【hadoop】大规模中文网站聚类kmeans的mapreduce实现(下)接上一篇,上一篇主要是计算tfidf,下篇主要是文档向
【hadoop】大规模中文网站聚类kmeans的mapreduce实现(下)
接上一篇,上一篇主要是计算tfidf,下篇主要是文档向量的建立以及kmeas的实现。
四 网页向量以及初始中心点选取 网页向量以及初始中心点的选取在 DocumentVetorBuid 中的一个 Mapreduce 中完成,中间过程如下表所示。
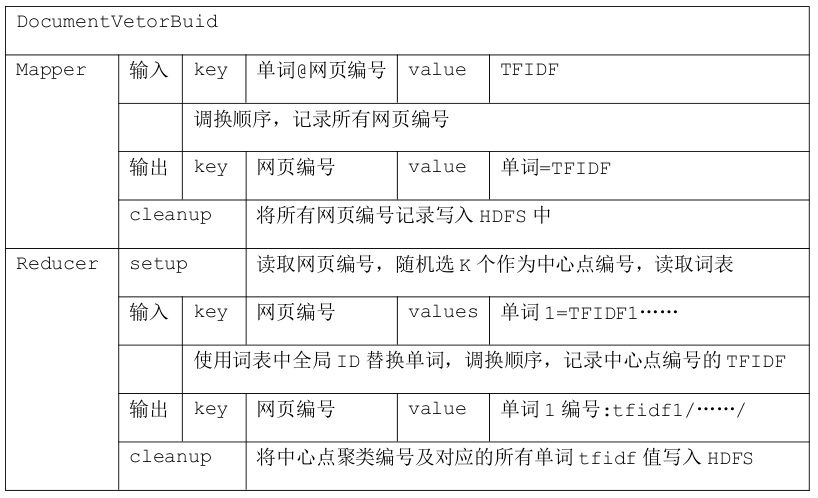
输出类似如下:
16 26272:0.00587873/22456:0.00264058/22502:0.00289516/23702:0.00278015/
五 Kmeans 聚类实现 DocTool 功能简介 为了简化 Kmeans 过程中的代码,将计算网页向量与中心点向量之间的余弦距离,并根据最大的余弦距离判断网页属于哪一类的方法抽象出来, Kmeans 的迭代过程中可以直接在调用,简化了 Kmeans 主类的代码复杂度。
其中,DocTool类中主要方法为:
public static int returnNearestCentNum(Map<Long, Double> doc,Map<Integer, Map<Long, Double>> centers, long dictSize)
输入:doc 指代网页向量,centers 指代所有的中心点向量的集合,dictSize 指代词表中词的总数。
输出:网页所归属的中心点编号。
详细请见github代码https://github.com/shenguojun/hadoop/blob/master/WebKmeans/src/edu/sysu/shen/hadoop/DocTool.java
Kmeans 主要 Mapreduce 介绍 Kmeans 主类由两个 Mapreduce 组成,一个是在迭代过程中更新中心点,一个是生成最后的结果,这两个 Mapreduce 的 Mapper 和 Rducer 的详细说明如下面两表所示。
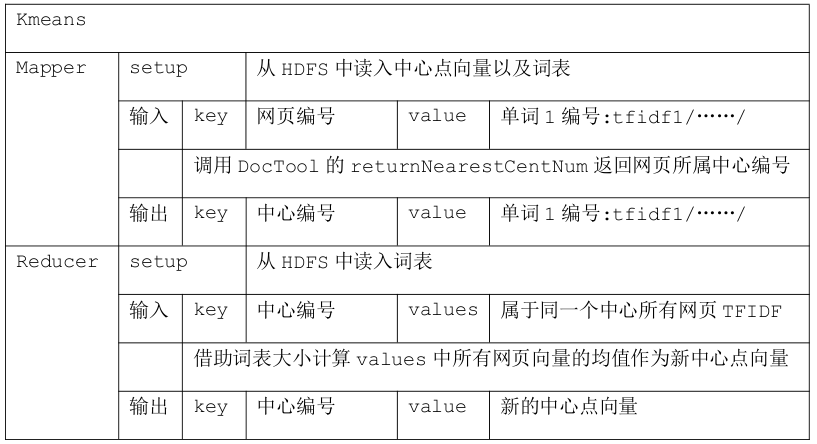
输出类似如下:
16 26272:0.00587873/22456:0.00264058/22502:0.00289516/23702:0.00278015/
上述的 Mapreduce 是在迭代过程的进行的,输入的是网页向量,并借助中心点向量通过计算后得到新的中心点向量作为输出。在迭代完毕后,需要最后一个 Mapreduce 输出符合格式的最终文件。最后一个 Mapreduce 详细说明如下表。
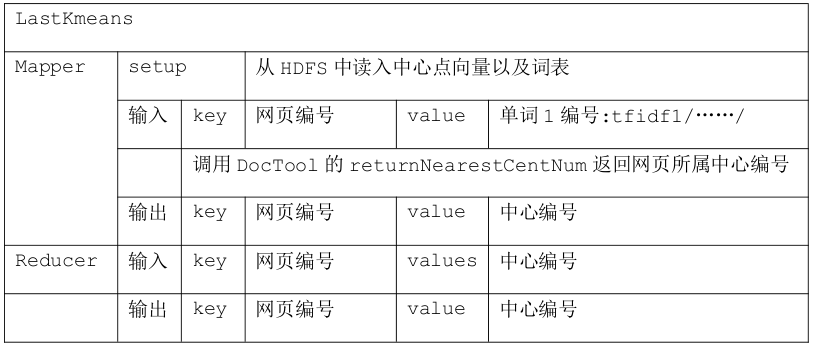
输出类似如下:
2977 34
2978 46
2979 36
2980 34
2981 34
2982 34
2983 34
KmeansDriver 流程 KmeansDriver 负责控制所有 MapduceJob 的执行流程,以及建立 configuration 传入每个Mapreduce 所需要的参数。
控制流程如第一部分的实现流程图所示。其中较为关键是 Kmeans过程中的迭代过程,在迭代过程中由两个因素控制循环的结束,一个是输入参数中的最大迭代次数,当达到最大迭代次数后循环就会结束。另一个是判断新生成的中心点与就的中心点是否相等,如果相等的话就会提前结束,在实验中,设置 20 个中心点,平均在迭代 10 次左右就会达到收敛条件。
其中判断中心点是否收敛的代码如下。
详细代码请见https://github.com/shenguojun/hadoop/blob/master/WebKmeans/src/edu/sysu/shen/hadoop/KmeansDriver.java
七 参考书籍:《大数据:互联网大规模数据挖掘与分布式处理》
《Mahout in Action》
《Hadoop in Action》
《Hadoop: The Definitive Guide》
论文:Weizhong Zhao, Huifang Ma, Qing He.Parallel K-Means Clustering Based on MapReduce .2009
Jiang Xiaoping, Li Chenghua, Xiang Wen, Zhang Xinfang, Yan Haitao.k-means 聚 类 算 法 的
MapReduce 并行化实现
网站:http://codingwiththomas.blogspot.com/2011/05/k-means-clustering-with-mapreduce.html
https://github.com/thomasjungblut/thomasjungblut-common/tree/master/src/de/jungblut/clustering
/mapreduce
http://code.google.com/p/hadoop-clusternet/wiki/RunningMapReduceExampleTFIDF


