借@阿里巴巴 耍了个帅——HTML5 JavaScript实现图片文字识别与提取
8月底的时候,@阿里巴巴 推出了一款名为“拯救斯诺克”的闯关游戏,作为前端校园招聘的热身,做的相当不错,让我非常喜欢。后来又传出了一条消息,阿里推出了A-star(阿里星)计划,入职阿里的技术培训生,将接受CTO等技术大牛的封闭培训,并被安排到最有挑战的项目中,由技术带头人担任主管。于是那几天关注了一下阿里巴巴的消息,结果看到这么一条微博(http://e.weibo.com/1897953162/A79Lpcvhi):
此刻,@阿里足球队 可爱的队员们已经出征北上。临走前,后防线的队员们留下一段亲切的问候,送给对手,看@新浪足球队 的前锋们如何破解。@袁甲 @蓝耀栋 #阿里新浪足球世纪大战#
目测是一段Base64加密过的信息,但无奈的是这段信息是写在图片里的,我想看到解密后的内容难道还一个字一个字地打出来?这么懒这么怕麻烦的我肯定不会这么做啦→_→想到之前有看到过一篇关于HTML5实现验证码识别的文章,于是顿时觉得也应该动手尝试一下,这才是极客的风范嘛!
先来一个大家最喜欢的Demo地址(识别过程需要一定时间,请耐心等待,识别结果请按F12打开Console控制台查看):
http://www.clanfei.com/demos/recognition/
再来张效果图: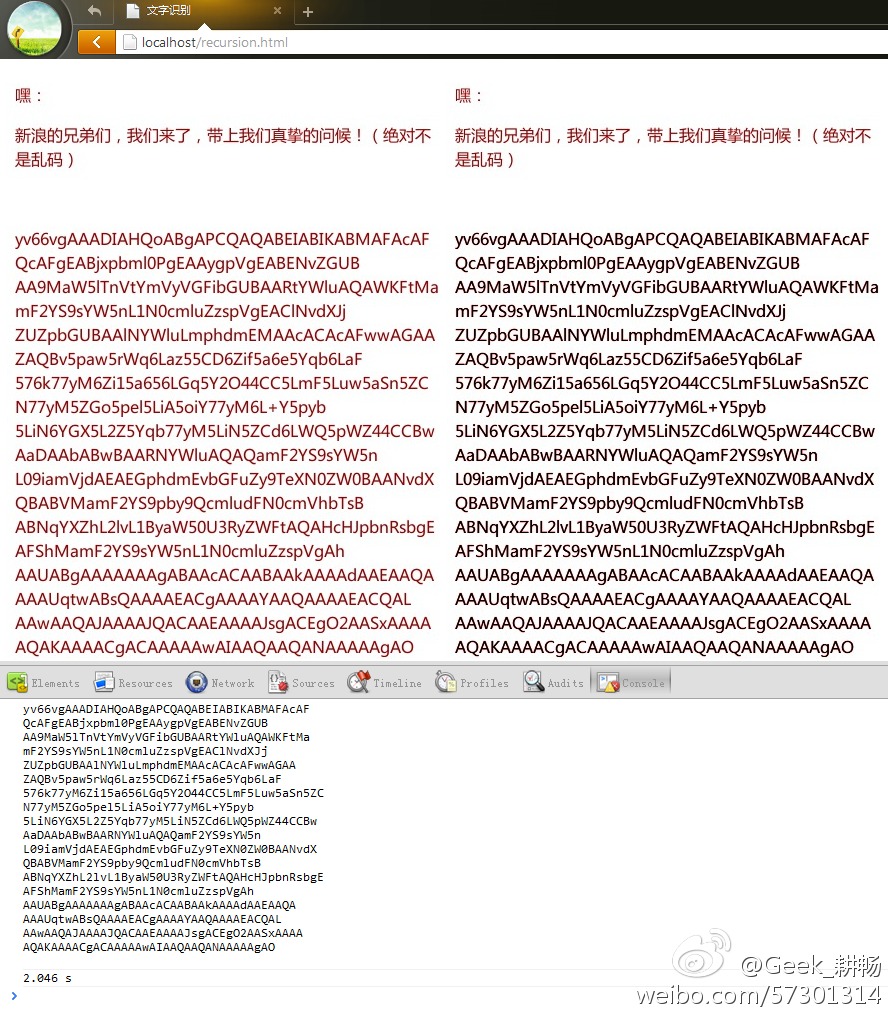
实现一个算法,思路是最重要的,而实现不过是把思想转化为能够运行的代码。
简单地说,要进行文本识别,自然是拿图片的数据与文字的图形数据进行对比,找到与图片数据匹配程度最高的字符。
首先,先确定图片中文本所用的字体、字号、行距等信息,打开PhotoShop,确定了字体为微软雅黑,16像素,行距为24,Base64文字的开始坐标为(8, 161)。
然后,确定要进行匹配的字库,Base64编码中可能出现的字符为26个字母大小写、10个数字、加号、斜杠,但目测在图片中没有斜杠出现,因此字库应该为:
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ+
接着,是确定如何判断字符是否匹配,由于只需要对字型进行匹配,因此颜色值对算法并无用处,因此将其灰度化(详见百度百科),并使用01数组表示,1代表该像素点落在此字符图形上,0反之,而如何确定该某个灰度值在数组中应该表示为0还是1,这个转换公式更是算法中的关键。
最后,将字型的灰度化数据与图片中文字部分的灰度化数据进行对比,将误差最小的字型作为匹配到的字符,然后进行下一个字符的匹配,直到图片中所有字符匹配完毕为止。
详细的思路于代码注释中,个人觉得这样结合上下文更为容易理解(注:代码应运行于服务器环境,否则会出现跨域错误,代码行数虽多,但注释就占了大半,有兴趣可以耐心看完,图片资源于上方“写在前面”)。
- <!doctype html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <title>文字识别</title>
- </head>
- <body>
- <canvas id="canvas" width="880" height="1500"></canvas>
- <script type="text/javascript">
- var image = new Image();
- image.onload = recognition;
- image.src = 'image.jpg';
- function recognition(){
- // 开始时间,用于计算耗时
- var beginTime = new Date().getTime();
- // 获取画布
- var canvas = document.getElementById('canvas');
- // 字符库
- var letters = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ+';
- // 字型数据
- var letterData = {};
- // 获取context
- var context = canvas.getContext('2d');
- // 设置字体、字号
- context.font = '16px 微软雅黑';
- // 设置文字绘制基线为文字顶端
- context.textBaseline = 'top';
- // 一个循环获取字符库对应的字型数据
- for(var i = 0; i < letters.length; ++i){
- var letter = letters[i];
- // 获取字符绘制宽度
- var width = context.measureText(letter).width;
- // 绘制白色背景,与图片背景对应
- context.fillStyle = '#fff';
- context.fillRect(0, 0, width, 22);
- // 绘制文字,以获取字型数据
- context.fillStyle = '#000';
- context.fillText(letter, 0, 0);
- // 缓存字型灰度化0-1数据
- letterData[letter] = {
- width : width,
- data : getBinary(context.getImageData(0, 0, width, 22).data)
- }
- // 清空该区域以获取下个字符字型数据
- context.clearRect(0, 0, width, 22);
- }
- // console.log(letterData);
- // 绘制图片
- context.drawImage(this, 0, 0);
- // 要识别的文字开始坐标
- var x = beginX = 8;
- var y = beginY = 161;
- // 行高
- var lineHeight = 24;
- // 递归次数
- var count = 0;
- // 结果文本
- var result = '';
- // 递归开始
- findLetter(beginX, beginY, '');
- // 递归函数
- function findLetter(x, y, str){
- // 找到结果文本,则递归结束
- if(result){
- return;
- }
- // 递归次数自增1
- ++ count;
- // console.log(str);
- // 队列,用于储存可能匹配的字符
- var queue = [];
- // 循环匹配字符库字型数据
- for(var letter in letterData){
- // 获取当前字符宽度
- var width = letterData[letter].width;
- // 获取该矩形区域下的灰度化0-1数据
- var data = getBinary(context.getImageData(x, y, width, 22).data);
- // 当前字符灰度化数据与当前矩形区域下灰度化数据的偏差量
- var deviation = 0;
- // 一个临时变量以确定是否到了行末
- var isEmpty = true;
- // 如果当前矩形区域已经超出图片宽度,则进行下一个字符匹配
- if(x + width > 440){
- continue;
- }
- // 计算偏差
- for(var i = 0, l = data.length; i < l; ++i){
- // 如果发现存在的有效像素点,则确定未到行末
- if(isEmpty && data[i]){
- isEmpty = false;
- }
- // 不匹配的像素点,偏差量自增1
- if(data[i] != letterData[letter].data[i]){
- ++deviation;
- }
- }
- // 由于调试时是在猎豹浏览器下进行的,而不同浏览器下的绘图API表现略有不同
- // 考虑到用Chrome的读者应该也不少,故简单地针对Chrome对偏差进行一点手动微调
- // (好吧,我承认我是懒得重新调整getBinary方法的灰度化、0-1化公式=_=||)
- // 下面这段if分支在猎豹浏览器下可以删除
- if(letter == 'F' || letter == 'E'){
- deviation -= 6;
- }
- // 如果匹配完所有17行数据,则递归结束
- if(y > beginY + lineHeight * 17){
- result = str;
- break;
- }
- // 如果已经到了行末,重置匹配坐标
- if(isEmpty){
- x = beginX;
- y += lineHeight;
- str += '\n';
- }
- // 如果偏差量与宽度的比值小于3,则纳入匹配队列中
- // 这里也是算法中的关键点,怎样的偏差量可以纳入匹配队列中
- // 刚开始是直接用绝对偏差量判断,当偏差量小于某个值的时候则匹配成功,但调试过程中发现不妥之处
- // 字符字型较小的绝对偏差量自然也小,这样l,i等较小的字型特别容易匹配成功
- // 因此使用偏差量与字型宽度的比值作为判断依据较为合理
- // 而这个判断值3的确定也是难点之一,大了递归的复杂度会大为增长,小了很可能将正确的字符漏掉
- if(deviation / width < 3){
- queue.push({
- letter : letter,
- width : width,
- deviation : deviation
- });
- }
- }
- // 如果匹配队列不为空
- if(queue.length){
- // 对队列进行排序,同样是根据偏差量与字符宽度的比例
- queue.sort(compare);
- // console.log(queue);
- // 从队头开始进行下一个字符的匹配
- for(var i = 0; i < queue.length && ! result; ++i){
- var item = queue[i];
- // 下一步递归
- findLetter(x + item.width, y, str + item.letter);
- }
- }else{
- return false;
- }
- }
- // 递归结束
- // 两个匹配到的字符的比较方法,用于排序
- function compare(letter1, letter2){
- return letter1.deviation / letter1.width - letter2.deviation / letter2.width;
- }
- // 图像数据的灰度化及0-1化
- function getBinary(data){
- var binaryData = [];
- for(var i = 0, l = data.length; i < l; i += 4){
- // 尝试过三种方式
- // 一种是正常的灰度化公式,无论系数如何调整都无法与绘制的文字字型数据很好地匹配
- // binaryData[i / 4] = (data[i] * 0.3 + data[i + 1] * 0.59 + data[i + 2] * 0.11) < 90;
- // 一种是自己是通过自己手动调整系数,结果虽然接近但总是不尽人意
- // binaryData[i / 4] = data[i] < 250 && data[i + 1] < 203 && data[i + 2] < 203;
- // 最后使用了平均值,结果比较理想
- binaryData[i / 4] = (data[i] + data[i + 1] + data[i + 2]) / 3 < 200;
- }
- return binaryData;
- }
- console.log(result);
- // 输出耗时
- console.log(count, (new Date().getTime() - beginTime) / 1000 + ' s');
- // 将文字绘制到图片对应位置上,以方便查看提取是否正确
- context.drawImage(this, this.width, 0);
- var textArray = result.split('\n');
- for(var i = 0; i < textArray.length; ++i){
- context.fillText(textArray[i], this.width + beginX, beginY + lineHeight * i);
- }
- }
- </script>
- </body>
- </html>
Win7 64位,i3-3220 CPU 3.30 GHz,8G内存
- yv66vgAAADIAHQoABgAPCQAQABEIABIKABMAFAcAF
- QcAFgEABjxpbml0PgEAAygpVgEABENvZGUB
- AA9MaW5lTnVtYmVyVGFibGUBAARtYWluAQAWKFtMa
- mF2YS9sYW5nL1N0cmluZzspVgEAClNvdXJj
- ZUZpbGUBAAlNYWluLmphdmEMAAcACAcAFwwAGAA
- ZAQBv5paw5rWq6Laz55CD6Zif5a6e5Yqb6LaF
- 576k77yM6Zi15a656LGq5Y2O44CC5LmF5Luw5aSn5ZC
- N77yM5ZGo5pel5LiA5oiY77yM6L+Y5pyb
- 5LiN6YGX5L2Z5Yqb77yM5LiN5ZCd6LWQ5pWZ44CCBw
- AaDAAbABwBAARNYWluAQAQamF2YS9sYW5n
- L09iamVjdAEAEGphdmEvbGFuZy9TeXN0ZW0BAANvdX
- QBABVMamF2YS9pby9QcmludFN0cmVhbTsB
- ABNqYXZhL2lvL1ByaW50U3RyZWFtAQAHcHJpbnRsbgE
- AFShMamF2YS9sYW5nL1N0cmluZzspVgAh
- AAUABgAAAAAAAgABAAcACAABAAkAAAAdAAEAAQA
- AAAUqtwABsQAAAAEACgAAAAYAAQAAAAEACQAL
- AAwAAQAJAAAAJQACAAEAAAAJsgACEgO2AASxAAAA
- AQAKAAAACgACAAAAAwAIAAQAAQANAAAAAgAO
- 715 1.984 s(猎豹)
- 772 15.52 s(Chrome)
(递归次数谷歌只比猎豹多几十,耗时却对了十几秒,看来猎豹真的比Chrome快?)
其实非递归实现只是递归实现前做的一点小尝试,只在猎豹下调试完成,因为不舍得删,所以顺便贴出来了,使用Chrome的各位就不要跑了(我真的不是在给猎豹做广告= =||)。
- <!doctype html>
- <html lang="zh-CN">
- <head>
- <meta charset="UTF-8">
- <title>文字识别</title>
- </head>
- <body>
- <canvas id="canvas" width="880" height="1500"></canvas>
- <script type="text/javascript">
- var image = new Image();
- image.onload = recognition;
- image.src = 'image.jpg';
- function recognition(){
- // 开始时间,用于计算耗时
- var beginTime = new Date().getTime();
- // 获取画布
- var canvas = document.getElementById('canvas');
- // 字符库
- var letters = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ+';
- // 字型数据
- var letterData = {};
- // 获取context
- var context = canvas.getContext('2d');
- // 设置字体、字号
- context.font = '16px 微软雅黑';
- // 设置文字绘制基线为文字顶端
- context.textBaseline = 'top';
- // 一个循环获取字符库对应的字型数据
- for(var i = 0; i < letters.length; ++i){
- var letter = letters[i];
- // 获取字符绘制宽度
- var width = context.measureText(letter).width;
- // 绘制白色背景,与图片背景对应
- context.fillStyle = '#fff';
- context.fillRect(0, 0, width, 22);
- // 绘制文字,以获取字型数据
- context.fillStyle = '#000';
- context.fillText(letter, 0, 0);
- // 缓存字型灰度化0-1数据
- letterData[letter] = {
- width : width,
- data : getBinary(context.getImageData(0, 0, width, 22).data)
- }
- // 清空该区域以获取下个字符字型数据
- context.clearRect(0, 0, width, 22);
- }
- // console.log(letterData);
- // 绘制图片
- context.drawImage(this, 0, 0);
- // 要识别的文字开始坐标
- var x = beginX = 8;
- var y = beginY = 161;
- // 行高
- var lineHeight = 24;
- // 结果文本
- var result = '';
- // 非递归开始
- var count = 0;
- while(y <= 569 && ++count < 1000){
- // 当前最匹配的字符
- var trueLetter = {letter: null, width : null, deviation: 100};
- // 循环匹配字符
- for(var letter in letterData){
- // 获取当前字符宽度
- var width = letterData[letter].width;
- // 获取该矩形区域下的灰度化0-1数据
- var data = getBinary(context.getImageData(x, y, width, 22).data);
- // 当前字符灰度化数据与当前矩形区域下灰度化数据的偏差量
- var deviation = 0;
- // 一个临时变量以确定是否到了行末
- var isEmpty = true;
- // 如果当前矩形区域已经超出图片宽度,则进行下一个字符匹配
- if(x + width > this.width){
- continue;
- }
- // 计算偏差
- for(var i = 0, l = data.length; i < l; ++i){
- // 如果发现存在的有效像素点,则确定未到行末
- if(isEmpty && data[i]){
- isEmpty = false;
- }
- // 不匹配的像素点,偏差量自增1
- if(data[i] != letterData[letter].data[i]){
- ++deviation;
- }
- }
- // 非递归无法遍历所有情况,因此针对某些字符进行一些微调(这里只针对猎豹,Chrome的没做)
- // 因为其实非递归实现只是在递归实现前做的一点小尝试,因为不舍得删,就顺便贴出来了
- if(letter == 'M'){
- deviation -= 6;
- }
- // 如果偏差量与宽度的比值小于3,则视为匹配成功
- if(deviation / width < 3){
- // 将偏差量与宽度比值最小的作为当前最匹配的字符
- if(deviation / width < trueLetter.deviation / trueLetter.width){
- trueLetter.letter = letter;
- trueLetter.width = width;
- trueLetter.deviation = deviation;
- }
- }
- }
- // 如果已经到了行末,重置匹配坐标,进行下一轮匹配
- if(isEmpty){
- x = beginX;
- y += lineHeight;
- result += '\n';
- continue;
- }
- // 如果匹配到的字符不为空,则加入结果字符串,否则输出匹配结果
- if(trueLetter.letter){
- result += trueLetter.letter;
- // console.log(x, y, trueLetter.letter);
- }else{
- console.log(x, y, result.length);
- break;
- }
- // 调整坐标至下一个字符匹配位置
- x += trueLetter.width;
- }
- // 非递归结束
- // 图像数据的灰度化及0-1化
- function getBinary(data){
- var binaryData = [];
- for(var i = 0, l = data.length; i < l; i += 4){
- // 尝试过三种方式
- // 一种是正常的灰度化公式,无论系数如何调整都无法与绘制的文字字型数据很好地匹配
- // binaryData[i / 4] = (data[i] * 0.3 + data[i + 1] * 0.59 + data[i + 2] * 0.11) < 90;
- // 一种是自己是通过自己手动调整系数,结果虽然接近但总是不尽人意
- // binaryData[i / 4] = data[i] < 250 && data[i + 1] < 203 && data[i + 2] < 203;
- // 最后使用了平均值,结果比较理想
- binaryData[i / 4] = (data[i] + data[i + 1] + data[i + 2]) / 3 < 200;
- }
- return binaryData;
- }
- console.log(result);
- // 输出耗时
- console.log(count, (new Date().getTime() - beginTime) / 1000 + ' s');
- // 将文字绘制到图片对应位置上,以方便查看提取是否正确
- context.drawImage(this, this.width, 0);
- var textArray = result.split('\n');
- for(var i = 0; i < textArray.length; ++i){
- context.fillText(textArray[i], this.width + beginX, beginY + lineHeight * i);
- }
- }
- </script>
- </body>
- </html>
- yv66vgAAADIAHQoABgAPCQAQABEIABIKABMAFAcAF
- QcAFgEABjxpbml0PgEAAygpVgEABENvZGUB
- AA9MaW5lTnVtYmVyVGFibGUBAARtYWluAQAWKFtMa
- mF2YS9sYW5nL1N0cmluZzspVgEAClNvdXJj
- ZUZpbGUBAAlNYWluLmphdmEMAAcACAcAFwwAGAA
- ZAQBv5paw5rWq6Laz55CD6Zif5a6e5Yqb6LaF
- 576k77yM6Zi15a656LGq5Y2O44CC5LmF5Luw5aSn5ZC
- N77yM5ZGo5pel5LiA5oiY77yM6L+Y5pyb
- 5LiN6YGX5L2Z5Yqb77yM5LiN5ZCd6LWQ5pWZ44CCBw
- AaDAAbABwBAARNYWluAQAQamF2YS9sYW5n
- L09iamVjdAEAEGphdmEvbGFuZy9TeXN0ZW0BAANvdX
- QBABVMamF2YS9pby9QcmludFN0cmVhbTsB
- ABNqYXZhL2lvL1ByaW50U3RyZWFtAQAHcHJpbnRsbgE
- AFShMamF2YS9sYW5nL1N0cmluZzspVgAh
- AAUABgAAAAAAAgABAAcACAABAAkAAAAdAAEAAQA
- AAAUqtwABsQAAAAEACgAAAAYAAQAAAAEACQAL
- AAwAAQAJAAAAJQACAAEAAAAJsgACEgO2AASxAAAA
- AQAKAAAACgACAAAAAwAIAAQAAQANAAAAAgAO
- 702 1.931 s(猎豹)
找了个在线的Base64解码工具将上面的提取结果进行了一下解码,发现是一个Java编译后的.class文件,大概内容是:“新浪足球队实力超群,阵容豪华。久仰大名,周日一战,还望不遗余力,不吝赐教。”
这个只是一个最浅层次的文字识别提取算法,不够通用,性能也一般,权当兴趣研究之用,不过我想,勇于实践、敢于尝试的精神才是最重要的。。
因为最近实习工作略忙,再加上学校开学事情也多,拖了两个星期才把这边文章写出来,除此之外还有不少计划都落下了,还得继续努力啊>_<
还有最近的一些思考的结果和感触也要找个时间写下来。
PS:写这篇博客的时候精神略差,之后有想到什么再作补充吧,如果写的不好还请多多指教!
=======================签 名 档=======================
原文地址(我的博客):http://www.clanfei.com/2013/09/1723.html
欢迎访问交流,至于我为什么要多弄一个博客,因为我热爱前端,热爱网页,我更希望有一个更加自由、真正属于我自己的小站,或许并不是那么有名气,但至少能够让我为了它而加倍努力。。
=======================签 名 档=======================
