hadoop日常维护,备份、恢复、增加移除节点
经验文档,写了很久了,现在贴出来吧,慢慢积累。
1. 机器配置
NO.
资产编号
IP
主机名
配置
1
192.168.42.20
server1
CPU:双核Pentium(R) Dual-Core CPU E5400 @ 2.70GHz
内存:4G
Swap:4G
磁盘:150G
2
192.168.42.21
server2
CPU:双核Pentium(R) Dual-Core CPU E5700 @ 3.00GHz
内存:2G
Swap:2G
磁盘:250G
3
192.168.42.22
server3
CPU:双核Pentium(R) Dual-Core CPU E5700 @ 3.00GHz
内存:2G
Swap:2G
磁盘:250G
4
192.168.42.23
server4
CPU:双核Pentium(R) Dual-Core CPU E5400 @ 2.70GHz
内存:4G
Swap:4G
磁盘:300G
注:
查看CPU:cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看内存:free –m
查看磁盘:df -m
处理器信息:dmidecode | grep -A48 'Processor Information$'
2. 网络拓扑:
安装版本:hadoop-0.20.2
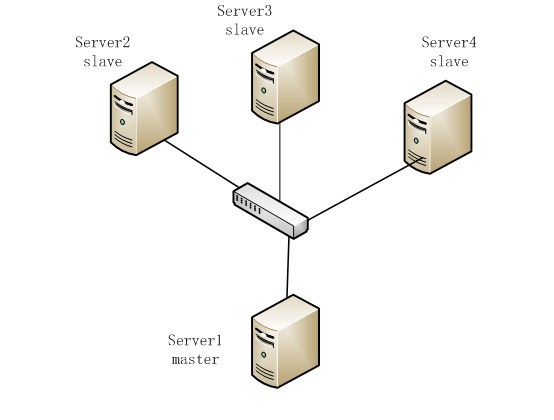
角色:
主机名
Hadoop角色
Hadoop jps命令结果
Hadoop用户
Hadoop目录
server1
Master
NameNode
TaskTracker
SecondaryNameNode
创建相同的用户的组名:hadoop。
安装hadoop-0.20.2时使用hadoop用户,并且hadoop的文件夹归属也是hadoop:hadoop
安装目录:/opt/hadoop
数据存储目录:
/hadoop
server2
slave
DataNode
TaskTracker
server3
slave
DataNode
TaskTracker
server4
slave
DataNode
TaskTracker
/etc/hosts文件配置
127.0.0.1 localhost
192.168.42.20 server1
192.168.42.21 server2
192.168.42.22 server3
192.168.42.23 server4
3. 动态移除节点
这里的节点节点包括datanode和tasktracker。一般来说,退出datanode也会把tasktracker也退出的。但按照配置,似乎可以只退出一个节点的datanode或tasktracker。这里同时将server2退出,解除其作为集群的datanode和tasktracker。
退出前,不要往将要退出的节点上写数据。
以下的文件修改、命令操作都是在master上进行。
3.1修改配置文件
需要在配置文件添加排除节点的属性配置。
编辑conf/hdfs-site.xml文件,增加如下配置:
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/hadoop_conf/exclude_node</value>
</property>
/opt/hadoop_conf/exclude_node指定需要退出的节点名。
如果同时要退出tasktracker,编辑conf/mapred-site.xml文件,增加如下配置:
<property>
<property>
<name>mapred.hosts.exclude</name>
<value>/opt/hadoop_conf/exclude_node</value>
</property>
/opt/hadoop_conf/exclude_node指定需要退出的节点名。
注意,这里datanode和tasktracker的排除文件指向同一文件,实际上可以分开。
要把server2节点退出hadoop集群,编辑exclude_node文件内容,增加需要退出的节点:
server2
3.2执行命令
hadoop dfsadmin -refreshNodes
该命令没有反应……
运行中的状态是:Decommissionin progress……
查看命令结果,命令行:
hadoop dfsadmin –report
#####下面是命令的一部分结果######
Name: 192.168.42.21:50010
Decommission Status : Decommission in progress
Configured Capacity: 243999055872 (227.24 GB)
DFS Used: 387870720 (369.9 MB)
Non DFS Used: 16118525952 (15.01 GB)
DFS Remaining: 227492659200(211.87 GB)
DFS Used%: 0.16%
DFS Remaining%: 93.24%
Last contact: Tue Nov 01 15:18:14 CST 2011
从网页中查看:
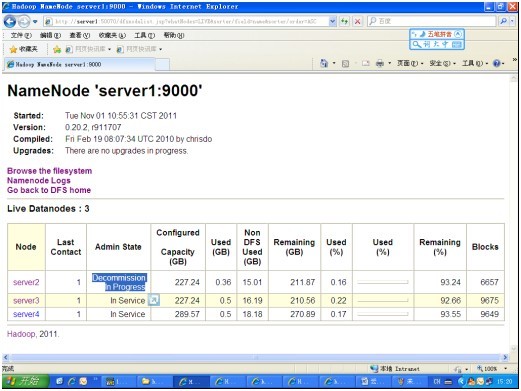
等待直到结束后,命令行的状态变为:Decommission Status: Normal
查看网页时,只剩下server3和server4这两个节点,server2退出,并且:
Live Nodes : 2
Dead Nodes : 1
3.3移除配置
从slaves文件中移除节点:
即将被移除的主机名从slaves文件中删除。
从conf/hdfs-site.xml和conf/mapred-site.xml先前添加的排除节点参数设置。或者从/opt/hadoop_conf/exclude_node中移除节点名。
3.4手动停掉tasktracker
在移除集群的server2是查看hadoop进程,发现tasktracker还运行着^.^!!!。经多方查找,也没有方法,只有手动停止。官方说在hadoop-0.20.2这个版本没有可以刷新jobtracker的命令。
找到tasktracker的PID,然后杀死:
hadoop@server2:~$ jps
25987 TaskTracker
16515 Jps
hadoop@server2:~$ ps -ef|grep 25987
hadoop@server2:~$ kill -9 25987
另一种方法是重启MapReduce集群。作为权宜之计,可以将mapred.jobtracker.restart.recover属性设为true,使用jobtracker能够在重启之后恢复正在运行的作业。――《hadoop权威指南》
3.5测试
4. 动态增加节点
4.1 增加server2节点
这里又把server2加入的hadoop集群。
在新的节点上(这里是server2),因为是刚刚从hadoop集群退出来的,其配置等环境已经OK了,那就可以直接在新节点启动datanode和jobtracker了:
hadoop@server2:~$ hadoop-daemon.sh start datanode
hadoop@server2:~$ hadoop-daemon.sh start tasktracker
然后打开http://server1:50070/查看,新节点server2已经添加进来了。
保持新节点与master节点的环境一致是最简单的了,这里回顾一下关键点:
ü /etc/hosts文件一致
ü Java,hadoop环境变量一致
ü Hadoop的配置文件一致
ü Master节点中在slaves文件中添加新节点名
最后考虑是否要运行均衡器。需要用户手动运行命令:
start-balancer.sh
4.2 控制可接入的节点
一台新节点是很容易加入集群的,如果随便都可以加入,那是非常危险的。所以还可以进行允许哪些节点加入集群的控制。
需要在配置文件添加允许节点的属性配置。
编辑conf/hdfs-site.xml文件,增加如下配置:
<property>
<name>dfs.hosts </name>
<value>/opt/hadoop_conf/include_node</value>
</property>
/opt/hadoop_conf/include_node指定允许加入的节点名。
编辑conf/mapred-site.xml文件,增加如下配置:
<property>
<name>mapred.hosts </name>
<value>/opt/hadoop_conf/include_node</value>
</property>
/opt/hadoop_conf/include_node指定允许加入的节点名。
编辑include_node文件内容,添加允许连接的节点:
server2
server3
server4
使用命令使配置生效:
hadoop dfsadmin -refreshNodes
在新节点上(这里是server2)运行命令:
hadoop@server2:~$ hadoop-daemon.sh start datanode
hadoop@server2:~$ hadoop-daemon.sh start tasktracker
但经过检测,只能够控制datanode的连接,tasktracker还是控制不了。
5. namenode的备份与恢复
5.1namenode的备份策略
要点:
ü 设置保存namenode的冗余路径。
在hdfs-site.xml文件里属性dfs.name.dir里,逗号分隔路径:
<property>
<name>dfs.name.dir</name>
<value>/hadoop/dfs/name,/mnt/nfs_name</value>
</property>
然后重启或进行格式化,两个路径下的文件都一样。冗余路径可以初始化前或运行过程中添加。
ü 将SecondaryNameNode放在另一台机器上运行。
conf/master配置文件指定运行SecondaryNameNode的机器。
ü 手动创建永久检查点。
#先进入安全模式
hadoop dfsadmin -safemode enter
hadoop dfsadmin -saveNamespace
hadoop dfsadmin -safemode leave
ü 自动创建永久检查点。
fs.checkpoint.period:单位秒,默认值3600,检查点的间隔时间,当距离上次检查点执行超过该时间后启动检查点
fs.checkpoint.size:单位字节,默认值67108864,当edits文件超过该大小后,启动检查点上面两个条件是或的关系,主要满足启动一个条件,检查点即被唤醒
5.2namenode的恢复
假设运行nodenode的节点server1突然宕机了,现在要从平时备份的文件中恢复。
ü 从冗余备份中恢复
1)准备一台运行namenode的机器,可能从datanode或SecondaryNameNode或备份的地方拷贝一份hadoop到新机器,各环境变量,参数配置相同,SSH连接没有问题。
2)将冗余的name目录中复制到新机器的name目录。如从/mnt/nfs_name下的所有文件复制到/hadoop/dfs/name目录下。(实践中发现不进行复制也可以,只要/mnt/nfs_name下有冗余的,hadoop启动后自动复制到/hadoop/dfs/name)
3)启动namenode和jobtracker服务。此时只有master节点宕掉了,slaves还在运行,所以只需要在新的master节点启动namenode和jobtracker服务也是可以的。不过一般都是先停止集群再重新启动,jobtracker死了以后,tasktraker也跟着死了,免得还要每个节点启动tasktraker。
#下面是在server2上启用新的master,secondarynamenode是在其它节点上
#不停止集群,只启动namenode和jobtracker
hadoop@server2:~$ hadoop-daemon.sh start namenode
hadoop@server2:~$ hadoop-daemon.sh start jobtracker
#先停止后启动
hadoop@server2:~$ stop-all.sh
hadoop@server2:~$ start-all.sh
#或者需要启动secondarynamenode和tasktracker
hadoop1@server1:~$ hadoop-daemon.sh start secondarynamenode
hadoop1@server1:~$ hadoop-daemon.sh start tasktracker
一般namenode有冗余备份,数据容易恢复,也不容易丢失,风险小。
ü 从SecondaryNameNode检查点文件中恢复
假设作为namenode的server1宕掉,namesecondary存放在server2中。准备一台新机器做为server1。
恢复时namesecondary的文件要放在namenode同一台机器上,如果namenode和namesecondary分开放,要先进行拷贝,首先确认namesecondary存放位置(fs.checkpoint.dir),然后从server2拷贝到server1:
scp -r /hadoop/dfs/namesecondary/* server1:/hadoop1/dfs/namesecondary/
在master的dfs.name.dir上新建一个文件夹name,恢复时name下是空的。然后执行:
hadoop namenode –importCheckpoint
#这是前台执行命令,建议转入后台
hadoop namenode –importCheckpoint &
使用hadoop fsck /命令检查文件Block的完整性,可以看到损坏的文件列表。
同时查看安全模式hadoop dfsadmin -safemode get。如果有损坏的文件,会一直运行在安全模式下,此时只有退出安全模式:hadoop dfsadmin –safemode leave。
删除或者移除损坏的文件:
hadoop fsck / -delete #删除损坏的文件
hadoop fsck / -move #把损坏的文件移到/lost+found
停止hadoop集群:stop-all.sh
删除(或先备份)namesecondary目录下的文件(新加master节点及server2中的namesecondary)。
然后然后重新启动。不过重新启动之前,应用先考虑是否对namenode节点进行冗余处理,即配置dfs.name.dir,增加冗余存放路径。
最后手动生成永久检查点:
#先进行安全模式,停止写入内容到edit
hadoop dfsadmin -safemode enter
hadoop dfsadmin -saveNamespace
hadoop dfsadmin -safemode leave
5.3
6. 待继。。。