使用 jsoup 对 HTML 文档进行解析和操作
jsoup 简介
Java 程序在解析 HTML 文档时,相信大家都接触过 htmlparser 这个开源项目,我曾经在 IBM DW 上发表过两篇关于 htmlparser 的文章,分别是:从HTML中攫取你所需的信息 和扩展 HTMLParser 对自定义标签的处理能力。但现在我已经不再使用 htmlparser 了,原因是 htmlparser 很少更新,但最重要的是有了 jsoup 。
jsoup 是一款 Java 的HTML 解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
jsoup的主要功能如下:
1. 从一个URL,文件或字符串中解析HTML;
2. 使用DOM或CSS选择器来查找、取出数据;
3. 可操作HTML元素、属性、文本;
jsoup是基于MIT协议发布的,可放心使用于商业项目。
jsoup 的主要类层次结构如下图所示:
接下来我们专门针对几种常见的应用场景举例说明 jsoup 是如何优雅的进行 HTML 文档处理的。
文档输入
jsoup 可以从包括字符串、URL地址以及本地文件来加载 HTML 文档,并生成 Document 对象实例。
下面是相关代码:
如果这五个过滤器都无法满足你的要求呢,例如你允许用户插入 flash 动画,没关系,Whitelist 提供扩展功能,例如 whitelist.addTags("embed","object","param","span","div"); 也可调用 addAttributes 为某些元素增加属性。
jsoup 的过人之处――选择器
前面我们已经简单的介绍了 jsoup 是如何使用选择器来对元素进行检索的。本节我们把重点放在选择器本身强大的语法上。下表是 jsoup 选择器的所有语法详细列表。
基本用法以上是最基本的选择器语法,这些语法也可以组合起来使用,下面是 jsoup 支持的组合用法:
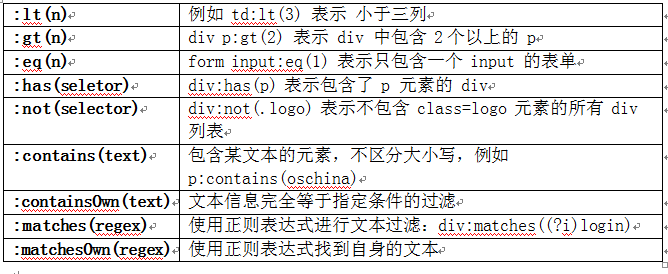
除了一些基本的语法以及这些语法进行组合外,jsoup 还支持使用表达式进行元素过滤选择。下面是 jsoup 支持的所有表达式一览表:
总结
jsoup 的基本功能到这里就介绍完毕,但由于 jsoup 良好的可扩展性 API 设计,你可以通过选择器的定义来开发出非常强大的 HTML 解析功能。再加上 jsoup 项目本身的开发也非常活跃,因此如果你正在使用 Java ,需要对 HTML 进行处理,不妨试试。