【北大天网搜索引擎TSE学习笔记】第9节――显示搜索结果
这一节将介绍搜索功能入口程序TSESearch.cpp的第六步――显示搜索结果。该部分中首先定义了一个结果显示类CDisplayRst的对象iDisplayRst,然后调用了该类的三个成员函数ShowTop,ShowMiddle和ShowBelow分别显示结果页面的头部、中部和底部(即图1中标注①②③的区域)。下面来看一下这三个函数的源代码,代码中加入了详细的注释(以“LB_C”开始的注释为我加入的)进行说明,另外再源代码之后还有一些问题的分析。
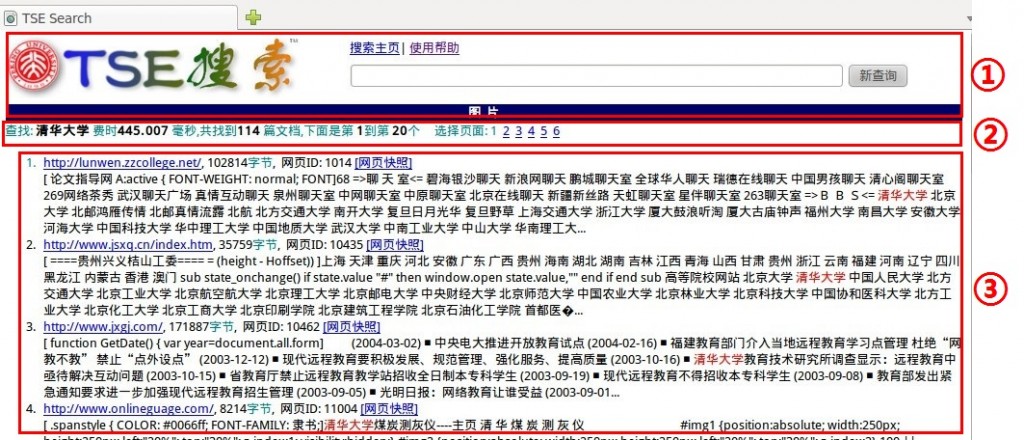
bool CDisplayRst::ShowBelow(vector<string>&vecQuery, set<string> &setRelevantRst, vector<DocIdx> &vecDocIdx, unsigned start){cout << "<ol>" << endl;set<string>::iterator it= setRelevantRst.begin();unsigned iDocNumber=0;//LB_c: start为用户选择的显示结果集的页号,RstPerPage为每页显示的记录条数,所以这里计算要显示的结果起止序号,// 即显示iRstBegin到iRstEnd的结果记录。这里也可以看出start页号应该是从1开始的。unsigned iRstBegin = (start-1)*RstPerPage;unsigned iRstEnd = start*RstPerPage - 1;vector<string> vecRefUrl;vector<string>::iterator itVecRefUrl;cout << "<tr bgcolor=#e7eefc>";bool bColor = true;//LB_c: 打开原始的原始网页数据库,用户点击"网页快照"时要从中读出网页并显示出来,这里也说明网页快照是//存在服务器的历史数据,而不是打开网址得到的实时网页。ifstream ifs(RAWPAGE_FILE_NAME.c_str());if (!ifs) {cout << "Cannot open " << RAWPAGE_FILE_NAME << " for input\n";return false;}for ( ; it!=setRelevantRst.end(); ++it,iDocNumber++ ){//LB_c: 这两行判断序号,在setRelevantRst中取出第iRstBegin到第iRstEnd条记录。if (iDocNumber < iRstBegin ) continue;if (iDocNumber > iRstEnd ) break;cout << "<li><font color=black size=2>" << endl ;//LB_c: 获取结果记录的docidint docId = atoi( (*it).c_str() );//LB_c: vecDocIdx在main函数中说明过,是网页索引表(记录docid到offset的映射),这里获取前后两个网页在//原始网页数据库中的offset,相减得到该网页的长度。int length = vecDocIdx[docId+1].offset - vecDocIdx[docId].offset;//LB_c: 建立缓冲区pContent,从原始网页数据库文件中读出该网页数据char *pContent = new char[length+1];memset(pContent, 0, length+1);ifs.seekg(vecDocIdx[docId].offset);ifs.read(pContent, length);char *s;s = pContent;string url,tmp = pContent;string::size_type idx1 = 0, idx2=0;//LB_c: 从网页数据中把url提取出来idx1 = tmp.find("url: ");if( idx1 == string::npos ) continue;idx2 = tmp.find("\n", idx1);if( idx1 == string::npos ) continue;url = tmp.substr(idx1+5, idx2 - idx1 - 5);//LB_c: vecQuery在main函数中介绍过,是搜索串分割以后的关键词,这里将这些关键词用"+"连接起来//在网页快照中显示,用于提示用户。string word;for(unsigned int i=0; i< vecQuery.size(); i++){ word = word + "+" + vecQuery[i]; }word = word.substr(1);//========================================================================================================//LB_c: 以下输出每条结果记录的具体内容,包括: 网页的链接,网页长度,网页快照链接和网页内容摘要//LB_c: 网页快照链接到另一个cgi程序: /yc-cgi-bin/index/Snapshot,即点击"网页快照"后,由cgi程序///yc-cgi-bin/index/Snapshot来处理。后面进行说明【分析3】cout << "<a href=" << url << ">" << url << "</a>, "<< length << "<font color=#008080>字节</font>" << ", "<< "<a href=/yc-cgi-bin/index/Snapshot?"<< "word=" << word << "&"<< "url="<< url<< " target=_blank>"<< "[网页快照]</a>" << endl << "<br>";if (length > 400*1024) { // if more than 400KBdelete[] pContent;continue;}//LB_c: 以下是从网页数据中提取正文,然后从正文中提取网页摘要,并进行显示。这里不详细解释。// skip HEAD int bytesRead = 0,newlines = 0;while (newlines != 2 && bytesRead != HEADER_BUF_SIZE-1) {if (*s == '\n')newlines++;elsenewlines = 0;s++;bytesRead++;}if (bytesRead == HEADER_BUF_SIZE-1) continue;// skip headerbytesRead = 0,newlines = 0;while (newlines != 2 && bytesRead != HEADER_BUF_SIZE-1) {if (*s == '\n')newlines++;elsenewlines = 0;s++;bytesRead++;}if (bytesRead == HEADER_BUF_SIZE-1) continue;CDocument iDocument;iDocument.RemoveTags(s);iDocument.m_sBodyNoTags = s;delete[] pContent;string line = iDocument.m_sBodyNoTags;CStrFun::ReplaceStr(line, " ", " ");CStrFun::EmptyStr(line); // set " \t\r\n" to " "// abstractstring reserve;if ((unsigned char)line.at(48) < 0x80) {reserve = line.substr(0,48);}else{reserve = line.substr(0,48+1);}reserve = "[" + reserve + "]";unsigned int resNum = 128;if (vecQuery.size() == 1) resNum = 256;for(unsigned int i=0; i< vecQuery.size(); i++){string::size_type idx = 0, cur_idx;idx = line.find(vecQuery[i],idx);if (idx == string::npos) continue;if (idx > resNum ) {cur_idx = idx - resNum;while ((unsigned char)line.at(cur_idx) > 0x80 && cur_idx!=idx) { cur_idx ++; }reserve += line.substr(cur_idx+1, resNum*2);}else{reserve += line.substr(idx, resNum*2);}reserve += "...";// highlightstring newKey = "<font color=#e10900>" + vecQuery[i] + "</font>";CStrFun::ReplaceStr(reserve, vecQuery[i], newKey);}line = reserve;cout << line << endl << endl;//========================================================================================================}cout << "</ol>";cout << "<br><br><hr><br>";cout << "© 2004 北大网络实验室<br><br>\n";cout << "</center></body>\n<html>";return true;}【分析3】:关于网页快照功能的实现在Snapshot.cpp中,本系列文章中不展开进行详细解释。但是有一点在这里指出一下,从Snapshot.cpp源代码中得知,快照功能处理的cgi程序根据传入的网页url从原始网页数据库中读出网页数据显示出来,而查找网页数据也处理的很复杂,先加载url索引文件,再根据传入url的MD5值到文件中找出相应的docid,然后从原始网页数据库中找到该网页的数据再进行显示。为何这样处理呢? 在ShowBelow中不是已经得到结果网页的网页数据了吗,可以缓存下来,需要显示网页快照时直接取出进行显示不就可以了吗?