NLP中文信息处理---正向最大匹配法分词
弄了好几天正向最大匹配法分词,终于弄完了吧。Python写的。Python确实是一门好语言,写起来很简单、顺手。
一、关于正向最大匹配法分词
中文分词(Chinese Word Segmentation)指的是将一个汉字序列切分成一个一个单独的词。中文分词是文本挖掘的基础,对于输入的一段中文,成功的进行中文分词,可以达到电脑自动识别语句含义的效果。
正向最大匹配法:
例子: 将句子 ’ 今天来了许多新同事 ’ 分词。 设最大词长为5
今天来了许
今天来了
今天来
今天 ====》 得到一个词 – 今天
来了许多新
来了许多
来了许
来了
来 ====》 得到一个词 – 来
了许多新同
了许多新
了许多
了许
了 ====》 得到一个词 – 了
许多新同事
许多新同
许多新
许多 ====》得到一个词 – 许多
新同事
新同
新 ====》得到一个词 – 新
同事 ====》得到一个词 – 同事
最后正向最大匹配的结果是:/今天/来/了/许多/新/同事/
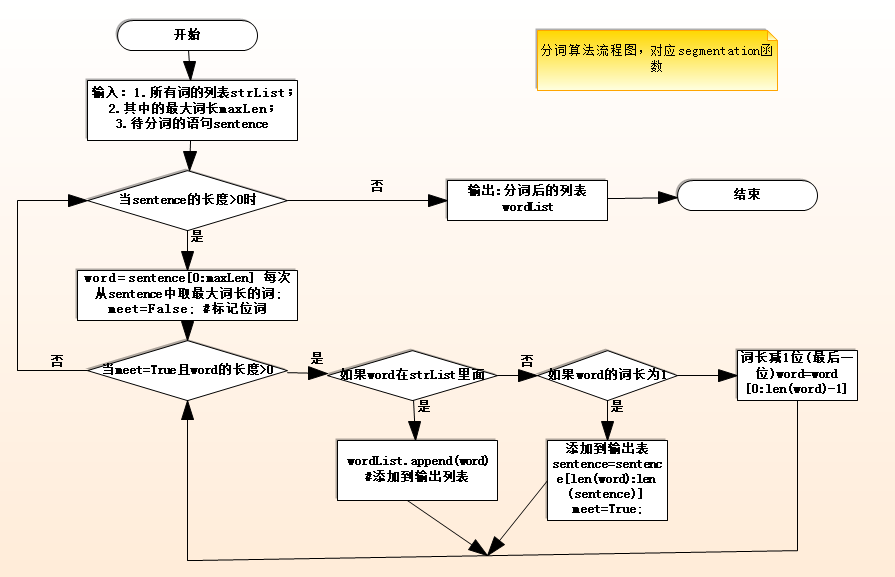
二、正向最大匹配分词算法
三、语料库的处理与算法的输入
语料库的处理流程:
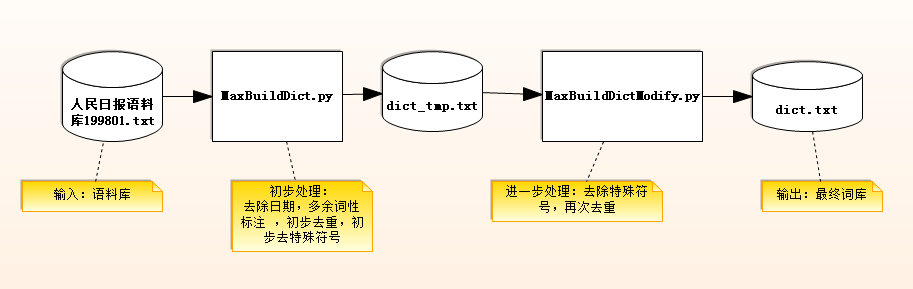
输入:人民日报语料库199801.txt
输出:dict.txt词表文件
分词算法:
输入:将dict.txt处理后得到的list集,以及最大词长;待分词的句子
输出:分词后的句子
四、Python实现
1. 语料库的初步处理 ( MaxBuildDict.py )
六、总结
关于效率:
正向最大匹配法分词占用很大计算量,结果本人测试,100多个字的一段话一般2秒分完。1000个字的一段话,需要20几秒才能分完。以最大词长为20来计算的话,待分的句子为20个字,假设全部分成2字词,词表中有5万个词,则计算量约为22*5*50000=550万。如此可见,当待分词句子很长,最大词长很大时,计算量是惊人的。
关于分词准确度:
正向最大匹配法的缺陷在与精确度不能达到理想的状态。同时也不能解决词的歧义问题。(统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。)
(文章如有错误,敬请指正)
运行源码以及全部文档下载地址: http://download.csdn.net/detail/xn4545945/5182311
原创文章,转载请注明出处,违者必究:http://blog.csdn.net/xn4545945