MapReduce Design Patterns(chapter 7 (part 2))(十四)
External Source InputPattern Description
这种模式不从hdfs加载数据,而是从hadoop以外系统,例如RDB或web service加载。
Intent想要从非MapReduce框架的系统并行加载数据。
Motivation使用MapReduce分析数据通常的做法是把数据先存储到存储平台上,例如hdfs,然后分析。用这中模式,你可以使用MapReduce框架跟外部系统挂钩,例如数据库或web service,把数据直接拉到mapper。
这里有几个为什么你可能想直接从数据源获取分析数据而不是先存储再分析的原因。从hadoop以外系统加载数据比先存成文件要快。例如,把数据库dump到文件系统是代价高的操作,直接从数据库获取能保证job得到最新的可用数据。在一个繁忙的集群会有很多操作,运行分析前dump数据库也会失败,导致整个管道的停止。
MapReduce处理中,数据是并行加载的而不是串行。要注意的是,源数据需要有定义好的并行读取数据时的边界。例如,在分区数据库中每个map可以指定一个分区去从表中加载数据,这样便允许快速并行加载数据,而不需要扫描数据库。
Structure图7-3展示了这种模式的流程。
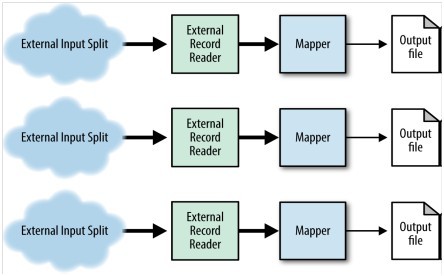
Figure 7-3. The structure of the external source input pattern
・InputFormat创建自定义的InputSplit对象,一个输入分片就是一个逻辑输入块,很大程度上取决于读数据的格式。这种模式中,输入不是基于文件的,而是外部系统。可以是一系列关系库表或集群中分布式。只要输入能并行读,就能用MapReduce处理的很好。
・InputSplit包含所有的信息,包括源系统地址,每个源系统读多少数据。框架使用位置信息决定map任务的指派。自定义的InputSplit必须实现writable接口,因为框架要使用这个接口的方法发送分片信息到TaskTracker。TaskTracker分配的map任务数跟输入格式生成的输入分片相等。然后初始化RecordReader。
・RecordReader使用job配置和InputSplit信息读取键值对。这个类的实现取决于被读数据的源。设置任何从外部系统读数据需要的连接,例如使用jdbc从数据库加载或用rest方式调用restful服务。
Consequences数据从外部系统加载数据到MapReduce job并且map阶段不知道或不关心数据来自哪。
Performance analysis用MapReduce job实现这种模式的瓶颈是源系统或网络。原系统可能不支持多连接(例如单线程数据库)。另一个问题是基础网路。源系统可能跟MapReduce集群不在一个网络基架,连接可能在较慢的公网上。如果源系统在集群内部就不成问题。
External Source Input ExampleReading from Redis Instances这个例子展示了怎样读取已经写到redis的数据。我们使用csv格式的redis实例主机列表,便于连接并从hash读所有的数据。由于我们在几个redis实例上分发数据,所以能并行读。我们需要做的就是对每个redis实例创建一个map任务,连上redis,对所有数据创建键值对。这个例子使用identity mapper简单输出从redis获取的键值对。
问题:给出csv格式redis实例列表,通过可配置的hash并行读取所有数据。
inputSplit code。RedisInputSplit表示要被一个mapper处理的数据。本例中,我们存储redis实例的主机名作为输入分片的地址,还有hash key。输入分片实现了writable接口,会被框架序列化,框架使用默认的构造器通过反射创建新实例。同过getLocation方法返回地址,希望JobTracker能够指定map到存有数据的主机。
publicstaticclass RedisHashInputSplitextends InputSplitimplements
Writable {
private Stringlocation = null;
private StringhashKey = null;
public RedisHashInputSplit() {
// Default constructor for reflection
}
public RedisHashInputSplit(String redisHost, String hash) {
this.location = redisHost;
this.hashKey = hash;
}
public String getHashKey() {
returnthis.hashKey;
}
publicvoid readFields(DataInput in)throws IOException {
this.location = in.readUTF();
this.hashKey = in.readUTF();
}
publicvoid write(DataOutput out)throws IOException {
out.writeUTF(location);
out.writeUTF(hashKey);
}
publiclong getLength()throws IOException, InterruptedException {
return 0;
}
public String[] getLocations()throws IOException, InterruptedException {
returnnew String[] {location };
}
}
Inputformat code。RedisHashInputFormat很多方面跟outputFormat对应。包含要连接到的redis实例的配置变量和要读的hash。getSplits方法里,检验配置,根据redis主机创建几个RedisHashInputSplits。会对每个配置的redis实例创建一个map任务。Redis主机名和hash key存在输入分片,给后面的RedisHashRecordReader用。框架调用createRecordReader得到recordReader的新实例。是通过调用初始化方法,所以能创建并返回它。按照惯例,这个类包含recordReader和inputSplit的实现子类。
publicstaticclass RedisHashInputFormatextends InputFormat<Text, Text> {
publicstaticfinal StringREDIS_HOSTS_CONF ="mapred.redishashinputformat.hosts";
publicstaticfinal StringREDIS_HASH_KEY_CONF ="mapred.redishashinputformat.key";
privatestaticfinal LoggerLOG = Logger
.getLogger(RedisHashInputFormat.class);
publicstaticvoid setRedisHosts(Job job, String hosts) {
job.getConfiguration().set(REDIS_HOSTS_CONF, hosts);
}
publicstaticvoid setRedisHashKey(Job job, String hashKey) {
job.getConfiguration().set(REDIS_HASH_KEY_CONF, hashKey);
}
public List<InputSplit> getSplits(JobContext job)throws IOException {
String hosts = job.getConfiguration().get(REDIS_HOSTS_CONF);
if (hosts ==null || hosts.isEmpty()) {
thrownew IOException(REDIS_HOSTS_CONF
+ " is not set in configuration.");
}
String hashKey = job.getConfiguration().get(REDIS_HASH_KEY_CONF);
if (hashKey ==null || hashKey.isEmpty()) {
thrownew IOException(REDIS_HASH_KEY_CONF
+ " is not set in configuration.");
}
// Create an input split for each host
List<InputSplit> splits = new ArrayList<InputSplit>();
for (String host : hosts.split(",")) {
splits.add(new RedisHashInputSplit(host, hashKey));
}
LOG.info("Input splits to process: " + splits.size());
return splits;
}
public RecordReader<Text, Text> createRecordReader(InputSplit split,
TaskAttemptContext context) throws IOException,
InterruptedException {
returnnew RedisHashRecordReader();
}
publicstaticclass RedisHashRecordReaderextends
RecordReader<Text, Text> {
// code in next section
}
publicstaticclass RedisHashInputSplitextends InputSplitimplements
Writable {
// code in next section
}
}
RecordReader code.大多数工作都在此处做。初始化方法提供输入格式里创建的输入分片。得到要连接的redis实例和hash key。然后连接上redis,得到要读的键值对的数量。Hash不关心迭代或串行处理数据时是单个还是批量处理,所以我们简单把所有数据拉出来并断开redis连接。通过条目保存迭代器并把有用的状态信息记在日志里。
nextKeyValue方法里,每次迭代条目的一个map并为键和值设置record reader的writable对象。返回true会通知框架已有一个键值对可以处理。处理完所有键值对,返回false,map任务结束。
recordReader 被框架使用的另外一个方法是为要执行的mapper拿到当前键值对。可能的话,重用这个对象很值得做。getProgress方法用于向jobTracker报告进度状态,也应该尽可能重用。最终,close方法最后调用。因为我们在initalize方法里拿到所有信息并关闭了redis连接,所以这里不需要做这些。
publicstaticclass RedisHashRecordReaderextends RecordReader<Text, Text> {
privatestaticfinal LoggerLOG = Logger
.getLogger(RedisHashRecordReader.class);
private Iterator<Entry<String, String>>keyValueMapIter =null;
private Textkey = new Text(),value = new Text();
privatefloatprocessedKVs = 0,totalKVs = 0;
private Entry<String, String>currentEntry =null;
publicvoid initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
// Get the host location from the InputSplit
String host = split.getLocations()[0];
String hashKey = ((RedisHashInputSplit) split).getHashKey();
LOG.info("Connecting to " + host +" and reading from " + hashKey);
Jedis jedis = new Jedis(host);
jedis.connect();
jedis.getClient().setTimeoutInfinite();
// Get all the key/value pairs from the Redis instance and store
// them in memory
totalKVs = jedis.hlen(hashKey);
keyValueMapIter = jedis.hgetAll(hashKey).entrySet().iterator();
LOG.info("Got " +totalKVs + " from " + hashKey);
jedis.disconnect();
}
publicboolean nextKeyValue()throws IOException, InterruptedException {
// If the key/value map still has values
if (keyValueMapIter.hasNext()) {
// Get the current entry and set the Text objects to the entry
currentEntry =keyValueMapIter.next();
key.set(currentEntry.getKey());
value.set(currentEntry.getValue());
returntrue;
} else {
// No more values? return false.
returnfalse;
}
}
public Text getCurrentKey()throws IOException, InterruptedException {
returnkey;
}
public Text getCurrentValue()throws IOException, InterruptedException {
returnvalue;
}
publicfloat getProgress()throws IOException, InterruptedException {
returnprocessedKVs /totalKVs;
}
publicvoid close()throws IOException {
// nothing to do here
}
}
Driver code。通过input format提供的静态方法修改job配置。只是使用了identity mapper,不需要设置特殊类。Reduce个数设为0.
publicstaticvoid main(String[] args)throws Exception {
Configuration conf = new Configuration();
String hosts = otherArgs[0];
String hashKey = otherArgs[1];
Path outputDir = new Path(otherArgs[2]);
Job job = new Job(conf,"Redis Input");
job.setJarByClass(RedisInputDriver.class);
// Use the identity mapper
job.setNumReduceTasks(0);
job.setInputFormatClass(RedisHashInputFormat.class);
RedisHashInputFormat.setRedisHosts(job, hosts);
RedisHashInputFormat.setRedisHashKey(job, hashKey);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, outputDir);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 3);
}
Partition PruningPattern Description分区裁剪指根据文件名配置框架挑选和丢弃的要加载到MapReduce的文件的方式。
Intent有一个根据预定义值分区的数据集,可以根据程序需要动态加载数据。
Motivation通常,加载到MapReduce job的所有数据指定给map,且并行读取。如果查询会丢掉所有文件,那么加载所有的文件是一种时间上的巨大浪费。如果用一个给定值分区数据,只查看给定值存在地方,就能消除大量的处理时间。例如,通常的数据分析是根据日期范围,按日期分区数据可以使你只加载需要的日期范围的数据。
这种模式要注意的地方是应该透明的处理,就能对不同的数据集重复利用相同的MapReduce job。这是靠简单的更改要查询的数据完成的,而不是更改job的实现。一种好的方法是,不看数据是怎样存储在文件系统上的,取而代之的是,把数据放入input format。Input format知道去哪儿定位和获取数据,允许基于查询的改变而选择相应数量的map任务。
Notice:这对存储的数据是不稳定且容易改变的情况特别有用。如果你有一些使用某种类型的输入格式的分析,就可以改变输入格式的实现重新编译。因为分析是从查询而不是文件得到数据,所以不必重复实现数据是怎么读的。这能节省大量的开发时间,让你在boss眼中的印象很好。
Structure图7-4展示了分区裁剪的结构,解释如下:
・inputFormat 是这种模式表现出生动的地方。我们要特别注意getSplits方法,因为它决定我们要创建的输入分片,这代表了map数量。配置通常是一些列文件,在这里却变成一个查询而不是一些文件路径。举例:如果数据在文件系统上按日期存储,inputFormat就能接受时间范围作为输入,然后决定哪个目录对应MapReduce job。如果在外部系统中数据是按日期分片的,例如为12个月12个分片,想查3月的数据只需要读一个分片。inputFormat用这里的key并根据查询决定数据来自哪,而不是传一些文件。
・RecordReader的实现取决于数据是怎么存储的。如果是基于文件的输入,像LineRecordReader这样的类可以用来读文件中的键值对。如果是外部系统,要自定义些需要的东西。
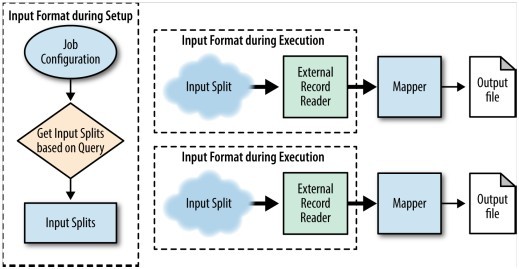
Figure 7-4. The structure of the partition pruning pattern
Consequences分区裁剪只是改变了被MapReduce job读的数据量,不会影响最终的分析结果。主要目的是减少读数据的时间。这靠忽略那些不产生输出的输入数据,这些输入并不跑map。
ResemblanceSql
很多关系型数据库都显示处理分区裁剪。当创建表时,指定数据库怎样分区数据及插入数据时如何处理。
CREATE TABLEparted_data
(foo_date DATE)
PARTITION BY RANGE(foo_date)
(
PARTITION foo_2012 VALUES LESS THAN(TO_DATE('01/01/2013','DD/MM/YYYY')),
PARTITION foo_2011 VALUES LESS THAN(TO_DATE('01/01/2012','DD/MM/YYYY')),
PARTITION foo_2010 VALUES LESS THAN(TO_DATE('01/01/2011','DD/MM/YYYY')),
);
然后,当你在where语句中用指定值查询时,数据库会自动使用相关的分区。
SELECT * FROM parted_data WHERE foo_date=TO_DATE('01/31/2012');
Performance analysis本模式中每个map任务的load数据速度跟其他模式相同。只有查询不同时,任务数量才会改变。利用这种模式,减少那些不会产生输出的数据对应的任务,从而获得很大的益处。除了io方面,性能主要取决于job的map和reduce阶段应用的模式。
Partition Pruning ExamplesPartitioning by last access date to Redis instances这个例子用一种合理的方式展示了redis中数据的存储和读取。替代随机分发用户-声誉映射数据的方式,我们根据特殊条件。用户-声誉映射数据根据上次访问时间分区并存储到6个不同的redis实例中。每2个月的数据根据不同的hash存在一个redis实例中。例如,1月和2月的数据存在实例0,3月和4月数据存在实例1,等等。
用这种方式分布数据,我们可以更智能的根据用户查询读数据。跟前面的通过命令行获取redis实例列表和hash key的方式不同,这种模式把input/output format中存储的方式和地方的逻辑都写死在代码里。这样彻底清除掉了mapper和reducer中数据来自哪里的信息,这样对开发者使用输入输出格式有优点和缺点。
Notice:把信息硬编码入java代码里,这可能是最好的主意,这代替了从format中找很少改变的配置文件的方式。这样,发生某些需要的改变就阻碍了重新编译。环境变量正好可以使用,可以通过命令行传递。
问题:给出用户数据,根据上次访问日期把用户-声誉值映射数据分区到6个redis实例。
Custom WritableComparable code.为了更好的存储信息,实现一个自定义的WritableComparable,以便允许mapper设置record writer需要的信息。这个类包含了存储在redis中的字段的get和set方法,包括上次访问月份字段,这个字段接受一个从0开始的整形值对应月份,但随后转成字符串,这是为了在下面的例子中更容易的查询。花时间实现compareTo方法,toString方法和hashCode方法(一个优秀程序猿应该做的)。
publicstaticclass RedisKeyimplements WritableComparable<RedisKey> {
privateintlastAccessMonth = 0;
private Text field =new Text();
publicint getLastAccessMonth() {
returnthis.lastAccessMonth;
}
publicvoid setLastAccessMonth(int lastAccessMonth) {
this.lastAccessMonth = lastAccessMonth;
}
public Text getField() {
returnthis.field;
}
publicvoid setField(String field) {
this.field.set(field);
}
publicvoid readFields(DataInput in)throws IOException {
lastAccessMonth = in.readInt();
this.field.readFields(in);
}
publicvoid write(DataOutput out)throws IOException {
out.writeInt(lastAccessMonth);
this.field.write(out);
}
publicint compareTo(RedisKey rhs) {
if (this.lastAccessMonth == rhs.getLastAccessMonth()) {
returnthis.field.compareTo(rhs.getField());
} else {
returnthis.lastAccessMonth < rhs.getLastAccessMonth() ? -1 : 1;
}
}
public String toString() {
returnthis.lastAccessMonth +"\t" + this.field.toString();
}
publicint hashCode() {
return toString().hashCode();
}
}
OutputFormat code.这个类很基本,因为大部分工作都在record writer中处理。主要关注点是集成outputFormat(原文有误)类是的模板参数。这个output format接受自定义类作为输出key,一个Text对象作为输出值。当写任何输出时,使用任何其他的类都会引起错误。
因为我们的record wirter的实现写入指定的已知的output,就不需要验证job的输出指定。框架仍需要一个输出提交者,所以我们用NullOutputFormat的output committer。
publicstaticclass RedisLastAccessOutputFormatextends
OutputFormat<RedisKey, Text> {
public RecordWriter<RedisKey, Text> getRecordWriter(
TaskAttemptContext job) throws IOException,
InterruptedException {
returnnew RedisLastAccessRecordWriter();
}
publicvoid checkOutputSpecs(JobContext context)throws IOException,
InterruptedException {
}
public OutputCommitter getOutputCommitter(TaskAttemptContext context)
throws IOException, InterruptedException {
return (new NullOutputFormat<Text, Text>())
.getOutputCommitter(context);
}
publicstaticclass RedisLastAccessRecordWriterextends
RecordWriter<RedisKey, Text> {
// Code in next section
}
}
RecordWriter code.这个类是模板化的,接受相同的类作为output format。构造器连上六个redis实例并放到map里。这个map里存的是月份到redis实例的映射,用于在write方法获取合适的实例。Write方法为了序列化,用月份的int值映射到三个字符。为了代码简洁,这个map代码忽略,样子是这样的:0→JAN, 1→FEB, ..., 11→DEC。这意味着redis中所有的hash都根据三个字符的月份代码命名。Close方法关闭与redis实例的连接。
publicstaticclass RedisLastAccessRecordWriterextends
RecordWriter<RedisKey, Text> {
private HashMap<Integer, Jedis> jedisMap =new HashMap<Integer, Jedis>();
public RedisLastAccessRecordWriter() {
// Create a connection to Redis for each host
int i = 0;
for (String host : MRDPUtils.REDIS_INSTANCES) {
Jedis jedis = new Jedis(host);
jedis.connect();
jedisMap.put(i, jedis);
jedisMap.put(i + 1, jedis);
i += 2;
}
}
publicvoid write(RedisKey key, Text value)throws IOException,
InterruptedException {
// Get the Jedis instance that this key/value pair will be
// written to -- (0,1)->0, (2-3)->1, ... , (10-11)->5
Jedis j = jedisMap.get(key.getLastAccessMonth());
// Write the key/value pair
j.hset(MONTH_FROM_INT.get(key.getLastAccessMonth()), key.getField()
.toString(), value.toString());
}
publicvoid close(TaskAttemptContext context)throws IOException,
InterruptedException {
// For each jedis instance, disconnect it
for (Jedis jedis : jedisMap.values()) {
jedis.disconnect();
}
}
}
Mapper code. mapper解析每条输入记录,设置输出rediskey和输出value。根据Calendar和SimpleDateFormat类解析出上次访问的月份。
publicstaticclass RedisLastAccessOutputMapperextends
Mapper<Object, Text, RedisKey, Text> {
// This object will format the creation date string into a Date object
privatefinalstatic SimpleDateFormat frmt =new SimpleDateFormat(
"yyyy-MM-dd'T'HH:mm:ss.SSS");
private RedisKey outkey =new RedisKey();
private Text outvalue =new Text();
publicvoid map(Object key, Text value, Context context)
throws IOException, InterruptedException {
Map<String, String> parsed = MRDPUtils.transformXmlToMap(value
.toString());
String userId = parsed.get("Id");
String reputation = parsed.get("Reputation");
// Grab the last access date
String strDate = parsed.get("LastAccessDate");
// Parse the string into a Calendar object
Calendar cal = Calendar.getInstance();
cal.setTime(frmt.parse(strDate));
// Set our output key and values
outkey.setLastAccessMonth(cal.get(Calendar.MONTH));
outkey.setField(userId);
outvalue.set(reputation);
context.write(outkey, outvalue);
}
}
Driver code。很基本。特殊的配置已在output format和record writer里处理了。
publicstaticvoid main(String[] args)throws Exception {
Configuration conf = new Configuration();
Path inputPath = new Path(args[0]);
Job job = new Job(conf,"Redis Last Access Output");
job.setJarByClass(PartitionPruningOutputDriver.class);
job.setMapperClass(RedisLastAccessOutputMapper.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, inputPath);
job.setOutputFormatClass(RedisHashSetOutputFormat.class);
job.setOutputKeyClass(RedisKey.class);
job.setOutputValueClass(Text.class);
int code = job.waitForCompletion(true) ? 0 : 2;
System.exit(code);
}
Querying for user reputation by last access date这个例子展示了怎样查询我们刚存在redis里的数据。跟大多数例子不同,比如提供hdfs上的文件路径,这里只需传入我们想要的数据的月份。至于去哪取数据,完全由input format智能的处理。
分区裁剪的核心是避免读没必要读的数据。通过把用户-声誉映射数据存到6个redis实例中,我们只需要连接存有我们需要月份数据的主机实例。更好的是,我们只需要从hash中得到存有指定月份的主机。例如,从命令行传入“JAN,FEB,MAR,NOV”将会创建三个输入分片,每一个分片对应一个redis实例(0,1,5),实例0上的所有数据都会读,实例1,5上的第一个月份的数据会读。这比连接到所有实例获取所有数据要好。
问题:根据月份查询用户-声誉映射数据,并行读取满足查询条件的数据。
inputSplit code.输入分片跟“External Source Input Example”里的类似。但不是存储一个hash key,这里存了多个hash key。这是因为数据是按月分区的,而不是所有的数据随机分发到一个hash里。
publicstaticclass RedisLastAccessInputSplitextends InputSplitimplements
Writable {
private Stringlocation = null;
private List<String> hashKeys =new ArrayList<String>();
public RedisLastAccessInputSplit() {
// Default constructor for reflection
}
public RedisLastAccessInputSplit(String redisHost) {
this.location = redisHost;
}
publicvoid addHashKey(String key) {
hashKeys.add(key);
}
publicvoid removeHashKey(String key) {
hashKeys.remove(key);
}
public List<String> getHashKeys() {
return hashKeys;
}
publicvoid readFields(DataInput in)throws IOException {
location = in.readUTF();
int numKeys = in.readInt();
hashKeys.clear();
for (int i = 0; i < numKeys; ++i) {
hashKeys.add(in.readUTF());
}
}
publicvoid write(DataOutput out)throws IOException {
out.writeUTF(location);
out.writeInt(hashKeys.size());
for (String key : hashKeys) {
out.writeUTF(key);
}
}
publiclong getLength()throws IOException, InterruptedException {
return 0;
}
public String[] getLocations()throws IOException, InterruptedException {
returnnew String[] {location };
}
}
InputFormat code。这个input format类根据要查询数据的月份智能创建RedisLastAccessInputSplit对象。跟前面的output format很像,output format写RedisKey对象,input format读相同的对象并在mapper的实现里模板化执行。开始创建主机-输入分片的hash map,以便把hash key加到输入分片上,而不是把两个月的数据加到相同的分片。如果一个指定月份的分片还没创建,就创建一个,并把这个月份的hash key加入。否则hash key加入已经创建的分片。然后创建一个list,存储map里的所有值。这将创建几个输入分片,数量等于满足查询条件的redis实例个数。
这里有几个有用的hash map帮助把月份字符串转换成整形,也计算出哪个redis实例拥有哪些月份的数据。这些hashmap的初始化过程略。
publicstaticclass RedisLastAccessInputFormatextends
InputFormat<RedisKey, Text> {
publicstaticfinal StringREDIS_SELECTED_MONTHS_CONF ="mapred.redilastaccessinputformat.months";
privatestaticfinal HashMap<String, Integer> MONTH_FROM_STRING =new HashMap<String, Integer>();
privatestaticfinal HashMap<String, String> MONTH_TO_INST_MAP =new HashMap<String, String>();
privatestaticfinal Logger LOG = Logger
.getLogger(RedisLastAccessInputFormat.class);
static {
// Initialize month to Redis instance map
// Initialize month 3 character code to integer
}
publicstaticvoid setRedisLastAccessMonths(Job job, String months) {
job.getConfiguration().set(REDIS_SELECTED_MONTHS_CONF, months);
}
public List<InputSplit> getSplits(JobContext job)throws IOException {
String months = job.getConfiguration().get(
REDIS_SELECTED_MONTHS_CONF);
if (months ==null || months.isEmpty()) {
thrownew IOException(REDIS_SELECTED_MONTHS_CONF
+ " is null or empty.");
}
// Create input splits from the input months
HashMap<String, RedisLastAccessInputSplit> instanceToSplitMap = new HashMap<String, RedisLastAccessInputSplit>();
for (String month : months.split(",")) {
String host = MONTH_TO_INST_MAP.get(month);
RedisLastAccessInputSplit split = instanceToSplitMap.get(host);
if (split ==null) {
split = new RedisLastAccessInputSplit(host);
split.addHashKey(month);
instanceToSplitMap.put(host, split);
} else {
split.addHashKey(month);
}
}
LOG.info("Input splits to process: "
+ instanceToSplitMap.values().size());
returnnew ArrayList<InputSplit>(instanceToSplitMap.values());
}
public RecordReader<RedisKey, Text> createRecordReader(
InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
returnnew RedisLastAccessRecordReader();
}
publicstaticclass RedisLastAccessRecordReaderextends
RecordReader<RedisKey, Text> {
// Code in next section
}
}
RecordReader code.这个类有点复杂,需要从多个hash里读,而不是仅仅在初始化方法里一次读取所有数据。这里的配置只是简单的读。
NextKeyValue过程里,如果要迭代的hash是null,或者已经到达要读的hash的末尾,就创建一个新的redis连接。如果要迭代的hash没有next value,立即返回false,因为已经没有数据需要map处理。否则,连上redis,取出指定hash的所有数据。这个hash迭代器用于取尽redis里的所有字段值对。用do-while循环保证一旦hash迭代结束,就从下一个hash取数据或通知任务数据已经读完了。
publicstaticclass RedisLastAccessRecordReaderextends
RecordReader<RedisKey, Text> {
privatestaticfinal Logger LOG = Logger
.getLogger(RedisLastAccessRecordReader.class);
private Entry<String, String> currentEntry =null;
privatefloatprocessedKVs = 0,totalKVs = 0;
privateintcurrentHashMonth = 0;
private Iterator<Entry<String, String>> hashIterator =null;
private Iterator<String> hashKeys =null;
private RedisKey key =new RedisKey();
private Stringhost = null;
private Text value =new Text();
publicvoid initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
// Get the host location from the InputSplit
host = split.getLocations()[0];
// Get an iterator of all the hash keys we want to read
hashKeys = ((RedisLastAccessInputSplit) split).getHashKeys()
.iterator();
LOG.info("Connecting to " +host);
}
publicboolean nextKeyValue()throws IOException, InterruptedException {
boolean nextHashKey =false;
do {
// if this is the first call or the iterator does not have a
// next
if (hashIterator ==null || !hashIterator.hasNext()) {
// if we have reached the end of our hash keys, return
// false
if (!hashKeys.hasNext()) {
// ultimate end condition, return false
returnfalse;
} else {
// Otherwise, connect to Redis and get all
// the name/value pairs for this hash key
Jedis jedis = new Jedis(host);
jedis.connect();
String strKey = hashKeys.next();
currentHashMonth = MONTH_FROM_STRING.get(strKey);
hashIterator = jedis.hgetAll(strKey).entrySet()
.iterator();
jedis.disconnect();
}
}
// If the key/value map still has values
if (hashIterator.hasNext()) {
// Get the current entry and set
// the Text objects to the entry
currentEntry = hashIterator.next();
key.setLastAccessMonth(currentHashMonth);
key.setField(currentEntry.getKey());
value.set(currentEntry.getValue());
} else {
nextHashKey = true;
}
} while (nextHashKey);
returntrue;
}
。。。
}
Driver code.驱动代码设置通过命令行传入的最近访问月份。Input format使用配置参数决定从哪个redis实例读,而不是读每个redis实例。也会设置job的输出目录。这里还是使用identity mapper而不会执行任何数据分析。
publicstaticvoid main(String[] args)throws Exception {
Configuration conf = new Configuration();
String lastAccessMonths = args[0];
Path outputDir = new Path(args[1]);
Job job = new Job(conf,"Redis Input");
job.setJarByClass(PartitionPruningInputDriver.class);
// Use the identity mapper
job.setNumReduceTasks(0);
job.setInputFormatClass(RedisLastAccessInputFormat.class);
RedisLastAccessInputFormat.setRedisLastAccessMonths(job,
lastAccessMonths);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, outputDir);
job.setOutputKeyClass(RedisKey.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true) ? 0 : 2);
}