Oracle SQL 语句的处理过程详解
SQL语句:
1 数据查询语言DQL:select查询语句
2 数据操纵语言DML:DML语句(insert, update, delete)
3 数据定义语言DDL:DDL 语句(create .. , drop .. , alter .. , )
4 数据控制语言DCL:事务控制(commit, rollback)
SQL语句执行过程: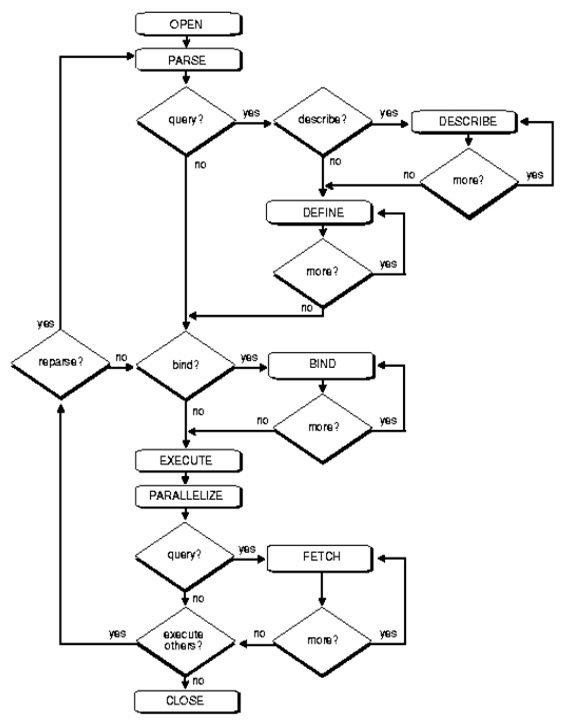
第1步: 创建游标(Create a Cursor)
由程序接口调用创建一个游标(cursor)。任何SQL语句都会创建它,特别在运行DML语句时,都是自动创建游标的,不需要开发人员干预。多数应用中,游标的创建是自动的。然而,游标的创建,可能是隐含的,也可能显式的创建。在存储过程中也是这样的。
第2步:分析语句(Parse the Statement)
在语法分析期间,SQL语句从用户进程传送到Oracle,SQL语句经语法分析后,SQL语句本身与分析的信息都被装入到共享SQL区。在该阶段中,可以解决许多类型的错误。
语法分析分别执行下列操作:
-翻译SQL语句,验证它是合法的语句,即书写正确
-实现数据字典的查找,以验证是否符合表和列的定义
-在所要求的对象上获取语法分析锁,使得在语句的语法分析过程中不改变这些对象的定义
-验证为存取所涉及的模式对象所需的权限是否满足
-决定此语句最佳的执行计划
-将它装入共享SQL区
-对分布的语句来说,把语句的全部或部分路由到包含所涉及数据的远程节点
* 以上任何一步出错误,都将导致语句报错,中止执行。
只有在共享池中不存在等价SQL语句的情况下,才对SQL语句作语法分析。在这种情况下,数据库内核重新为该语句分配新的共享SQL区,并对语句进行语法分析。进行语法分析需要耗费较多的资源,所以要尽量避免进行语法分析,这是优化的技巧之一。
语法分析阶段包含了不管此语句将执行多少次,而只需分析一次的处理要求。Oracle只对每个SQL语句翻译一次,在以后再次执行该语句时,只要该语句还在共享SQL区中,就可以避免对该语句重新进行语法分析,也就是此时可以直接使用其对应的执行计划对数据进行存取。这主要是通过绑定变量(bind variable)实现的,也就是我们常说的共享SQL。
虽然语法分析验证了SQL语句的正确性,但语法分析只能识别在SQL语句执行之前所能发现的错误(如书写错误、权限不足等)。因此,有些错误通过语法分析是抓不到的。例如,在数据转换中的错误或在数据中的错(如企图在主键中插入重复的值)以及死锁等均是只有在语句执行阶段期间才能遇到和报告的错误或情况。
第3步: 描述查询结果(Describe Results of a Query)
描述阶段只有在查询结果的各个列是未知时才需要;例如,当查询由用户交互地输入需要输出的列名。在这种情况要用描述阶段来决定查询结果的特征(数据类型,长度和名字)。
第4步: 定义查询的输出数据(Define Output of a Query)
在查询的定义阶段,你指定与查询出的列值对应的接收变量的位置、大小和数据类型,这样我们通过接收变量就可以得到查询结果。如果必要的话,Oracle会自动实现数据类型的转换。这是将接收变量的类型与对应的列类型相比较决定的。
第5步: 绑定变量(Bind Any Variables)
Oracle知道了SQL语句的意思,但仍没有足够的信息用于执行该语句。Oracle 需要得到在语句中列出的所有变量的值,得到这个值的过程就叫绑定变量(binding variables)。
此过程称之为将变量值捆绑进来。程序必须指出可以找到该数值的变量名(该变量被称为捆绑变量,变量名实质上是一个内存地址,相当于指针)。应用的最终用户可能并没有发觉他们正在指定捆绑变量,因为Oracle 的程序可能只是简单地指示他们输入新的值,其实这一切都在程序中自动做了。
因为你指定了变量名,在你再次执行之前无须重新捆绑变量。你可以改变绑定变量的值,而Oracle在每次执行时,仅仅使用内存地址来查找此值。
如果Oracle 需要实现自动数据类型转换的话(除非它们是隐含的或缺省的),你还必须对每个值指定数据类型和长度。
第6步: 并行执行语句(Parallelize the Statement )
ORACLE 可以在SELECTs, INSERTs, UPDATEs, MERGEs, DELETEs语句中执行相应并行查询操作,对某些DDL操作,如创建索引、用子查询创建表、在分区表上的操作,可以执行并行操作。并行化可导致多个服务器进程(oracle server processes)为同一个SQL语句工作,使该SQL语句可以快速完成,但是会耗费更多的资源,所以除非很有必要,否则不要使用并行查询。
第7步: 执行语句(Run the Statement)
此时,Oracle拥有所有需要的信息与资源,可以真正运行SQL语句了。如果该语句为SELECT查询或INSERT语句,则不需要锁定任何行,因没有数据需要被改变。如果语句为UPDATE或DELETE语句,则该语句影响的所有行都被锁定,防止该用户提交或回滚之前,别的用户对这些数据进行修改。这保证了数据的一致性。
对于某些语句,你可以指定执行的次数,这称为批处理(array processing)。指定执行N次,则绑定变量与定义变量被定义为大小为N的数组的开始位置,这种方法可以减少网络开销,也是优化的技巧之一。
第8步: 取出查询的行(Fetch Rows of a Query)
在fetch阶段,行数据被取出来,每个后续的存取操作检索结果集中的下一行数据,直到最后一行被取出来。上面提到过,批量的fetch是优化的技巧之一。
第9步: 关闭游标(Close the Cursor)
SQL语句处理的最后一个阶段就是关闭游标。
DDL语句的执行不同与DML语句和查询语句的执行,这是因为DDL语句执行成功后需要对数据字典数据进行修改。对于DDL语句,语句的分析阶段包括:分析、查找数据字典信息和执行。
事务管理语句、会话管理语句、系统管理语句只有分析与执行阶段,为了重新执行该语句,会重新分析与执行该语句。