【大数据挖掘学习-2】关联规则挖掘
一、关联规则挖掘简介
首先,对市场-篮子模型进行介绍
超市货架管理――市场-篮子模型:经典的规则:若一个用户购买了尿布和牛奶,那么他很有可能购买啤酒。因此若在超市看到尿布旁边摆放了一些啤酒不要惊讶。
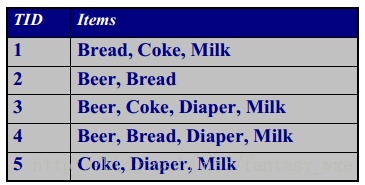
以上每行的第一列表示对篮子的标号,第二列表示篮子中购买的物品。从上表的数据可获得如下的规则:{Milk} ――> {Coke}; {Diaper, Milk} ――>{Beer};
市场-篮子模型涉及如下的概念:
1)大的物品集。例如超市中买的所有东西
2)大的篮子集。各个篮子里是用户购买的超市所有物品集的子集
市场-篮子模型可以认为是两类对象之间的通用的多对多映射(关联),不过我们关注的是“物品”之间的关联,而不是篮子之间。
关联规则的挖掘方法:
给定篮子集,我们想要挖掘关联规则,所谓的关联规则即人们购买了{x, y, z}倾向于购买{v, w}。
那么对于关联规则的挖掘我们分为两步来进行:
1)寻找频繁集项
2)产生关联规则
对于上面的表格,
输入为:
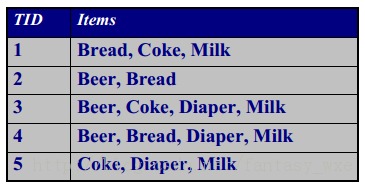
输出为:

那么以下对频繁集项和关联规则进行介绍
频繁集项(Frequent Itemsets)
首先,最简单的问题是,在所有篮子中寻找同时“频繁”出现的物品集。
同时涉及物品集I的支持度的问题,所谓物品集I支持度,就是在所有篮子中,包含物品集I的篮子的数目,通常用与总的篮子数的比例来表示。即
支持度 = 包含物品集I的篮子数 / 总的篮子数
对于上表中的数据,{beer, bread}的支持度为:2,若用比例来表达为:2 / 5
那么什么是频繁集项呢?
就是给定支持度阈值s,若所有的篮子中,给定物品集的支持度大于或等于s,则称该物品集为频繁集项。
举例:
给定如下物品集:
Items = {milk, coke, pepsi, beer, juice}
那么可以得出如下的结果:

上面的结果表示给定最小支持度阈值为3,那么大于或等于最小支持度的的频繁集项下面列出的所示。
关联规则(Assoiciation Rules)
即是给定篮子里的内容,从中挖掘if-then形式的规则。即如下形式
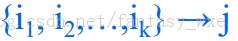
上面的形式表示:若一个篮子包含所有的i1,i2,...,ik,那么它很有可能包含j。
在实际应用中还有很多的规则,我们通常从中寻找有意义的/有趣的规则。
在关联规则中,涉及如下的概念置信度(Confidence)。
关联规则的置信度就是给定I = {i1, i2, ..., ik}情况下,出现j的概率。
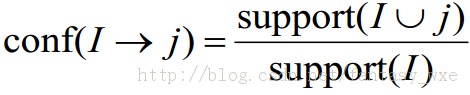
然而,需要注意的是,并不是所有的高置信度规则都是有意义的,比如规则X--->milk对于很多的物品集X拉说都有高置信度。
引出如下概念:关联规则I--->j的兴趣(Interest)
定义为该关联规则的执行度与其包含j的篮子的概率之差。因此,感兴趣的规则是那么高的正或负兴趣值(interest value)。
对于那些不感兴趣的规则,那么包含j的篮子的概率与包含{I,j}的子集篮子相等,这样,将导致置信度非常高,而兴趣值很低。
举例:
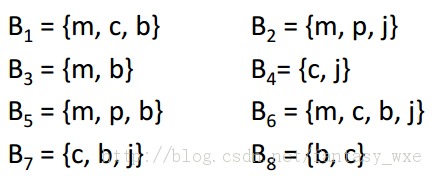
对于关联规则:{m,b}--->c
执行度(confidence)=2/4=0.5
兴趣值(interest)=|0.5 - 5/8| = 1/8
其中,1)物品c在篮子中出现的概率为5/8。2)规则不是非常的感兴趣。
二、寻找关联规则
寻找关联规则:即是寻找所有的关联规则使支持度大于等于s(support ≥ s)以及置信度大于等于(confidence ≥ c),注意一个关联规则的置信度是左边的所有物品集的支持度。
那么如何寻找关联规则呢?
待续...