OpenVPN以及其它IP层VPN的完全链路层处理的实现
如果OpenVPN也能实现传输模式VPN该有多好,如果基于OpenVPN实现的VPN产品能仅仅作为一根昂贵的网线串接在用户网络环境,自动捕获感兴趣流量该有多好;如果它能做到只需要配置一个IP即可工作而无需配置任何路由该有多好。
我们知道OpenVPN是一个用户态的程序,靠字符设备接收从虚拟网卡进来的以太帧或者IP数据报后,作为套接字buffer从本地发送出去,对于返回的数据,写入字符设备,模拟虚拟网卡接收动作,然后再通过路由结果发送数据到下一跳,这一切的重中之重就是路由,也就是说,如果你部署了一个基于OpenVPN的VPN,那么该VPN上配置路由是在所难免的,而我们知道,路由配置基本就是一个体力活儿,不难,但是一旦弄错,后果很严重,于是避免配置路由就成了一个重要需求,能不能利用一种机制,让系统自动识别下一跳呢?在回答这个问题之前,我们必须弄明白“下一跳”这个概念的本质,它有两个层面的含义:
1.它将IP数据报继续推向目标,因为IP数据报是逐跳发送的;
2.它为链路层实际发送数据提供了一个依据。
如果我们不考虑虚拟的东西,仅仅从实际发送数据这个角度来看,对于以太网,所谓的下一跳的作用仅仅就是获得一个目标MAC地址而已,然后链路层以该MAC地址作为目标MAC,之后将数据包仍出去就完事了。
到此,一切变得简单了。我们能在original方向获得一个数据帧的源MAC,将其缓存在ip_conntrack结构中,然后对于reply的数据,用该缓存的MAC作为目标MAC封装数据帧,之后直接发送,不再经过路由层。这个设想由于Netfilter的存在使其实际实现变得简单。
先来看一个图,图示上给出了一个实际的需求: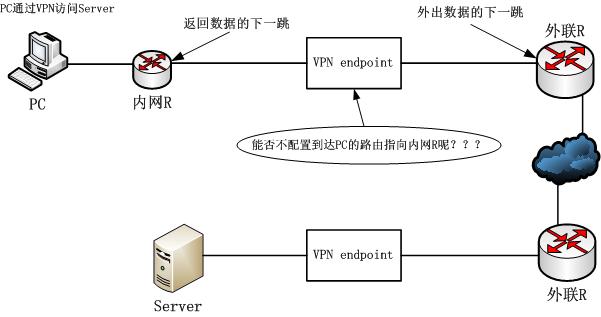
VPN endpoint已经做成了网桥,既然做成了网桥,当然是不希望在它上面配置路由了,那么就需要程序可以自动存储和识别要发送数据帧的目标MAC地址,然后直接用该MAC封装数据,以下的代码实现了这一点:
/* * This program is free software; you can redistribute it and/or modify * it under the terms of the GNU General Public License version 2 as * published by the Free Software Foundation. */#include <linux/types.h>#include <linux/netfilter.h>#include <linux/module.h>#include <linux/sysctl.h>#include <net/dst.h>#include <net/netfilter/nf_conntrack.h>#include <net/netfilter/nf_conntrack_core.h>struct gwinfo { //自动保存回复帧的目标MAC地址 unsigned char reply_gw_mac[ETH_ALEN]; //自动保存正向帧的原始目标MAC地址 unsigned char orig_gw_mac[ETH_ALEN]; unsigned int local_flag; //自动保存设备 struct net_device *dev;};static struct nf_ct_ext_type sggw_extend __read_mostly = { .len = sizeof(struct gwinfo), .align = __alignof__(struct gwinfo), .id = NF_CT_EXT_SGGW,};struct gwmark { __u32 reply_mark; __u32 orig_mark;};struct gwmark g_mark = {0x32, 0x32};static unsigned int gwmark_target(struct sk_buff *skb, const struct xt_target_param *par) { struct gwmark *gm = (struct gwmark*)par->targinfo; g_mark.reply_mark = gm->reply_mark; g_mark.orig_mark = gm->orig_mark; return NF_ACCEPT;} static bool gwmark_check(const struct xt_target_param *par){ //TODO return true;}static struct xt_target gwmark_tg __read_mostly = { .name = "GWMARK", .family = NFPROTO_IPV4, .target = gwmark_target, .targetsize = sizeof(struct gwmark), .table = "mangle", .hooks = (1 << NF_INET_PRE_ROUTING) | (1 << NF_INET_LOCAL_OUT), .checkentry = gwmark_check, .me = THIS_MODULE, };static unsigned int ipv4_conntrack_get(unsigned int hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *)){ enum ip_conntrack_info ctinfo; struct gwinfo *ginfo = NULL; struct nf_conn *ct = nf_ct_get(skb, &ctinfo); if (!ct) { return NF_ACCEPT; } //仅仅针对正方向的包进行ginfo管理 if (CTINFO2DIR(ctinfo) == IP_CT_DIR_ORIGINAL || ctinfo == IP_CT_NEW) { //如果是一个流的头包,那么设置该流的ginfo if(ctinfo == IP_CT_NEW) { ginfo = nf_ct_ext_add(ct, NF_CT_EXT_SGGW, GFP_ATOMIC); } else { //否则直接取出 ginfo = nf_ct_ext_find(ct, NF_CT_EXT_SGGW); } if (ginfo) { struct ethhdr *eth = (struct ethhdr*)(skb->data - ETH_HLEN); //保存数据包的源MAC地址,用以自动封装返回包的目标MAC memcpy(ginfo->reply_gw_mac, eth->h_source, ETH_ALEN); //保存数据包的目标,以求在数据被用户态(比如OpenVPN)重新封装后直接封装目标MAC地址 memcpy(ginfo->orig_gw_mac, eth->h_dest, ETH_ALEN); //保存设备变量,因为想直接发送一个数据而不经路由,必须指定一个设备 ginfo->dev = skb->dev; //默认数据不是本地用户态发出的 ginfo->local_flag = 0; } } return NF_ACCEPT;}//这个HOOK函数没什么大不了的,旨在设置local标志static unsigned int ipv4_conntrack_get_local(unsigned int hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *)){ struct gwinfo *ginfo = NULL; enum ip_conntrack_info ctinfo; struct nf_conn *ct = nf_ct_get(skb, &ctinfo); if (!ct) { return NF_ACCEPT; } ipv4_conntrack_get(hooknum, skb, in, out, okfn); if (CTINFO2DIR(ctinfo) == IP_CT_DIR_ORIGINAL || ctinfo == IP_CT_NEW) { ginfo = nf_ct_ext_find(ct, NF_CT_EXT_SGGW); if (ginfo) { ginfo->local_flag = 1; } } return NF_ACCEPT;}//以下的HOOK函数实现自动封装以太帧而不经路由的逻辑static unsigned int ipv4_conntrack_set(unsigned int hooknum, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *)){ enum ip_conntrack_info ctinfo; struct gwinfo *ginfo = NULL; struct net_device *dev = NULL; unsigned int local = 0; struct nf_conn *ct = nf_ct_get(skb, &ctinfo); if (skb->mark == g_mark.reply_mark && CTINFO2DIR(ctinfo) == IP_CT_DIR_REPLY && hooknum == NF_INET_PRE_ROUTING) { ginfo = nf_ct_ext_find(ct, NF_CT_EXT_SGGW); if (ginfo) { dev = ginfo->dev; } } else if (skb->mark == g_mark.orig_mark && CTINFO2DIR(ctinfo) == IP_CT_DIR_ORIGINAL && hooknum == NF_INET_LOCAL_OUT) { ginfo = nf_ct_ext_find(ct, NF_CT_EXT_SGGW); if (ginfo) { struct dst_entry * dst = skb_dst(skb); dev = (struct net_device*)dst->dev; local = 1; } } if (dev) { //这里的逻辑再明显不过了,直接在PREROUTING这个HOOK点上执行XMIT... struct ethhdr *eth = (struct ethhdr*)skb->data - ETH_HLEN; if (local) { memcpy(eth->h_dest, ginfo->orig_gw_mac, ETH_ALEN); } else { memcpy(eth->h_dest, ginfo->reply_gw_mac, ETH_ALEN); } skb->dev = dev; dev_queue_xmit(skb); return NF_STOLEN; } return NF_ACCEPT;}static struct nf_hook_ops ipv4_conntrack_gwops[] __read_mostly = { { .hook = ipv4_conntrack_get, .owner = THIS_MODULE, .pf = NFPROTO_IPV4, .hooknum = NF_INET_PRE_ROUTING, .priority = NF_IP_PRI_CONNTRACK+1, }, { .hook = ipv4_conntrack_get_local, .owner = THIS_MODULE, .pf = NFPROTO_IPV4, .hooknum = NF_INET_LOCAL_OUT, .priority = NF_IP_PRI_CONNTRACK+1, }, { .hook = ipv4_conntrack_set, .owner = THIS_MODULE, .pf = NFPROTO_IPV4, .hooknum = NF_INET_PRE_ROUTING, .priority = NF_IP_PRI_MANGLE+1, },};//init函数为例行注册static int __init nf_conntrack_sggw_init(void){ int ret = 0; ret = nf_register_hooks(ipv4_conntrack_gwops, ARRAY_SIZE(ipv4_conntrack_gwops)); if (ret < 0) { printk("nf_conntrack_ipv4: can't register gw hooks.\n"); } ret = nf_ct_extend_register(&sggw_extend); //注册 if (ret < 0) { printk(KERN_ERR "sggw: Unable to register extension\n"); return ret; } ret = xt_register_target(&gwmark_tg); if (ret < 0) { printk(KERN_ERR "sggw: Unable to register target\n"); return ret; } return ret;}//fini函数为例行解注册static void __exit nf_conntrack_sggw_fini(void){ synchronize_net(); nf_unregister_hooks(ipv4_conntrack_gwops, ARRAY_SIZE(ipv4_conntrack_gwops)); nf_ct_extend_unregister(&sggw_extend); xt_unregister_target(&gwmark_tg);}module_init(nf_conntrack_sggw_init);module_exit(nf_conntrack_sggw_fini);MODULE_ALIAS("sggw");MODULE_LICENSE("GPL");