一起玩转SQL Server 2012 下的分析服务
提到SQL Server 2012的分析服务,那么不得不先说下商业智能,它是一个由数据转换成知识的过程。此篇将对SQL Server 2012的分析服务(Analysis Services)以及跟其相关的商业智能做一个简要的介绍,将以一个普通开发人员的角度去阐述和介绍分析服务以及商业智能。


分析服务是SQL Server的一个服务组件。作为一个应用程序开发人员,你已经很熟悉数据库和表,这些在SQL Serer的服务组件中是属于数据库引擎的范畴。还记得你每次打开Management Studio吗?

这个启动界面,也许您还不太清楚SQL Server跟Visual Studio有何关系,看完此篇您就明白了。
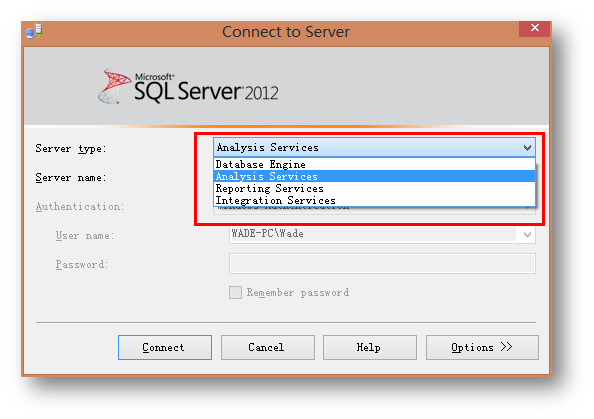
每次打开的时候都会让你选择Server type。除了你常用的Database Engine之外,其余的几个组件,集成服务,报表服务和分析服务,它们加起来就构成了SQL Server端商业智能中的核心组件。
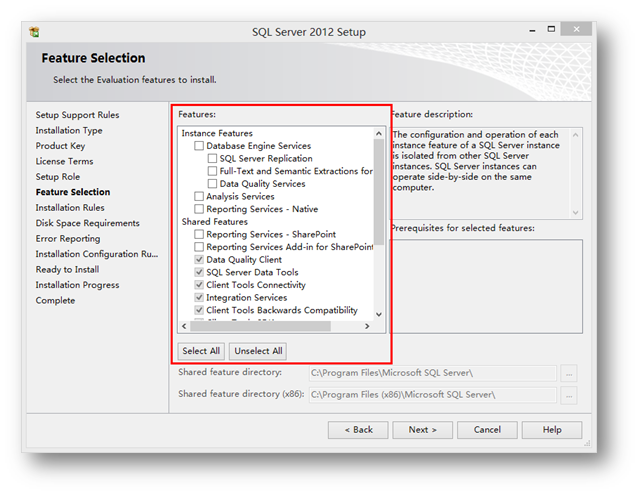
如果你选择全部安装了SQL Server的组件,也就是下面的勾全部勾上。(当然,如果你只是做应用程序开发,那么只推荐你单独安装数据引擎服务就可以了,因为其它的服务你安装后运行起来确实很占资源。)
SQL Server 2012里特殊的地方就是分析服务中多了一个Tabular Mode模式,在安装过程中,如果选择安装了分析服务,那么在分析服务配置过程中会出现下面一个界面选择安装分析服务的哪种模式。
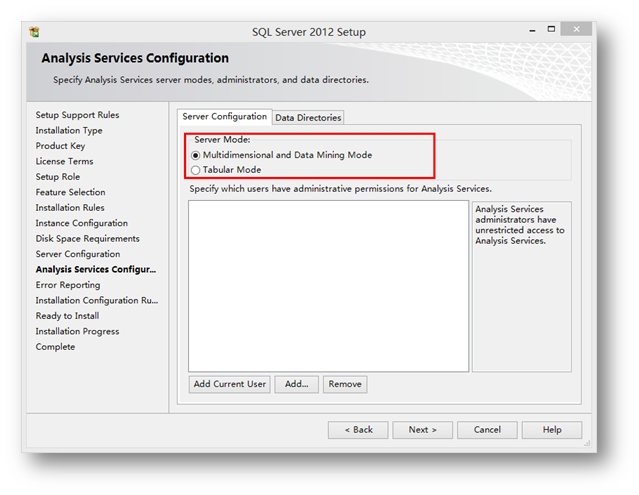
在SQL Server 2012下同一个分析服务示例只能以一种方式存在。如果你想使用两种模式,那么只能选择安装两个分析服务实例。
在安装完毕后,就可以在服务列表里看到类似如下已经安装好的服务。
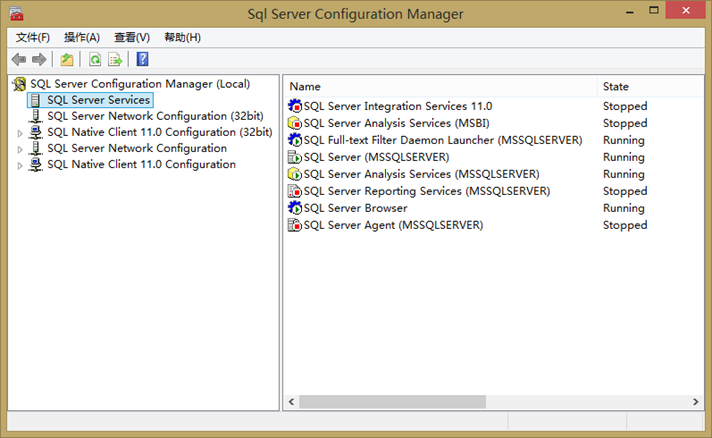
如你所见,平时不用的服务我都是关闭掉的,尤其是报表服务,它们都很占系统资源,即使我笔记本安装的系统内存扩充到了8GB,那我也会选择平时尽量关闭掉它们,然后需要的时候再打开。
可以看一下微软文档中各组件的结构图。
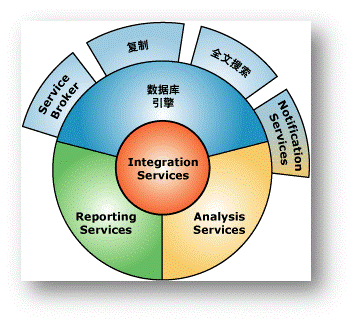
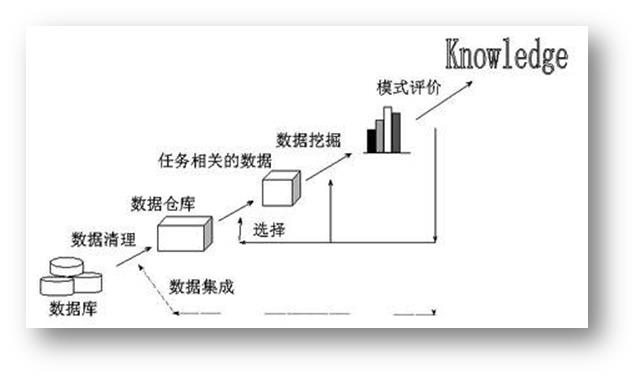
中间的集成服务,主要负责ETL的工作,它贯穿着其它几大主要的服务,这是一个数据的清洗加载和转换的过程(也就是折腾数据的过程),经过ETL的过程之后,数据由OLTP加载到OLAP中。这里面提到的OLTP是联机事务,通常说的某系统都可以归属到这个范围,比如程序员们经常开发的财务管理系统,人力资源管理系统,进销存系统,客户关系管理何办公自动化等,它们主要在数据库这层的工作就是增删查改。OLAP是联机分析处理系统,从字面上可以看出这一层主要的任务就是分析,比如报表系统,数据统计和分析以及数据挖掘。
此外还有一个数据仓库的概念,数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。说简单些可以理解为,这一层是把各个业务系统的数据整合到了一起,并且结构会被转换成适合分析的结构的一个特殊的数据库。
也许很多人在此不会很明白(包括早些年刚开始接触BI的我),既然有OLTP了,那么为什么还需要ETL到OLAP呢?想要什么查询一个SQL语句不就搞定?
首先,数据单独传输到OLAP层,可以有效的防止分析系统跟业务系统抢占资源。对于很多大型系统来说,业务系统会非常的繁忙,而分析数据的语句往往都很复杂而且要消耗掉很多资源。分开后可以避免相互之间的影响。
其次,ETL是个很重要的过程,因为在OLAP端通常是整合了多个业务系统的,经过ETL整合到一起后,更方便统计查询。
最后,是为了降低查询统计分析的复杂度。经过聚合的数据通过MDX进行查询,将比直接用SQL语句查询更简洁明了。
在工作的过程当中,也有同事问我为什么不自己建立一套根据维度自己算聚合的方法,直接将其保存到表中。这种方法在一定程度上来说是可行的。但往往在项目正式结束之前,维度模型往往都是要变化的,比如加了一个维度,那么如果自己用表来聚合的话,每加一个或者减少一个以及更新一个维度那么就意外着聚合的方法需要重新改写。
再就一个行业内流传很广的一个事实是:写SQL的不如用Excel的赚的多,用Excel的不如用ppt的人赚的多。如上面所说,这个道理换成我也是好几年之后才明白。
此外,在baidu百科中找到一个表,可以更详细的了解二者之间还有什么差别。
OLTP
OLAP
用户
操作人员,低层管理人员
决策人员,高级管理人员
功能
日常操作处理
分析决策
DB 设计
面向应用
面向主题
数据
当前的, 最新的细节的, 二维的分立的
历史的, 聚集的, 多维的
集成的, 统一的
存取
读/写数十条记录
读上百万条记录
工作单位
简单的事务
复杂的查询
DB 大小
100MB-GB
100GB-TB
从上表中,我们就可以看到为什么微软会提出列式存储以及PDW(并行数据仓库)的产品。
下图是一个最简单的BI流程。
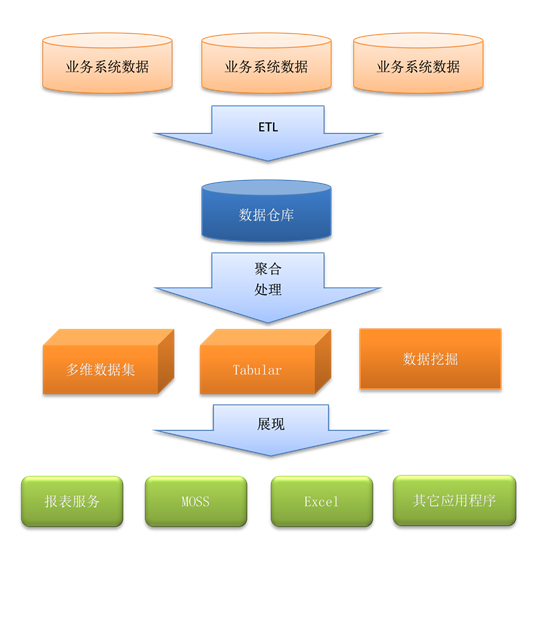
从上到下,可以看到通过BI的流程,首先将各个不同业务数据整合到一起到数据仓库中,然后数据仓库的数据经过聚合或者处理到分析服务中,最后通过前端工具展现出来。
中间那层,包含多维数据集,Tabular和数据挖掘这一层,对应的就是SQL Sever分析服务。
此外,我先前写过一个关于BI通用流程的随笔:
http://www.cnblogs.com/aspnetx/archive/2010/03/06/1679896.html
还有,关于BI项目的具体技术方案,也可以参考我的这两篇随笔:
http://www.cnblogs.com/aspnetx/archive/2011/10/10/2206713.html
http://www.cnblogs.com/aspnetx/archive/2011/11/30/2268886.html
以上简单的介绍了分析服务以及商业智能和数据仓库的一些概念,并且引用了我先前的几篇随笔供详细参考,下面详细介绍SQL Server分析服务的各个部分。
多维数据集
多维数据集是目前很多BI项目中都在用的,它根据维度的定义将事实表里的数据进行聚合运算,从而在牺牲处理时间和额外的聚合存储空间来换取统计查询的相应速度。
多维数据集可以理解为是一个立方体,比如下图:
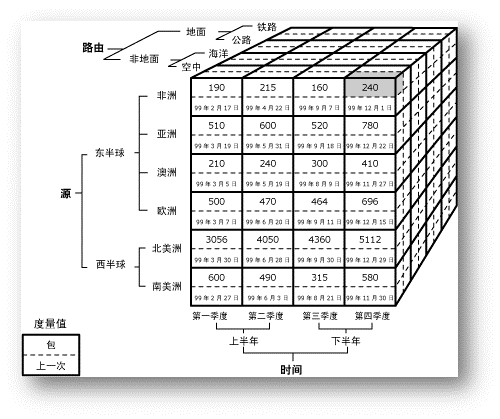
我们看到在图中,立方体有三个轴分别对应三个维度:时间,空间和运输方式。实际的多维数据集可以简单的理解成这个模式,只不过,在定义问题的时候,可以定义出好多的维度。
再如下面的一个立方体,三个轴分别为客户时间和产品,魔方里的每一个小块儿代表某一客户某一时间点购买某一产品的多少。
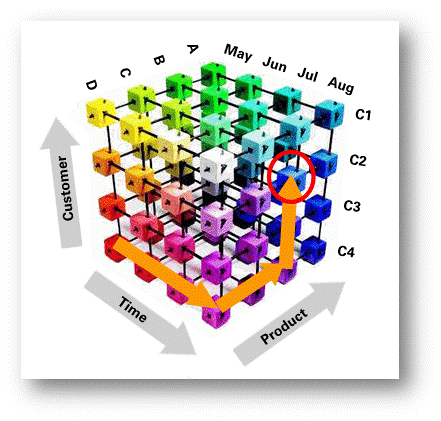
当然,在实际的分析中,在透视表里我们不一定非要用上三个维度才叫立方体(Cube),更多的时候我们会用任意多的维度组合来分析问题,而在分析过程中,同一个轴也可能会包含更多地维度,比如从客户维度下钻到产品维度等。实际的操作都是一个基于维度的相当灵活的过程。
关于如何创建简单的多维数据集,可以参考我下面的一篇随笔:
http://www.cnblogs.com/aspnetx/archive/2013/03/16/2963965.html
此外,入门的朋友我建议详细的看一下微软SQL Server文档中的教程。
http://technet.microsoft.com/zh-cn/library/ms170208.aspx
查询多维数据集是用MDX,跟SQL一样,它也是SELECT FROM WHRER这样的结构,比如:
WITH
MEMBER Measures.[Amount Change Rate] AS
IIF(ISEMPTY(([Measures].[Internet Sales Amount],[Date].[Fiscal].CurrentMember.PrevMember)), "",
[Measures].[Internet Sales Amount]/
([Measures].[Internet Sales Amount],[Date].[Fiscal].CurrentMember.PrevMember) -1
), FORMAT_STRING = '0%'
SELECT
{[Measures].[Internet Sales Amount], Measures.[Amount Change Rate]} ON 0,
[Date].[Fiscal].[Month].MEMBERS
ON 1
FROM [Adventure Works]
查询结果:
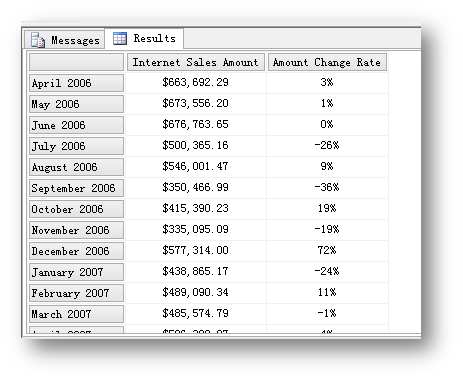
关于 MDX更详细的知识请参考微软的官方文档:
http://technet.microsoft.com/zh-cn/library/ms145506.aspx
Tabular Mode模式
多维数据集这种方式是由IT人员开发的,适合处理大量数据,默认情况下聚合后的文件是独立放在文件目录下。缺点是每当业务人员提出一个问题或者需求的时候,都需要等待IT部门长时间的响应,所以,针对这种需求,微软在SQL Server 2012中提出了Tabular Mode模式,在这种模式下,业务人员在Visual Studio中就可以自己来制作简单的分析模型,而操作的界面跟业务人员平时用的Excel和Access是非常像的,所以可以看到Tabular Mode就是微软专门为业务人员为了快速解决问题而提出的一个工具。
此外,Tabular Mode模式默认是把数据放到内存中,这样数据往往不需要经过特殊的优化就可以获取非常高的查询性能。
不过无论如何,我个人的观点,Tabular Mode还是无法取代多维数据集和IT人员的工作,因为Tabular Mode的数据毕竟是放在内存中的,所以要受到服务器的内存以及企业内部IT 管理策略的限制,而且很多数据还是需要IT人员经过ETL的整合,业务人员在Tabular Mode中拿过来用才有意义。不过,我更愿意以后看到两者的结合体出现,比如多维数据集把数据聚合到内存当中。
关于如何用Tabular Mode创建简单的分析模型,可以参考我下面的一篇随笔:
http://www.cnblogs.com/aspnetx/archive/2013/02/21/2920459.html
入门的朋友,建议一定要看一下微软文档中的教程:
http://technet.microsoft.com/zh-cn/library/hh231691.aspx
跟多维数据集不同的是,多维数据集定义一个计算成员用的是MDX,而Tabular Mode用的是DAX。这种结构更接近于Excel里的用法。
Days in Current Quarter:=COUNTROWS( DATESBETWEEN( 'Date'[Date], STARTOFQUARTER( LASTDATE('Date'[Date])), ENDOFQUARTER('Date'[Date])))比如如上的一条语句定义了一个命名成员。
关于DAX的参考,可以查看微软的官方文档;
http://technet.microsoft.com/zh-cn/library/gg413422.aspx
Excel中的透视表
在多维数据集和Tabular Mode模型建立完毕后,就可以在其之上做一些数据分析。Excel被微软介绍为其中一个强力工具,因为很多业务部门都很熟悉它,相对来说容易上手,而且更直观。
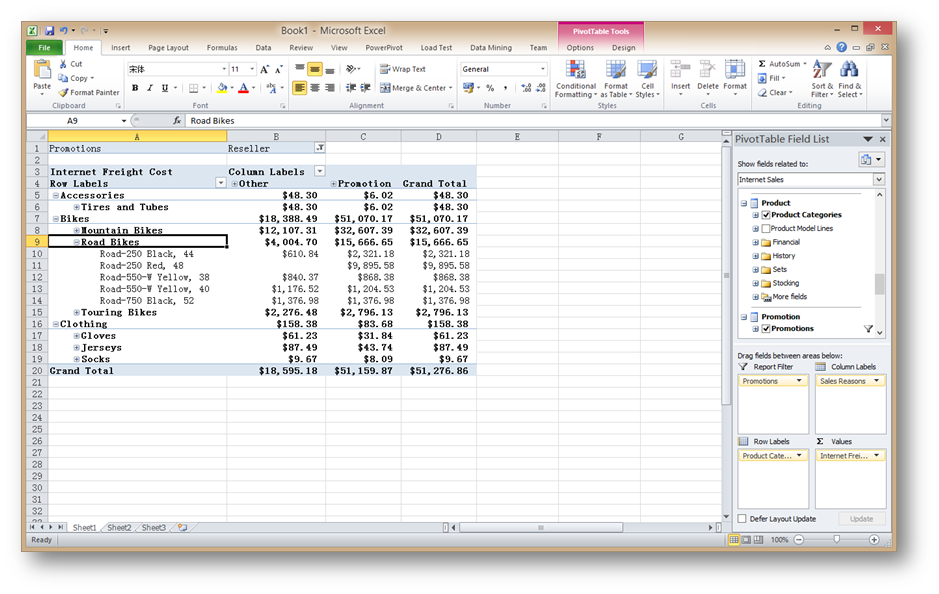
在Excel的透视表中,可以很方便的进行上钻下钻以及切片和切块等操作。
此外,还可以根据透视表切换成透视图。
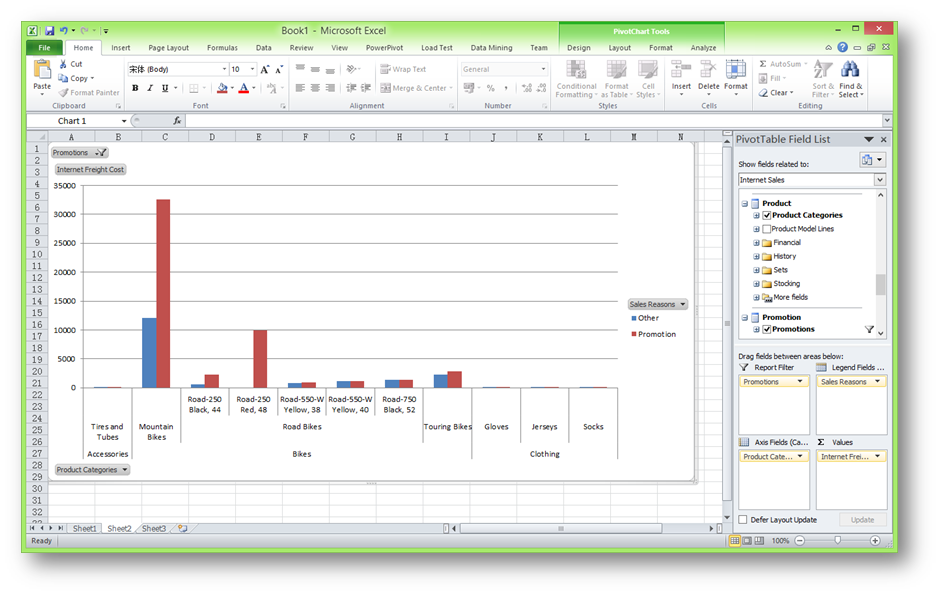
数据挖掘
关于分析服务另外一个比较有意思的就是数据挖掘,在商业智能中,数据挖掘是其中最高的一个层次。现在流行的大数据,最终往往也要靠数据挖掘来体现其价值。
如果说,BI的过程可以看成是数据的昨天,今天和明天,数据的昨天,通过报表告诉你的业务之前发生了什么,数据的今天,通过多维分析等工具告诉你这些为什么会发生,那么数据的明天,就是通过数据挖掘算法,对已有的海量历史数据进行挖掘,从而让你知道你的业务未来会是什么样。
微软的数据挖掘工具包含了很多算法,比较常见的比如贝叶斯,决策树,关联规则和时序分析等。
数据挖掘会分析样本数据,从中发现规则,然后用于对未来未知数据的预测。通常用来比如电商网站的商品推荐,潜在客户分析,以及客户分类等问题之上。
数据挖掘不是专门搞算法的工作人员的专利,作为开发人员,大家也可以一起来玩转一下SQL Server分析服务中的数据挖掘功能,我这里有一系列完整的介绍SQL Server分析服务数据挖掘的文章,通过电商网站中的商品推荐功能,介绍如何建立挖掘模型,然后在前段程序如何使用数据挖掘功能。此外,还有在Excel中进行数据挖掘的演示,以及如何通过DMX创建挖掘模型。
http://www.cnblogs.com/aspnetx/archive/2013/03/16/2963965.html
在这篇系列中,您可以跟我一样,作为一个不了解底层算法数学公司的开发人员,来玩转数据挖掘功能。而作为开发人员,除了基本的DMX需要掌握之外,还需要知道,什么样的挖掘模型适合解决什么样的问题。
关于SQL Server分析服务中数据挖掘各个模型的介绍,可以参考微软的这篇文档。
http://technet.microsoft.com/zh-cn/library/ms175595.aspx
此外,还是建议打算入门的朋友看一下微软的教程。
http://technet.microsoft.com/zh-cn/library/bb677206.aspx
数据挖掘的过程,跟其它IT项目一样,大概可以划分为如下几个过程。首先,定义问题,然后准备和浏览数据,然后生成和验证模型,最后部署和更新模型。
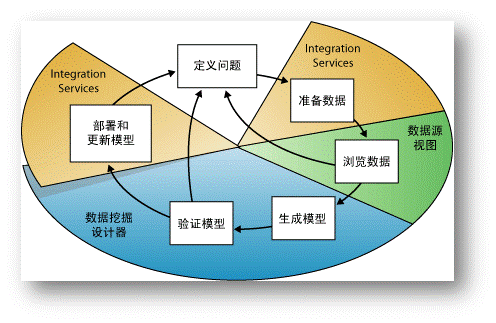
这个过程不一定是一口气道底的,比如在模型中发现没有需要的数据那么就需要重新对数据进行准备,或者在模型验证阶段发现有问题那么可能需要重新定义模型。
数据挖掘用到的查询语句是DMX,它可以用来创建和处理挖掘模型,并且做预测查询。可以参考我的这篇随笔来了解更多信息:
http://www.cnblogs.com/aspnetx/archive/2013/03/23/2976661.html

开发工具
SQL Server分析服务的开发都是通过Visual Studio的一个Shell。对于Visual Studio很多应用程序开发人员应该再熟悉不过,但是很少有人知道它也可以用来开发商业智能项目。
在安装完SQL Server Data Tools之后,在Visual Studio里就可以看到相应的项目模版,如下图:
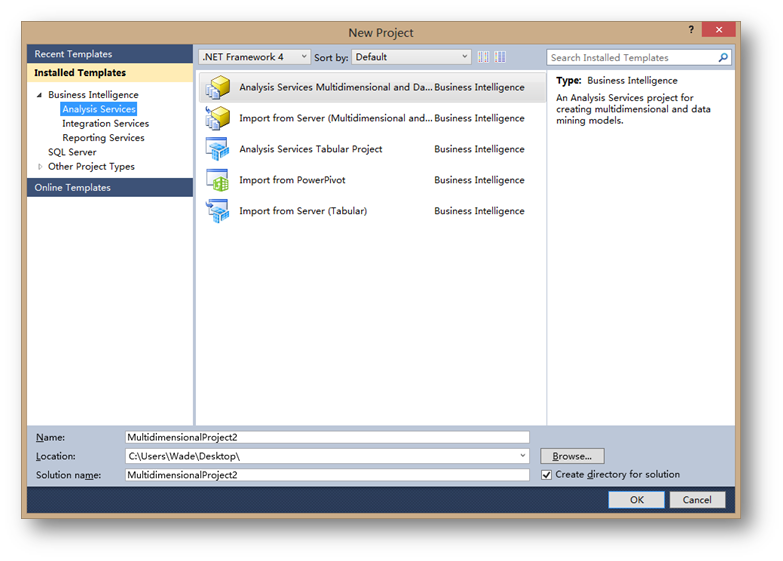
可以看到在项目模版里安装了三大类项目模版,分别就是分析服务,集成服务和报表服务。而在创建分析服务项目中,也可以看到分析服务被分成了多维模式和Tabular模式两种类型。
前面提到过,分析服务和数据引擎一样,下面也是各种数据库。传统.net开发数据库应用通过ADO.NET接口,分析服务是通过ADOMD.NET 接口。这两样接口不仅是名字比较像,由于它们继承自同一接口,所以当一个熟练的程序员操作ADOMD.NET的时候会感觉这种方式似曾相识。
关于ADOMD.NET的使用方式,大家可以参考我在数据挖掘商品推荐系列随笔的第二篇:
http://www.cnblogs.com/aspnetx/archive/2013/02/24/2924091.html
里面会有详细的介绍,会告诉你如何新建一个asp.net的web services然后找到ADOMD.NET 组件的所在位置以及如何使用它。
总结
上面对于分析服务进行了一个简短的介绍,在BI项目中的各个组件中,这确实是一个比较有趣而且也很有挑战的一部分。但这只是BI项目中工作量的一小部分。在一个BI项目中,大多数的工作都是在ETL之上,这是一个很复杂需要耐心和细心的过程,这项工作的工作量往往要超过整个BI项目工作量的60%,而一个企业内部的BI团队中,可以看到超过一半的人都是ETL这一层的开发人员。分析服务的工作往往都在ETL工作之后,并且很大程度上要受到这一层工作质量的影响。
在商业智能项目当中,最关键的就是数据,数据决定了一个商业智能项目的成败。这里面数据要满足三个层次,首先,就是要有数据可用,"巧妇难为无米之炊"用来形容这个再不为过。其次,数据量要达到一定的规模,只有数据越多才越容易发现其中的规律,好比一个刚毕业的医生和一个干了一辈子的医生的经验。最后,就是数据的质量,这是最重要的一个方面。很多系统尽管已经有了海量数据,但由于IT系统操作的不规范,所以导致积累了很多年的数据都无法发挥出价值。当然还有一个跟技术不太相关的一个因素也会影响着商业智能项目的成败,那就是高层领导的重视程度,商业智能当初设计就是为决策层服务的,而且实际项目过程中有很多问题都要靠行政的手段去解决,这个没有高层领导在身后的"撑腰"都是很难操作的。
至此,分析服务里的几个重要组件已经基本介绍完毕,包括多维模式,Tabular Model和数据挖掘,此篇分别对它们进行了简要的介绍,并且提供了笔者相应的链接资源作为引申参考。这篇随笔也算是我将之前掌握的知识和写的随笔做一个总结,相关的详细内容大家都可以去看我所提供的链接。
希望通过这篇简单的随笔,能够让更多的人了解SQL Server Analysis Services分析服务以及商业智能这个概念。