hadoop1.0 和hadoop2.0 任务处理架构比较
?
?Hadoop 1.0
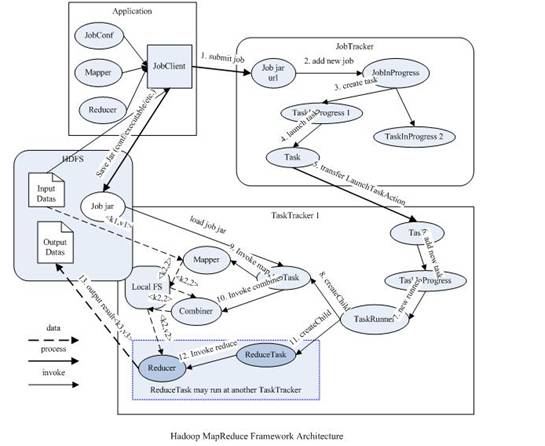
?
?
从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路:
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
?
?hadoop2.0:
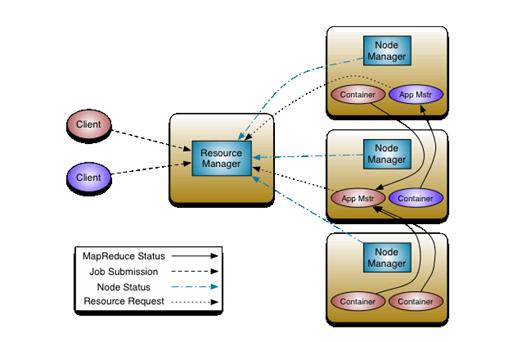
?从业界使用分布式系统的变化趋势和 hadoop 框架的长远发展来看,MapReduce 的 JobTracker/TaskTracker 机制需要大规模的调整来修复它在可扩展性,内存消耗,线程模型,可靠性和性能上的缺陷。在过去的几年中,hadoop 开发团队做了一些 bug 的修复,但是最近这些修复的成本越来越高,这表明对原框架做出改变的难度越来越大。
为从根本上解决旧 MapReduce 框架的性能瓶颈,促进 Hadoop 框架的更长远发展,从 0.23.0 版本开始,Hadoop 的 MapReduce 框架完全重构,发生了根本的变化。新的 Hadoop MapReduce 框架命名为 MapReduceV2 或者叫 Yarn,
?
重构根本的思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。新的资源管理器全局管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的 MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager 和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。
事实上,每一个应用的 ApplicationMaster 是一个详细的框架库,它结合从 ResourceManager 获得的资源和 NodeManager 协同工作来运行和监控任务。
上图中 ResourceManager 支持分层级的应用队列,这些队列享有集群一定比例的资源。从某种意义上讲它就是一个纯粹的调度器,它在执行过程中不对应用进行监控和状态跟踪。同样,它也不能重启因应用失败或者硬件错误而运行失败的任务。
ResourceManager 是基于应用程序对资源的需求进行调度的 ; 每一个应用程序需要不同类型的资源因此就需要不同的容器。资源包括:内存,CPU,磁盘,网络等等。可以看出,这同现 Mapreduce 固定类型的资源使用模型有显著区别,它给集群的使用带来负面的影响。资源管理器提供一个调度策略的插件,它负责将集群资源分配给多个队列和应用程序。调度插件可以基于现有的能力调度和公平调度模型。
上图中 NodeManager 是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
每一个应用的 ApplicationMaster 的职责有:向调度器索要适当的资源容器,运行任务,跟踪应用程序的状态和监控它们的进程,处理任务的失败原因。
?
详细配置参考:
http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?