Git详解之五:分布式Git
?图 5-1. 集中式工作流
?
如果两个开发者从中心仓库克隆代码下来,同时作了一些修订,那么只有第一个开发者可以顺利地把数据推送到共享服务器。第二个开发者在提交他的修订之 前,必须先下载合并服务器上的数据,解决冲突之后才能推送数据到共享服务器上。在 Git 中这么用也决无问题,这就好比是在用 Subversion(或其他 CVCS)一样,可以很好地工作。
?
如果你的团队不是很大,或者大家都已经习惯了使用集中式工作流程,完全可以采用这种简单的模式。只需要配置好一台中心服务器,并给每个人推送数据的 权限,就可以开展工作了。但如果提交代码时有冲突, Git 根本就不会让用户覆盖他人代码,它直接驳回第二个人的提交操作。这就等于告诉提交者,你所作的修订无法通过快近(fast-forward)来合并,你必 须先拉取最新数据下来,手工解决冲突合并后,才能继续推送新的提交。绝大多数人都熟悉和了解这种模式的工作方式,所以使用也非常广泛。
?
集成管理员工作流
?
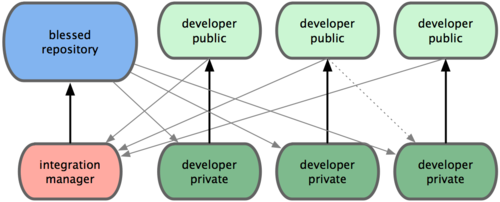
由于 Git 允许使用多个远程仓库,开发者便可以建立自己的公共仓库,往里面写数据并共享给他人,而同时又可以从别人的仓库中提取他们的更新过来。这种情形通常都会有 个代表着官方发布的项目仓库(blessed repository),开发者们由此仓库克隆出一个自己的公共仓库(developer public),然后将自己的提交推送上去,请求官方仓库的维护者拉取更新合并到主项目。维护者在自己的本地也有个克隆仓库(integration manager),他可以将你的公共仓库作为远程仓库添加进来,经过测试无误后合并到主干分支,然后再推送到官方仓库。工作流程看起来就像图 5-2 所示:
?
?
在
?图 5-3. 司令官与副官工作流
?
这种工作流程并不常用,只有当项目极为庞杂,或者需要多级别管理时,才会体现出优势。利用这种方式,项目总负责人(即司令官)可以把大量分散的集成工作委托给不同的小组负责人分别处理,最后再统筹起来,如此各人的职责清晰明确,也不易出错(译注:此乃分而治之)。
?
以上介绍的是常见的分布式系统可以应用的工作流程,当然不止于 Git。在实际的开发工作中,你可能会遇到各种为了满足特定需求而有所变化的工作方式。我想现在你应该已经清楚,接下来自己需要用哪种方式开展工作了。下 节我还会再举些例子,看看各式工作流中的每个角色具体应该如何操作。
?
?
?
5.2? 为项目作贡献
?
接下来,我们来学习一下作为项目贡献者,会有哪些常见的工作模式。
?
不过要说清楚整个协作过程真的很难,Git 如此灵活,人们的协作方式便可以各式各样,没有固定不变的范式可循,而每个项目的具体情况又多少会有些不同,比如说参与者的规模,所选择的工作流程,每个人的提交权限,以及 Git 以外贡献等等,都会影响到具体操作的细节。
?
首当其冲的是参与者规模。项目中有多少开发者是经常提交代码的?经常又是多久呢?大多数两至三人的小团队,一天大约只有几次提交,如果不是什么热门 项目的话就更少了。可要是在大公司里,或者大项目中,参与者可以多到上千,每天都会有十几个上百个补丁提交上来。这种差异带来的影响是显著的,越是多的人 参与进来,就越难保证每次合并正确无误。你正在工作的代码,可能会因为合并进来其他人的更新而变得过时,甚至受创无法运行。而已经提交上去的更新,也可能 在等着审核合并的过程中变得过时。那么,我们该怎样做才能确保代码是最新的,提交的补丁也是可用的呢?
?
接下来便是项目所采用的工作流。是集中式的,每个开发者都具有等同的写权限?项目是否有专人负责检查所有补丁?是不是所有补丁都做过同行复阅(peer-review)再通过审核的?你是否参与审核过程?如果使用副官系统,那你是不是限定于只能向此副官提交?
?
还有你的提交权限。有或没有向主项目提交更新的权限,结果完全不同,直接决定最终采用怎样的工作流。如果不能直接提交更新,那该如何贡献自己的代码呢?是不是该有个什么策略?你每次贡献代码会有多少量?提交频率呢?
?
所有以上这些问题都会或多或少影响到最终采用的工作流。接下来,我会在一系列由简入繁的具体用例中,逐一阐述。此后在实践时,应该可以借鉴这里的例子,略作调整,以满足实际需要构建自己的工作流。
?
?
?
提交指南
?
开始分析特定用例之前,先来了解下如何撰写提交说明。一份好的提交指南可以帮助协作者更轻松更有效地配合。Git 项目本身就提供了一份文档(Git 项目源代码目录中Documentation/SubmittingPatches),列数了大量提示,从如何编撰提交说明到提交补丁,不一而足。
?
首先,请不要在更新中提交多余的白字符(whitespace)。Git 有种检查此类问题的方法,在提交之前,先运行?git diff --check,会把可能的多余白字符修正列出来。下面的示例,我已经把终端中显示为红色的白字符用X?替换掉:
?图 5-4. John 的仓库历史?
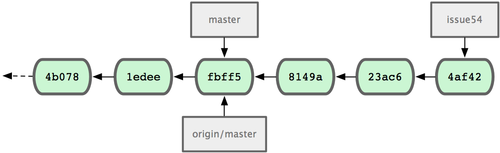
虽然 John 下载了 Jessica 推送到服务器的最近更新(fbff5),但目前只是?
origin/master?指针指向它,而当前的本地分支master?仍然指向自己的更新(738ee),所以需要先把她的提交合并过来,才能继续推送数据:
?图 5-5. 合并 origin/master 后 John 的仓库历史?
现在,John 应该再测试一下代码是否仍然正常工作,然后将合并结果(72bbc)推送到服务器上:
?图 5-6. 推送后 John 的仓库历史?
而在这段时间,Jessica 已经开始在另一个特性分支工作了。她创建了?
issue54?并提交了三次更新。她还没有下载 John 提交的合并结果,所以提交历史如图 5-7 所示:
?图 5-7. Jessica 的提交历史?
Jessica 想要先和服务器上的数据同步,所以先下载数据:
?图 5-8. 获取 John 的更新之后 Jessica 的提交历史?
此时,Jessica 在特性分支上的工作已经完成,但她想在推送数据之前,先确认下要并进来的数据究竟是什么,于是运行
git log?查看:
?图 5-9. 合并 John 的更新后 Jessica 的提交历史?
现在 Jessica 已经可以在自己的?
master?分支中访问?origin/master?的最新改动了,所以她应该可以成功推送最后的合并结果到服务器上(假设 John 此时没再推送新数据上来):
?图 5-10. Jessica 推送数据后的提交历史?
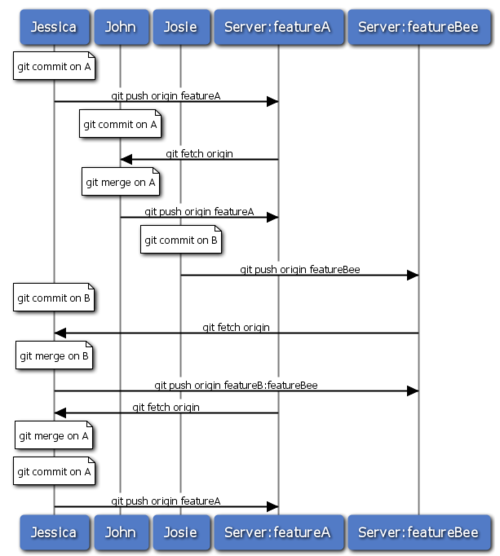
以上就是最简单的协作方式之一:先在自己的特性分支中工作一段时间,完成后合并到自己的?
master?分支;然后下载合并?origin/master?上的更新(如果有的话),再推回远程服务器。一般的协作流程如图 5-11 所示:
?图 5-11. 多用户共享仓库协作方式的一般工作流程时序?
?
?
私有团队间协作
?
现在我们来看更大一点规模的私有团队协作。如果有几个小组分头负责若干特性的开发和集成,那他们之间的协作过程是怎样的。
?
假设 John 和 Jessica 一起负责开发某项特性 A,而同时 Jessica 和 Josie 一起负责开发另一项功能 B。公司使用典型的集成管理员式工作流,每个组都有一名管理员负责集成本组代码,及更新项目主仓库的
master?分支。所有开发都在代表小组的分支上进行。?
让我们跟随 Jessica 的视角看看她的工作流程。她参与开发两项特性,同时和不同小组的开发者一起协作。克隆生成本地仓库后,她打算先着手开发特性 A。于是创建了新的
featureA?分支,继而编写代码:
?图 5-12. Jessica 的更新历史?
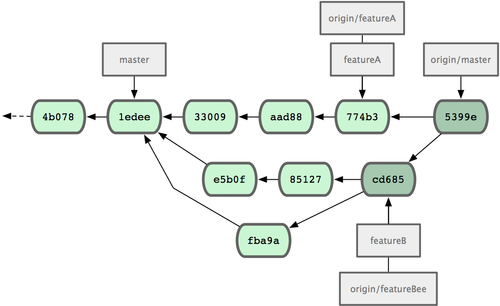
Jessica 正准备推送自己的进展上去,却收到 Josie 的来信,说是她已经将自己的工作推到服务器上的?
featureBee?分支了。这样,Jessica 就必须先将 Josie 的代码合并到自己本地分支中,才能再一起推送回服务器。她用git fetch?下载 Josie 的最新代码:
?图 5-13. 在特性分支中提交更新后的提交历史?
现在,Jessica,Josie 和 John 通知集成管理员服务器上的?
featureA?及?featureBee?分支已经准备好,可以并入主线了。在管理员完成集成工作后,主分支上便多出一个新的合并提交(5399e),用 fetch 命令更新到本地后,提交历史如图 5-14 所示:
? 图 5-14. 合并特性分支后的 Jessica 提交历史?
许多开发小组改用 Git 就是因为它允许多个小组间并行工作,而在稍后恰当时机再行合并。通过共享远程分支的方式,无需干扰整体项目代码便可以开展工作,因此使用 Git 的小型团队间协作可以变得非常灵活自由。以上工作流程的时序如图 5-15 所示:
?图 5-15. 团队间协作工作流程基本时序?
?
?
公开的小型项目
?
上面说的是私有项目协作,但要给公开项目作贡献,情况就有些不同了。因为你没有直接更新主仓库分支的权限,得寻求其它方式把工作成果交给项目维护 人。下面会介绍两种方法,第一种使用 git 托管服务商提供的仓库复制功能,一般称作 fork,比如 repo.or.cz 和 GitHub 都支持这样的操作,而且许多项目管理员都希望大家使用这样的方式。另一种方法是通过电子邮件寄送文件补丁。
?
但不管哪种方式,起先我们总需要克隆原始仓库,而后创建特性分支开展工作。基本工作流程如下:
?图 5-16. featureB 以后的提交历史?
假设项目管理员接纳了许多别人提交的补丁后,准备要采纳你提交的第一个分支,却发现因为代码基准不一致,合并工作无法正确干净地完成。这就需要你再次衍合到最新的?
origin/master,解决相关冲突,然后重新提交你的修改:?
?图 5-17. featureA 重新衍合后的提交历史?
注意,此时推送分支必须使用?
-f?选项(译注:表示 force,不作检查强制重写)替换远程已有的?featureA?分支,因为新的 commit 并非原来的后续更新。当然你也可以直接推送到另一个新的分支上去,比如称作featureAv2。?
再考虑另一种情形:管理员看过第二个分支后觉得思路新颖,但想请你改下具体实现。我们只需以当前?
origin/master?分支为基准,开始一个新的特性分支featureBv2,然后把原来的?featureB?的更新拿过来,解决冲突,按要求重新实现部分代码,然后将此特性分支推送上去:
?图 5-18. featureBv2 之后的提交历史?
?
?
公开的大型项目
?
许多大型项目都会立有一套自己的接受补丁流程,你应该注意下其中细节。但多数项目都允许通过开发者邮件列表接受补丁,现在我们来看具体例子。
?
整个工作流程类似上面的情形:为每个补丁创建独立的特性分支,而不同之处在于如何提交这些补丁。不需要创建自己可写的公共仓库,也不用将自己的更新推送到自己的服务器,你只需将每次提交的差异内容以电子邮件的方式依次发送到邮件列表中即可。
?图 5-19. 多个特性分支
?图 5-20. 合并特性分支之后?
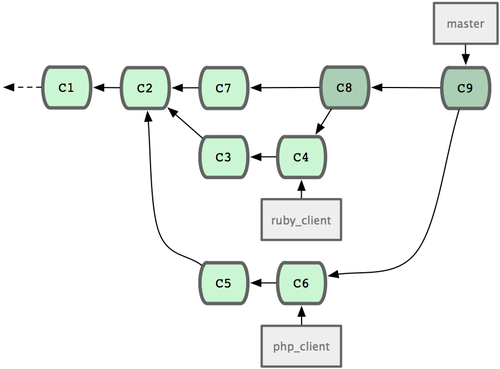
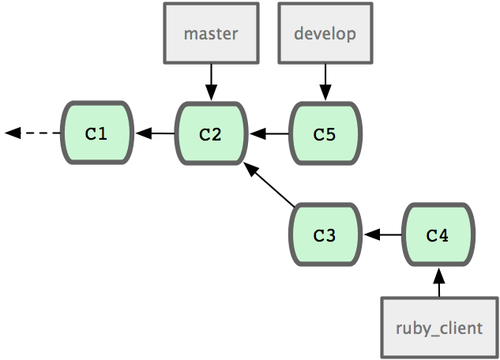
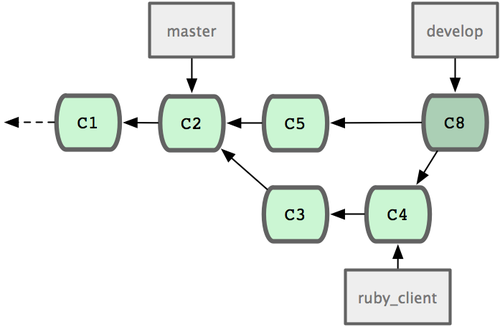
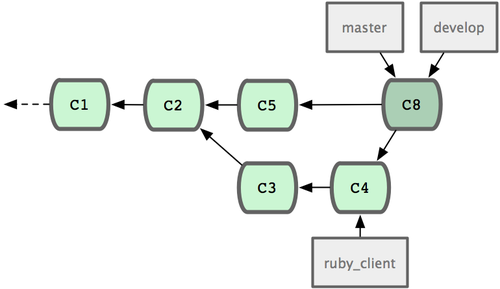
这是最简单的流程,所以在处理大一些的项目时可能会有问题。 对于大型项目,至少需要维护两个长期分支?
master?和?develop。新代码(图 5-21 中的?ruby_client)将首先并入develop?分支(图 5-22 中的?C8),经过一个阶段,确认develop?中的代码已稳定到可发行时,再将?master?分支快进到稳定点(图 5-23 中的?C8)。而平时这两个分支都会被推送到公开的代码库。
?图 5-21. 特性分支合并前
?图 5-22. 特性分支合并后
?图 5-23. 特性分支发布后?
这样,在人们克隆仓库时就有两种选择:既可检出最新稳定版本,确保正常使用;也能检出开发版本,试用最前沿的新特性。你也可以扩展这个概念,先将所有新代码合并到临时特性分支,等到该分支稳定下来并通过测试后,再并入
develop分支。然后,让时间检验一切,如果这些代码确实可以正常工作相当长一段时间,那就有理由相信它已经足够稳定,可以放心并入主干分支发布。?
?
?
大项目的合并流程
?
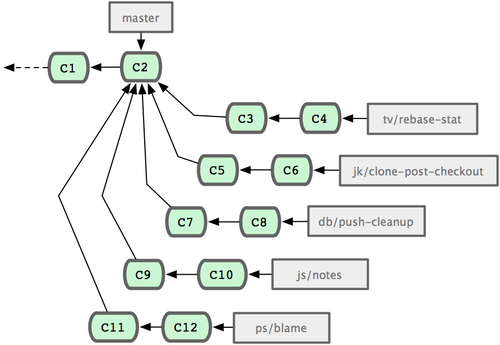
Git 项目本身有四个长期分支:用于发布的?
master?分支、用于合并基本稳定特性的?next?分支、用于合并仍需改进特性的pu?分支(pu 是 proposed updates 的缩写),以及用于除错维护的?maint?分支(maint 取自 maintenance)。维护者可以按照之前介绍的方法,将贡献者的代码引入为不同的特性分支(如图 5-24 所示),然后测试评估,看哪些特性能稳定工作,哪些还需改进。稳定的特性可以并入next?分支,然后再推送到公共仓库,以供其他人试用。
?图 5-24. 管理复杂的并行贡献?
仍需改进的特性可以先并入?
pu?分支。直到它们完全稳定后再并入?master。同时一并检查下?next?分支,将足够稳定的特性也并入?master。所以一般来说,master?始终是在快进,next?偶尔做下衍合,而pu?则是频繁衍合,如图 5-25 所示:
?图 5-25. 将特性并入长期分支?
并入?
master?后的特性分支,已经无需保留分支索引,放心删除好了。Git 项目还有一个?maint?分支,它是以最近一次发行版为基础分化而来的,用于维护除错补丁。所以克隆 Git 项目仓库后会得到这四个分支,通过检出不同分支可以了解各自进展,或是试用前沿特性,或是贡献代码。而维护者则通过管理这些分支,逐步有序地并入第三方贡献。?
?
?
衍合与挑拣(cherry-pick)的流程
?
一些维护者更喜欢衍合或者挑拣贡献者的代码,而不是简单的合并,因为这样能够保持线性的提交历史。如果你完成了一个特性的开发,并决定将它引入到主干代码中,你可以转到那个特性分支然后执行衍合命令,好在你的主干分支上(也可能是
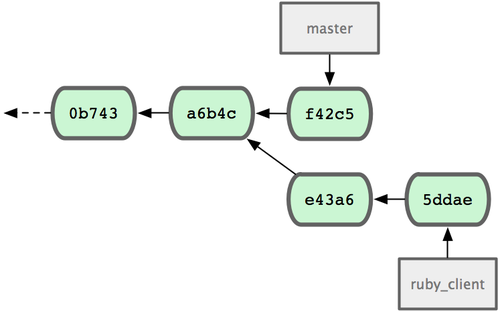
develop分支之类的)重新提交这些修改。如果这些代码工作得很好,你就可以快进master分 支,得到一个线性的提交历史。 另一个引入代码的方法是挑拣。挑拣类似于针对某次特定提交的衍合。它首先提取某次提交的补丁,然后试着应用在当前分支上。如果某个特性分支上有多个 commits,但你只想引入其中之一就可以使用这种方法。也可能仅仅是因为你喜欢用挑拣,讨厌衍合。假设你有一个类似图 5-26 的工程。
?? 图 5-26. 挑拣(cherry-pick)之前的历史 如果你希望拉取e43a6到你的主干分支,可以这样:
? 5-27. 挑拣(cherry-pick)之后的历史?
现在,你可以删除这个特性分支并丢弃你不想引入的那些commit。
?
?
?
给发行版签名
?
你可以删除上次发布的版本并重新打标签,也可以像第二章所说的那样建立一个新的标签。如果你决定以维护者的身份给发行版签名,应该这样做:
?
$ git shortlog --no-merges master --not v1.0.1Chris Wanstrath (8): Add support for annotated tags to Grit::Tag Add packed-refs annotated tag support. Add Grit::Commit#to_patch Update version and History.txt Remove stray `puts` Make ls_tree ignore nils Tom Preston-Werner (4): fix dates in history dynamic version method Version bump to 1.0.2 Regenerated gemspec for version 1.0.2?这就是自从v1.0.1版本以来的所有提交的简介,内容按照作者分组,以便你能快速的发e-mail给他们。
?
?
?
5.4? 小结
?
你学会了如何使用Git为项目做贡献,也学会了如何使用Git维护你的项目。恭喜!你已经成为一名高效的开发者。在下一篇你将学到更强大的工具来处理更加复杂的问题,之后你会变成一位Git大师。
转自:http://blog.jobbole.com/25660/