Levenshtein Distance算法java实现,英文单词相似度
昨儿突发奇想,想做一个关于英文单词按“形近词”分组的app,这个app最关键的就是这个“形近词”判断,经过思考和查资料,开始有了些眉目,看到了visionfans写的博客使用Matlab实现英文单词的"形近词"查找(http://blog.csdn.net/visionfans/article/details/6618652)就参照他的把算法用java实现了一下,效果出来了,但是很担心整个算法的效率问题,刚刚接触,对算法效率了解的甚少,还请大牛指点。
这个对两个单词“形近度”的判别是建立在一个矩阵上的,以本文为例,将两个单词存储在两个数组s1,s2中,然后根据两个数组的长度建立一个s2.length行s1.length列的矩阵,并将矩阵初始化,如图
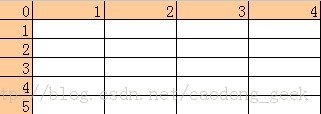
下一步就是按照算法将这个矩阵中的数值填入,再填入之前,为了比较的时候方便,我们在这个矩阵外围把存在数组中的值加上,注意,仅仅是为了理解方便,真正的数组矩阵中不添加这一项,如下图蓝色区域:
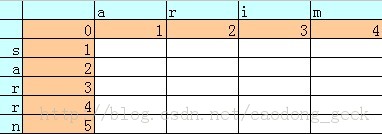
比较过程:我们以橙色区域的数字为编号,“0”的坐标为(0,0)以此类推左上角第一个白色方块坐标为(1,1)……按咧进行匹配(即先将“a”分别同这一列的"s","a","r","r","n"进行比较,然后再以此向右进行)如果第一个单词的第一个字母(本例中的"a")与第二个单词的第一个字母(本例中的"s")相同,则定义的temp变量的值赋“0”否则赋“1”,然后这两个字母交集的区域(本例中坐标为(1,1))的数值取与之相邻的左,上,左上分别+1,+1,+temp如图:
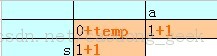
然后向这三个值中的最小值赋给空白区域,作为其数值,按照这个方式把整个矩阵填满,然后矩阵中最后一个元素即最右下角的元素的数组就是两个单词的编辑距离也就是“区别度”,这个是指一个字符串A需要经过多少次编辑可以得到字符串B。
自己写了一个Java版的算法如下:
package englishword;public class Ledit {public static void main(String[] args) {char[] s1={'a','r','i','m'};//预置单词char[] s2={'s','a','r','r','n'};int m=s2.length+1,n=s1.length+1;//矩阵int[][] table=new int[m][n];// 矩阵的初始化for(int i=0;i<n;i++){table[0][i]=i;}for(int i=0;i<m;i++){table[i][0]=i;}//算法开始,向矩阵中添加数值for(int i=0;i<n-1;i++){for(int j=0;j<m-1;j++){int temp=0;if(s1[i]!= s2[j])temp=1;elsetemp=0;table[j+1][i+1]=Min(table[j][i]+temp,table[j+1][i]+1,table[j][i+1]+1);}}//输出矩阵for(int i=0;i<m;i++){for(int j=0;j<n;j++){System.out.print(table[i][j]);System.out.print(",");}System.out.println();}}private static int Min(int i, int j, int k) {// TODO Auto-generated method stubint[] tempSequence={i,j,k};int min=i;for(int n=0;n<3;n++){if(tempSequence[n]<min){min=tempSequence[n];}}return min;}}在理解了这个算法的运用时,遇到了一个疑问,就是这些矩阵中的每一个数字代表了什么,尤其是给矩阵初始化时填充的数字的用途。后来想到了一种解释,分享一下,如有错误欢迎指正。
我认为,矩阵的初始化的数字相当于标记了每个单词的位置,每个字母与同词的其他字母的相对位置是不变的,这个位置有什么用呢,我认为两个单词的编辑距离有2个分类,一个是相同位置但是字母不一样,需要一次编辑,另一个是相同字母不同位置,也需要一次编辑。
这里关于+1或者+temp我还没有研究出来,只是猜想的是字母匹配成功所要付出的代价“移位”、“插入”所需要的编辑次数,只是还没有研究明白,希望可以得到指点。万分感谢。