的,然后从左到右开始增长,第二位0x0B就是存储在第二位的,如果是按照16位为一个存储单位,其存储方式又为:
上图中可以看出MSB的值存储了0x0A,这种情况下数据的高位是从内存的低地址开始存储的,然后从左到右开始增长,第二位0x0B就是存储在第二位的,如果是按照16位为一个存储单位,其存储方式又为: 则可以看到Big-Endian的映射地址方式为:?
则可以看到Big-Endian的映射地址方式为:?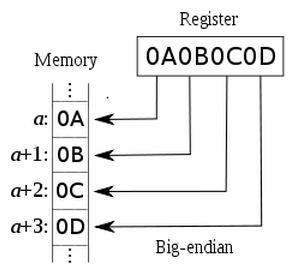 MSB:在计算机中,最高有效位(MSB)是指位值的存储位置为转换为二进制数据后的最大值,MSB有时候在Big-Endian的架构中称为最左最大数据位,这种情况下再往左边的内存位则不是数据位了,而是有效位数位置的最高符号位,不仅仅如此,MSB也可以对应一个二进制符号位的符号位补码标记:“1”的含义为负,“0”的含义为正。最高位代表了“最重要字节”,也就是说当某些多字节数据拥有了最大值的时候它就是存储的时候最高位数据的字节对应的内存位置:
MSB:在计算机中,最高有效位(MSB)是指位值的存储位置为转换为二进制数据后的最大值,MSB有时候在Big-Endian的架构中称为最左最大数据位,这种情况下再往左边的内存位则不是数据位了,而是有效位数位置的最高符号位,不仅仅如此,MSB也可以对应一个二进制符号位的符号位补码标记:“1”的含义为负,“0”的含义为正。最高位代表了“最重要字节”,也就是说当某些多字节数据拥有了最大值的时候它就是存储的时候最高位数据的字节对应的内存位置: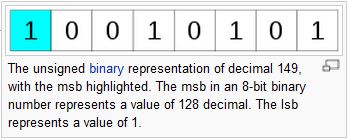 Little-Endian: 与Big-Endian相对的就是Little-Endian的存储方式,同样按照8位为一个存储单位上边的数据0x0A0B0C0D存储格式为:
Little-Endian: 与Big-Endian相对的就是Little-Endian的存储方式,同样按照8位为一个存储单位上边的数据0x0A0B0C0D存储格式为: 可以看到LSB的值存储的0x0D,也就是数据的最低位是从内存的低地址开始存储的,它的高位是从右到左的顺序逐渐增加内存分配空间进行存储的,如果按照十六位为存储单位存储格式为:
可以看到LSB的值存储的0x0D,也就是数据的最低位是从内存的低地址开始存储的,它的高位是从右到左的顺序逐渐增加内存分配空间进行存储的,如果按照十六位为存储单位存储格式为: 从上图可以看到最低的16位的存储单位里面存储的值为0x0C0D,接着才是0x0A0B,这样就可以看到按照数据从高位到低位在内存中存储的时候是从右到左进行递增存储的,实际上可以从写内存的顺序来理解,实际上数据存储在内存中无非在使用的时候是写内存和读内存,针对LSB的方式最好的书面解释就是向左增加来看待,如果真正在进行内存读写的时候使用这样的顺序,其意义就体现出来了:
从上图可以看到最低的16位的存储单位里面存储的值为0x0C0D,接着才是0x0A0B,这样就可以看到按照数据从高位到低位在内存中存储的时候是从右到左进行递增存储的,实际上可以从写内存的顺序来理解,实际上数据存储在内存中无非在使用的时候是写内存和读内存,针对LSB的方式最好的书面解释就是向左增加来看待,如果真正在进行内存读写的时候使用这样的顺序,其意义就体现出来了: 按照这种读写格式,0x0D存储在最低内存地址,而从右往左的增长就可以看到LSB存储的数据为0x0D,和初衷吻合,则十六位的存储就可以按照下边的格式来解释:
按照这种读写格式,0x0D存储在最低内存地址,而从右往左的增长就可以看到LSB存储的数据为0x0D,和初衷吻合,则十六位的存储就可以按照下边的格式来解释: 实际上从上边的存储还会考虑到另外一个问题,如果按照这种方式从右往左的方式进行存储,如果是遇到Unicode文字就和从左到右的语言显示方式相反。比如一个单词“XRAY”,使用Little-Endian的方式存储格式为:
实际上从上边的存储还会考虑到另外一个问题,如果按照这种方式从右往左的方式进行存储,如果是遇到Unicode文字就和从左到右的语言显示方式相反。比如一个单词“XRAY”,使用Little-Endian的方式存储格式为: 使用这种方式进行内存读写的时候就会发现计算机语言和语言本身的顺序会有冲突,这种冲突主要是以使用语言的人的习惯有关,而书面化的语言从左到右就可以知道其冲突是不可避免的。我们一般使用语言的阅读方式都是从左到右,而低端存储(Little-Endian)的这种内存读写的方式使得我们最终从计算机里面读取字符需要进行倒序,而且考虑另外一个问题,如果是针对中文而言,一个字符是两个字节,就会出现整体顺序和每一个位的顺序会进行两次倒序操作,这种方式真正在制作处理器的时候也存在一种计算上的冲突,而针对使用文字从左到右进行阅读的国家而言,从右到左的方式(Big-Endian)则会有这样的文字冲突,另外一方面,尽管有很多国家使用语言是从右到左,但是仅仅和Big-Endian的方式存在冲突,这些国家毕竟占少数,所以可以理解的是,为什么主流的系统都是使用的Little-Endian的方式 【*:这里不解释Middle-Endian的方式以及Mixed-Endian的方式】 LSB:在计算机中,最低有效位是一个二进制给予单位的整数,位的位置确定了该数据是一个偶数还是奇数,LSB有时被称为最右位。在使用具体位二进制数之内,常见的存储方式就是每一位存储1或者0的方式,从0向上到1每一比特逢二进一的存储方式。LSB的这种特性用来指定单位位,而不是位的数字,而这种方式也有可能产生一定的混乱。
使用这种方式进行内存读写的时候就会发现计算机语言和语言本身的顺序会有冲突,这种冲突主要是以使用语言的人的习惯有关,而书面化的语言从左到右就可以知道其冲突是不可避免的。我们一般使用语言的阅读方式都是从左到右,而低端存储(Little-Endian)的这种内存读写的方式使得我们最终从计算机里面读取字符需要进行倒序,而且考虑另外一个问题,如果是针对中文而言,一个字符是两个字节,就会出现整体顺序和每一个位的顺序会进行两次倒序操作,这种方式真正在制作处理器的时候也存在一种计算上的冲突,而针对使用文字从左到右进行阅读的国家而言,从右到左的方式(Big-Endian)则会有这样的文字冲突,另外一方面,尽管有很多国家使用语言是从右到左,但是仅仅和Big-Endian的方式存在冲突,这些国家毕竟占少数,所以可以理解的是,为什么主流的系统都是使用的Little-Endian的方式 【*:这里不解释Middle-Endian的方式以及Mixed-Endian的方式】 LSB:在计算机中,最低有效位是一个二进制给予单位的整数,位的位置确定了该数据是一个偶数还是奇数,LSB有时被称为最右位。在使用具体位二进制数之内,常见的存储方式就是每一位存储1或者0的方式,从0向上到1每一比特逢二进一的存储方式。LSB的这种特性用来指定单位位,而不是位的数字,而这种方式也有可能产生一定的混乱。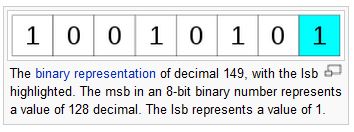 ――以上是关于Big-Endian和Little-Endian的简单讲解―― JVM虚拟机将搜索和使用类型的一些信息也存储在方法区中以方便应用程序加载读取该数据。设计者在设计过程也考虑到要方便JVM进行Java应用程序的快速执行,而这种取舍主要是为了程序在运行过程中内存不足的情况能够通过一定的取舍去弥补内存不足的情况。在JVM内部,所有的线程共享相同的方法区,因此,访问方法区的数据结构必须是线程安全的,如果两个线程都试图去调用去找一个名为Lava的类,比如Lava还没有被加载,只有一个线程可以加载该类而另外的线程只能够等待。方法区的大小在分配过程中是不固定的,随着Java应用程序的运行,JVM可以调整其大小,需要注意一点,方法区的内存不需要是连续的,因为方法区内存可以分配在内存堆中,即使是虚拟机JVM实例对象自己所在的内存堆也是可行的,而在实现过程是允许程序员自身来指定方法区的初始化大小的。 同样的,因为Java本身的自动内存管理,方法区也会被垃圾回收的,Java程序可以通过类扩展动态加载器对象,类可以成为“未引用”向垃圾回收器进行申请,如果一个类是“未引用”的,则该类就可能被卸载, 而方法区针对具体的语言特性有几种信息是存储在方法区内的: 【类型信息】:
――以上是关于Big-Endian和Little-Endian的简单讲解―― JVM虚拟机将搜索和使用类型的一些信息也存储在方法区中以方便应用程序加载读取该数据。设计者在设计过程也考虑到要方便JVM进行Java应用程序的快速执行,而这种取舍主要是为了程序在运行过程中内存不足的情况能够通过一定的取舍去弥补内存不足的情况。在JVM内部,所有的线程共享相同的方法区,因此,访问方法区的数据结构必须是线程安全的,如果两个线程都试图去调用去找一个名为Lava的类,比如Lava还没有被加载,只有一个线程可以加载该类而另外的线程只能够等待。方法区的大小在分配过程中是不固定的,随着Java应用程序的运行,JVM可以调整其大小,需要注意一点,方法区的内存不需要是连续的,因为方法区内存可以分配在内存堆中,即使是虚拟机JVM实例对象自己所在的内存堆也是可行的,而在实现过程是允许程序员自身来指定方法区的初始化大小的。 同样的,因为Java本身的自动内存管理,方法区也会被垃圾回收的,Java程序可以通过类扩展动态加载器对象,类可以成为“未引用”向垃圾回收器进行申请,如果一个类是“未引用”的,则该类就可能被卸载, 而方法区针对具体的语言特性有几种信息是存储在方法区内的: 【类型信息】: