SQL统计查询
现在有三张表,希望按照年龄段统计出疾病检出人数
RYDJB存放人员基本信息(姓名、年龄、性别、档案号[主键]) 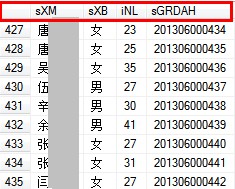
JGB存放结果的表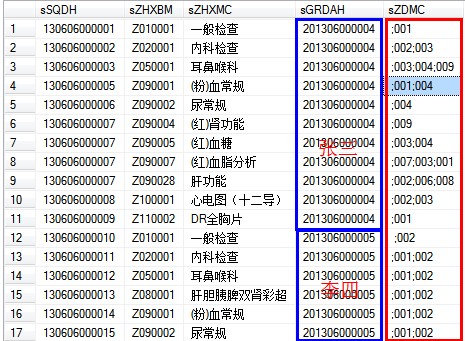
CJZDB存放诊断数据表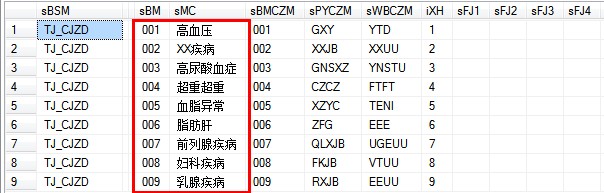
期待的统计结果:
遇到问题:一个sGRDAH即一个人的唯一ID,一个人的疾病 不重复统计。
如上图中的张三 统计疾病时有:001;002;003;004;006;007;008;009重复不计
之后还要按照人员性别、以及所在年龄段进行统计,恳请各位大神们,多多指点。 SQL 统计 疾病统计 体检 数据
[解决办法]
--各疾病的检出总人数可以这样来统计
select t1.sMC as 疾病名称,count(distinct sGRDAH) as 检出总人数
from jgb t1,CJZDB t2,RYDJB t3
where CHARINDEX(t2.sBM,t1.sZDMC)>0 and t3.sGRDAH=t1.sGRDAH
group by t1.sBM,t1.sMC
--年龄分布的就好办了
--<45岁的
select t1.sMC as 疾病名称,count(distinct sGRDAH) as 检出总人数
from jgb t1,CJZDB t2,RYDJB t3
where CHARINDEX(t2.sBM,t1.sZDMC)>0 and t3.sGRDAH=t1.sGRDAH
and t3.iNL<=45
group by t1.sBM,t1.sMC
--剩下的依次类推
CREATE TABLE #RYDJB(ID INT IDENTITY,姓名 NVARCHAR(10), 性别 NCHAR(1), 年龄 INT, sGRDAH VARCHAR(20))
INSERT #RYDJB (姓名, 性别, 年龄, sGRDAH )
SELECT '张三', '女', 23, '20130600434' UNION ALL
SELECT '李四', '男', 23, '20130600435' UNION ALL
SELECT '王五', '男', 23, '20130600436'
CREATE TABLE #JGB(sGRDAH VARCHAR(20), sZDMC VARCHAR(100))
INSERT #JGB ( sGRDAH, sZDMC )
SELECT '20130600434', ';001;002' UNION ALL
SELECT '20130600435', ';002;003' UNION ALL
SELECT '20130600435', ';003;004'
CREATE TABLE #CJZDB(sBM VARCHAR(10), sMC NVARCHAR(100))
INSERT #CJZDB ( sBM, sMC )
SELECT '001', '高血压' UNION ALL
SELECT '002', 'xx疾病' UNION ALL
SELECT '003', '高尿酸血症' UNION ALL
SELECT '004', '超重超重'
--楼主自行在实际数据中执行一下,如有出入,改下字段名
SELECT 性别,sMC,总人数,[<45],[45-60],[>60],
[<45%]=LTRIM(CONVERT(DECIMAL(10,1), 100.0*[<45]/总人数))+'%',
[45-60%]=LTRIM(CONVERT(DECIMAL(10,1), 100.0*[45-60]/总人数))+'%',
[>60%]=LTRIM(CONVERT(DECIMAL(10,1), 100.0*[>60]/总人数))+'%'
FROM
(
SELECT
性别,sMC,
总人数=COUNT(1),
[<45]=SUM(CASE WHEN 年龄<45 THEN 1 ELSE 0 END),
[45-60]=SUM(CASE WHEN 年龄 BETWEEN 45 AND 60 THEN 1 ELSE 0 END),
[>60]=SUM(CASE WHEN 年龄>60 THEN 1 ELSE 0 END)
FROM
(
SELECT DISTINCT a.id,a.姓名,a.性别,a.年龄,a.sGRDAH,b.sZDMC,c.sMC
FROM
(
SELECT a.*, sZDMC = CONVERT(XML, '<root><v>'+replace(STUFF(sZDMC,1,1,''),';','</v><v>')+'</v></root>')
FROM #RYDJB a
INNER JOIN #JGB B
ON a.sGRDAH = b.sGRDAH
) a
CROSS APPLY
(
SELECT sZDMC = C.v.value('.','NVARCHAR(10)') FROM a.sZDMC.nodes('/root/v') C(v)
) b
INNER JOIN #CJZDB c
ON B.sZDMC = c.sBM
) t
GROUP BY 性别,sMC
) b
ORDER BY 性别, sMC
/*
性别sMC总人数<4545-60>60<45%45-60%>60%
男xx疾病1100100.0%0.0%0.0%
男超重超重1100100.0%0.0%0.0%
男高尿酸血症1100100.0%0.0%0.0%
女xx疾病1100100.0%0.0%0.0%
女高血压1100100.0%0.0%0.0%
*/