mahout源码分析之Decision Forest 三部曲之二BuildForest(3)Step1Mapper(2)
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
接上篇,分析到OptIgSplitl类的computeSplit函数里面的numbericalSplit函数,看这个函数的输入参数data和attr,应该是针对data计算出一个和attr相关的值而已。往下看
double[] values = sortedValues(data, attr); ,这一句是干啥的?
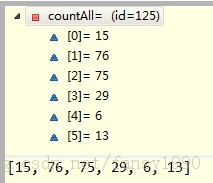
继续往下:int size = data.size(); double hy = entropy(countAll, size);这里的size就是214,entropy是啥来的?
下面的公式中pi是每个label的重复值除以总数214的结果。在继续往下面看:
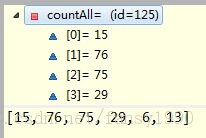
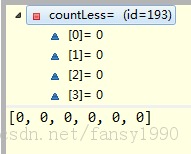
运行最后两行代码后,变为:
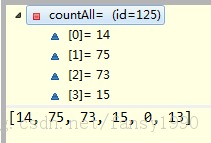
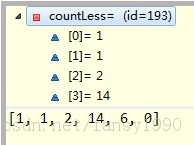
这样就不用我多说了吧,等于是把counts里面的第一条记录加到countLess中,然后再把countAll中相应的次数减去第一条记录。
下面的就是按照这种规律循环遍历最后得到一个 attr --> bestIg 、bestIndex 的对应关系,然后输出 return new Split(attr, bestIg, values[best]);
今晚就到这里吧,不要熬夜。。。
感觉好像更新小说的样子。。。最近看小说太不给力了,卤煮跟新好慢。不过写这个算法更新更慢。哎,看源码。。。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990