mahout源码分析之Decision Forest 三部曲之二BuildForest(3)Step1Mapper(3)
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
接上篇,先来说说上篇最后的bestIg和bestIndex的求法。在说这个前,要首先明确一个数组的熵的求法,按照mahout中的源码针对这样的一个数组a=[1,3,7,3,0,2]其熵为:
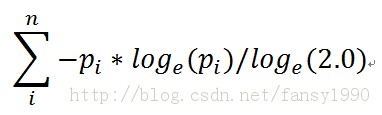
设sum=1+3+7+3+0+2,则其中pi对应于1/sum、3/sum、7/sum、3/sum、2/sum(其中若数组中的元素为0,则不参与计算),这个是数组熵的计算。
假如我有这样的一个数组counts:
可以看到52+162=214,这说明这两个数组的确是由214条记录分离得到的。且分别观察loSubset、hiSubset,可以看到里面属性attr的值都是分别<bestSplit和>=bestSplit的。下面到了Node loChild = build(rng, loSubset);然后又到了build函数,这次data是含有52条记录的数据了。然后又随机取出三个属性,计算得到最优的属性,然后再按照最优的属性把数据分为两部分,然后再build()。啥时候退出循环呢?
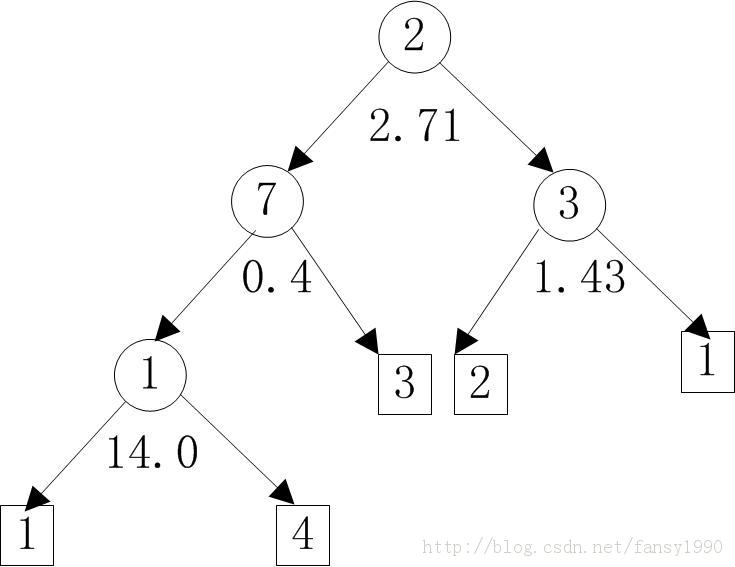
对应的树画出来如下所示:
左边是属性值小于中间的那个数字的,右边是大于或等于的。然后就是设置下输出的格式key.set(partition, firstTreeId + treeId);
// if (!isNoOutput()) {
MapredOutput emOut = new MapredOutput(tree);然后直接输出了,比如Step1MapperFollow的输出如下:
key:2***value:{NUMERICAL:NUMERICAL:NUMERICAL:LEAF:;,LEAF:;;,LEAF:;;,NUMERICAL:LEAF:;,LEAF:;;; | null}这样表示输出3棵树,其中最后一棵树就是上图的那棵树的打印字符串。这样Step1Mapper的仿制代码就分析完了,其实就是Step1Mapper的工作流分析完了。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990