hadoop在文件分片blocksize
[root@cluster-19 workspace]# du -sk272032 .[root@cluster-19 workspace]# vi 1[root@cluster-19 workspace]# du -sk272036 .[root@cluster-19 workspace]# ls -la 1-rw-r--r--. 1 root root 2 8月 27 14:56 1
?以上代码可以看到,我们 使用du命令 ?时 ? ?看到 1 这个文件占用了一个 块 ?的空间,由于一个块的空间是 4096 (4K) 所有我们创建1这个文件之后 ?我们看到磁盘空间 增加了 4K ?, 但是我们在使用ls 查看 1 这个文件的时候,我么看到 这里 文件的大小是 2 个字节。
其实我们使用ls 看到的只是文件的meta信息。
?
那么在hdfs中呢,前边已经说过块的大小是64M ,
我们做个假设 ?如果 ?1T 的盘 ,我们上传 小文件到 hdfs ? ,那么我们是不是只能上传1632个小文件,这个和我们预期远远不相符,hadoop确实是处理大文件有优势,但是也有处理小文件的能力,那就是在shuffle阶段会有合并的,且map的个数和块的数量有关系,如果块很小,那其不是有很多块 也就是很多map了
所以 hdfs中的块,会被充分利用,如果一个文件的大小小于这个块的话那么这个文件 不会占据整个块空间:
?
hdfs 的块 如此之大 主要还是为 减小寻址开销的 :
?
一用hadoop权威指南一句话:
HDFS的块比磁盘块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间可以明显大于定位这个块开始位置所需的时间。这样,传输一个由多个块组成的文件的时间取决于磁盘传输速率。我们来做一个速算,如果寻址时间为10ms左右,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们需要设置块大小为100MB左右。而默认的块大小实际为64MB,但是很多情况下HDFS使用128MB的块设置。以后随着新一代磁盘驱动器传输速率的提升,块的大小将被设置得更大。但是该参数也不会设置得过大。MapReduce中的map任务通常一次处理一个块中的数据,因此如果任务数太少(少于集群中的节点数量),作业的运行速度就会比较慢。
?
我们都知道 ,hdfs 的文件是不允许修改的,目前的hadoop2.0 持支 对一个文件做append操作,那么就遇到另一个问题,
假如现在有一个两个文件 ?放在同一个block中的话:
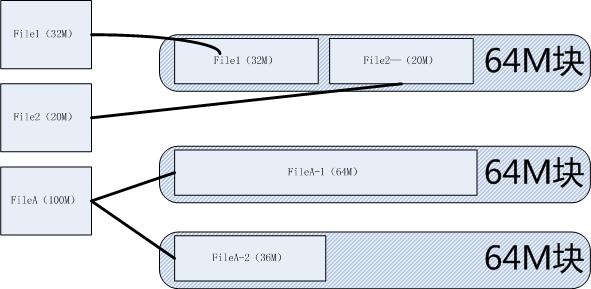
?
?
如上图,如果原始文件是这样字存在的话 ,那么我如果对File1 做 append操作的花,那么hdfs会怎么处理呢?
我们知道在文件的namenode信息中记录了文件的信息,我们对hadoop做了appdend之后,一个文件只会记录一个文件信息,不可能一个文件记录在多个文件块中,那么 hdfs是会将File1 原来的文件取出来,和我们将要appdend的内容放在一起重新存储文件呢?还是在文件的meta信息中维护了这个文件的两个地址呢?
?
待查询?
?
希望高手指教...........................