Memcached 原理(1)
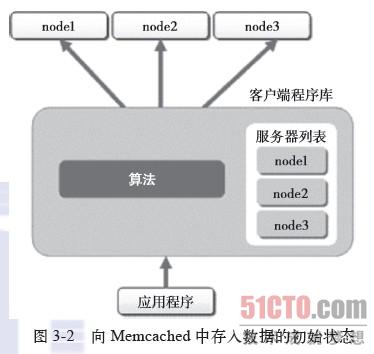 ?
?
?
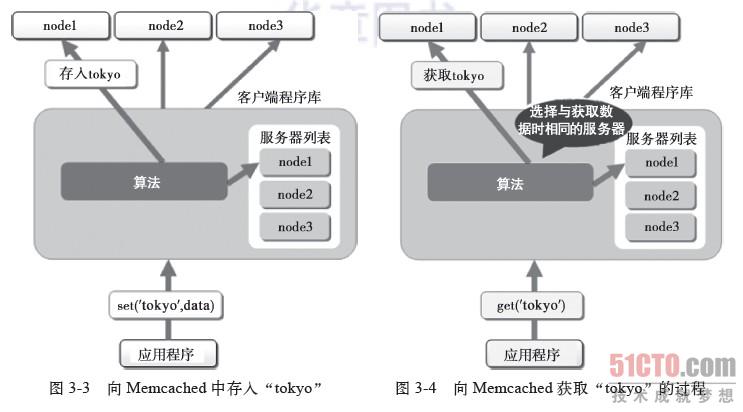
向Memcached中存入“tokyo”,将“tokyo”传给客户端程序后,客户端实现的算法就会根据这个“键”来决定保存数据的Memcached服务器,选定服务器后,就命令该服务器保存“tokyo”及其值,如图3-3所示。
同样,存入“tokyo1”、“ tokyo2”和“ tokyo3”的过程都是先通过客户端的算法选择服务器再保存数据。
接下来获取保存的数据。获取保存的key/value对时也要将要获取的键“tokyo”传递给函数库。函数库通过与存取数据操作相同的算法,根据“键”来选择服务器。只要使用的算法相同,就能确定存入在哪一台服务器上,然后发送get命令。只要数据没有因为某些原因被删除,就能获得保存的值,如图3-4所示。
?
 ?
??
将不同的键保存到不同的服务器上,就实现了Memcached的分布式算法。部署多台Memcached服务器时,将键分散保存到这些服务器上,当某一台Memcached服务器发生故障无法连接时,只有分散到这台服务器上的key/values对不能访问,其他key/value对不受影响。
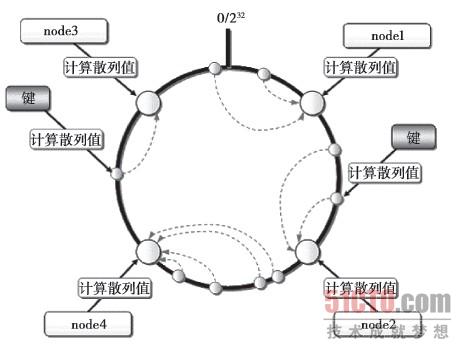
目前有两种分布式算法使用得最多,一种是根据余数来计算分布,另一种是根据一致性散列算法来计算分布。根据余数分布式算法先求得键的整数散列值,再除以服务器台数,根据余数来选择将键存放到哪一台服务器上。这种方法虽然计算简单,效率很高,但在服务器增加或减少时,会导致几乎所有的缓存失效,所以在大规模部署中,很少使用这种方法。一致性散列的原理如图3-5所示,先算出Memcached服务器(节点)的散列值,并将其分散到0到2的32次方的圆上,然后用同样的方法算出存储数据的键的散列值并映射到圆上,最后从数据映射到的位置开始顺时针查找,将数据保存到查找到的第一个服务器上。如果超过232仍然找不到服务器,就会将数据保存到第一台Memcached服务器上。
 ?
?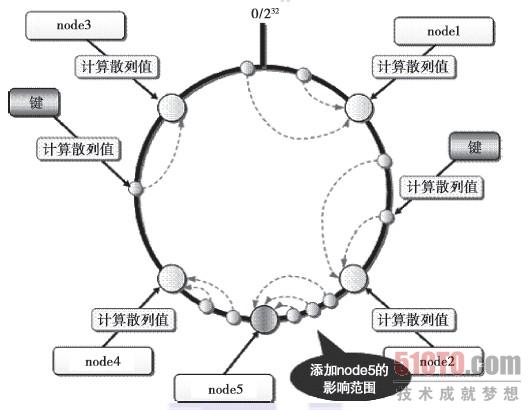 ?(点击查看大图)图3-6 在使用一致性散列算法时增加一台新服务器
?(点击查看大图)图3-6 在使用一致性散列算法时增加一台新服务器