Hadoop2-YARN 伪分布模式搭建
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value><final>true</final><description>The name of the default file system. A URI whose schemeand authority determine the FileSystem implementation. The uri'sscheme determines the config property (fs.SCHEME.impl) naming theFileSystem implementation class. The uri's authority is used todetermine the host, port, etc. for a filesystem.</description></property><property><name>hadoop.tmp.dir</name><value>/home/kevin/workspace-yarn/tmp</value><description>A base for other temporary directories.</description></property><property><name>io.native.lib.available</name><value>true</value><description>Should native hadoop libraries, if present, be used.</description></property><property><name>io.file.buffer.size</name><value>131072</value><final>true</final><description>The size of buffer for use in sequence files. The size ofthis buffer should probably be a multiple of hardware page size (4096on Intel x86), and it determines how much data is buffered duringread and write operations.</description></property></configuration>
??? (2)hdfs-site.xml???
<configuration><property><name>dfs.namenode.name.dir</name><value>/home/kevin/workspace-yarn/dfs/name</value><description>Determines where on the local filesystem the DFS namenode should store the name table(fsimage). If this is acomma-delimited list of directories then the name table is replicatedin all of the directories, for redundancy.</description><final>true</final></property><property><name>dfs.datanode.data.dir</name><value>/home/kevin/workspace-yarn/dfs/data</value><description>Determines where on the local filesystem an DFS data nodeshould store its blocks. If this is a comma-delimited list ofdirectories, then data will be stored in all named directories,typically on different devices. Directories that do not exist areignored.</description><final>true</final></property><property><name>dfs.namenode.edits.dir</name><value>/home/kevin/workspace-yarn/dfs/edits</value><description>Determines where on the local filesystem the DFS namenode should store the transaction (edits) file. If this is acomma-delimited list of directories then the transaction file isreplicated in all of the directories, for redundancy. Default valueis same as dfs.name.dir</description></property><property><name>dfs.replication</name><value>1</value><description>Default block replication. The actual number ofreplications can be specified when the file is created. The defaultis used if replication is not specified in create time.</description></property><property><name>dfs.permissions.enabled</name><value>false</value><description>If "true", enable permission checking in HDFS. If"false", permission checking is turned off, but all other behavior isunchanged. Switching from one parameter value to the other does notchange the mode, owner or group of files or directories.</description></property></configuration>
??? (3)mapred-site.xml???
<configuration><property><name>mapreduce.framework.name</name><valie>yarn</valie><description>The runtime framework for executing MapReduce jobs. Canbe one of local, classic or yarn.</description></property><property><name>yarn.app.mapreduce.am.staging-dir</name><value>/home/kevin/workspace-yarn/history/stagingdir</value><description>YARN requires a staging directory for temporary filescreated by running jobs. By default it creates/tmp/hadoop-yarn/staging with restrictive permissions that mayprevent your users from running jobs. To forestall this, you shouldconfigure and create the staging directory yourself.</description></property><property><name>mapreduce.task.io.sort.mb</name><value>100</value><description>The total amount of buffer memory to use while sortingfiles, in megabytes. By default, gives each merge stream 1MB, whichshould minimize seeks.</description></property><property><name>mapreduce.task.io.sort.factor</name><value>10</value><description>More streams merged at once while sorting files.</description></property><property><name>mapreduce.reduce.shuffle.parallelcopies</name><value>5</value><description>Higher number of parallel copies run by reduces to fetchoutputs from very large number of maps.</description></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>1024</value><description>The amount of memory on the NodeManager in GB, thedefault:8192.</description></property></configuration>
??? (4)yarn-site.xml??????
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce.shuffle</value><description>Shuffle service that needs to be set for Map Reduceapplications.</description></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value><description>The exact name of the class for shuffle service.</description></property><property><name>yarn.resourcemanager.scheduler.address</name><value>linux-fdc.tibco.com:8030</value><description>ResourceManager host:port for ApplicationMasters to talkto Scheduler to obtain resources.Host is the hostname of theresourcemanager and port isthe port on which the Applications in thecluster talk to the Resource Manager.</description></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>linux-fdc.tibco.com:8031</value><description>ResourceManager host:port for NodeManagers.Host is thehostname of the resource manager andport is the port on which theNodeManagers contact the Resource Manager.</description></property><property><name>yarn.resourcemanager.address</name><value>linux-fdc.tibco.com:8032</value><description>The address of the applications manager interface in theRM.</description></property><property><name>yarn.resourcemanager.admin.address</name><value>linux-fdc.tibco.com:8033</value><description>ResourceManager host:port for administrative commands.The address of the RM admin interface.</description></property><property><name>yarn.resourcemanager.webapp.address</name><value>linux-fdc.tibco.com:8088</value><description>The address of the RM web application.</description></property><property><name>yarn.nodemanager.local-dirs</name><value>/home/kevin/workspace-yarn/nm/local</value><description>Specifies the directories where the NodeManager storesits localized files.All of the files required for running aparticular YARN application will beput here for the duration of the application run.必须配置,如果不配置将使得NodeManager处于Unhealthy状态,无法提供服务,现象是提交作业时,作业一直处于pending状态无法往下执行。</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/home/kevin/workspace-yarn/nm/log</value><description>ResourceManager web-ui host:port.Specifies thedirectories where the NodeManager stores container log files.必须配置,如果不配置将使得NodeManager处于Unhealthy状态,无法提供服务,现象是提交作业时,作业一直处于pending状态无法往下执行。</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/home/kevin/workspace-yarn/aggrelog</value><description>Specifies the directory where logs are aggregated.</description></property></configuration>
?7. hadoop-env.sh增加JAVA_HOME
?? # The java implementation to use.
?? export JAVA_HOME=/usr/custom/jdk1.6.0_37
8. 格式化HDFS
?? bin/hdfs namenode -format
9. 启动HDFS
?? sbin/start-dfs.sh
?? 或者
?? sbin/hadoop-daemon.sh start namenode
?? sbin/hadoop-daemon.sh start datanode
10. 启动YARN
?? sbin/start-yarn.sh
?? 或者
?? sbin/yarn-daemon.sh start resourcemanager
?? sbin/yarn-daemon.sh start nodemanager
11.查看集群
?? (1)查看集群: http://192.168.81.251:8088/
?? (2)Namenode: localhost:50070/dfshealth.jsp
?? (3) SencondNameNode: 192.168.81.251:50090/status.jsp
12.Eclipse中运行Example: WordCount.java
??? 因为我内存较小的晕因,通过hadoop jar 命令直接运行hadoop-mapreduce-examples-2.0.2-alpha.jar
??? 中的wordcount时,在Map阶段就产出了Java hea space异常,在将WordCount代码Import
??? 进Eclipse时,按照Hadoop v1的方式运行该例子也遇到了不少的问题,现将我成功运行该例子的
??? 步骤记录下来,仅供参考:
??? (1) 启动RM, NM, NN, DN, SNN
??? (2) 上传测试文件:student.txt至HDFS
??? 创建/input文件夹:hadoop fs -mkdir /input
??? 上传文件:hadoop fs -put /home/kevin/Documents/student.txt /input/student.txt
??? 查看结果:
???? [kevin@linux-fdc ~]$ hadoop fs -ls -d -R /input/student.txt
???? Found 1 items
???? -rw-r--r--?? 1 kevin supergroup??????? 131 2013-01-19 10:30 /input/student.txt??? ???? 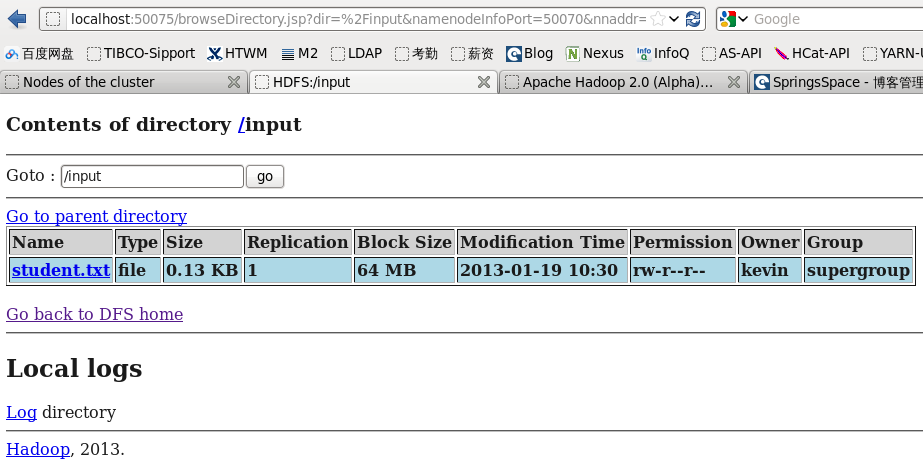
??? (3) Eclipse 中Run Configurations...中的Arguments Tab中在Program arguments中输入:
??? hdfs://localhost:9000/input hdfs://localhost:9000/output??? 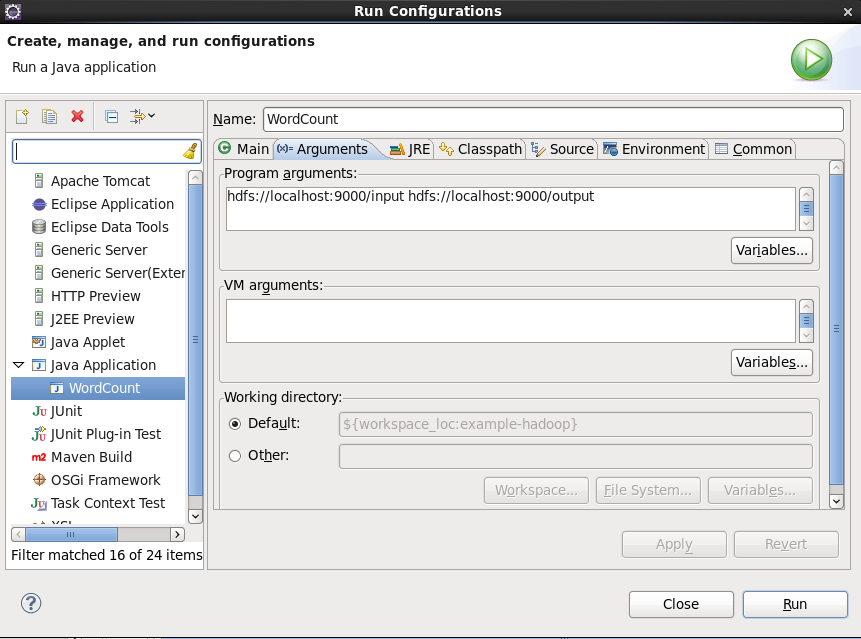
? ? (4) 运行日志???
2013-01-19 10:43:01,088 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - session.id is deprecated. Instead, use dfs.metrics.session-id2013-01-19 10:43:01,095 INFO jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId=2013-01-19 10:43:01,599 WARN util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2013-01-19 10:43:01,682 WARN mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(247)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String).2013-01-19 10:43:01,734 INFO input.FileInputFormat (FileInputFormat.java:listStatus(245)) - Total input paths to process : 12013-01-19 10:43:01,817 WARN snappy.LoadSnappy (LoadSnappy.java:<clinit>(46)) - Snappy native library not loaded2013-01-19 10:43:02,155 INFO mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(368)) - number of splits:12013-01-19 10:43:02,256 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class2013-01-19 10:43:02,257 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class2013-01-19 10:43:02,257 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class2013-01-19 10:43:02,257 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.job.name is deprecated. Instead, use mapreduce.job.name2013-01-19 10:43:02,258 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class2013-01-19 10:43:02,258 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir2013-01-19 10:43:02,258 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir2013-01-19 10:43:02,258 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps2013-01-19 10:43:02,259 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class2013-01-19 10:43:02,264 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir2013-01-19 10:43:02,545 INFO mapreduce.JobSubmitter (JobSubmitter.java:printTokens(438)) - Submitting tokens for job: job_local_00012013-01-19 10:43:02,678 WARN conf.Configuration (Configuration.java:loadProperty(2028)) - file:/home/kevin/workspace-eclipse/example-hadoop/build/test/mapred/staging/kevin-1414338785/.staging/job_local_0001/job.xml:an attempt to override final parameter: hadoop.tmp.dir; Ignoring.2013-01-19 10:43:02,941 WARN conf.Configuration (Configuration.java:loadProperty(2028)) - file:/home/kevin/workspace-eclipse/example-hadoop/build/test/mapred/local/localRunner/job_local_0001.xml:an attempt to override final parameter: hadoop.tmp.dir; Ignoring.2013-01-19 10:43:02,948 INFO mapreduce.Job (Job.java:submit(1222)) - The url to track the job: http://localhost:8080/2013-01-19 10:43:02,950 INFO mapreduce.Job (Job.java:monitorAndPrintJob(1267)) - Running job: job_local_00012013-01-19 10:43:02,951 INFO mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(320)) - OutputCommitter set in config null2013-01-19 10:43:02,986 INFO mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(338)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter2013-01-19 10:43:03,173 INFO mapred.LocalJobRunner (LocalJobRunner.java:run(386)) - Waiting for map tasks2013-01-19 10:43:03,173 INFO mapred.LocalJobRunner (LocalJobRunner.java:run(213)) - Starting task: attempt_local_0001_m_000000_02013-01-19 10:43:03,278 INFO mapred.Task (Task.java:initialize(565)) - Using ResourceCalculatorPlugin : org.apache.hadoop.yarn.util.LinuxResourceCalculatorPlugin@40be76c72013-01-19 10:43:03,955 INFO mapreduce.Job (Job.java:monitorAndPrintJob(1288)) - Job job_local_0001 running in uber mode : false2013-01-19 10:43:03,974 INFO mapreduce.Job (Job.java:monitorAndPrintJob(1295)) - map 0% reduce 0%2013-01-19 10:43:03,975 INFO mapred.MapTask (MapTask.java:setEquator(1130)) - (EQUATOR) 0 kvi 26214396(104857584)2013-01-19 10:43:03,979 INFO mapred.MapTask (MapTask.java:<init>(926)) - mapreduce.task.io.sort.mb: 1002013-01-19 10:43:03,979 INFO mapred.MapTask (MapTask.java:<init>(927)) - soft limit at 838860802013-01-19 10:43:03,979 INFO mapred.MapTask (MapTask.java:<init>(928)) - bufstart = 0; bufvoid = 1048576002013-01-19 10:43:03,979 INFO mapred.MapTask (MapTask.java:<init>(929)) - kvstart = 26214396; length = 65536002013-01-19 10:43:04,528 INFO mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(501)) - 2013-01-19 10:43:04,569 INFO mapred.MapTask (MapTask.java:flush(1392)) - Starting flush of map output2013-01-19 10:43:04,569 INFO mapred.MapTask (MapTask.java:flush(1411)) - Spilling map output2013-01-19 10:43:04,570 INFO mapred.MapTask (MapTask.java:flush(1412)) - bufstart = 0; bufend = 195; bufvoid = 1048576002013-01-19 10:43:04,570 INFO mapred.MapTask (MapTask.java:flush(1414)) - kvstart = 26214396(104857584); kvend = 26214336(104857344); length = 61/65536002013-01-19 10:43:04,729 INFO mapred.MapTask (MapTask.java:sortAndSpill(1600)) - Finished spill 02013-01-19 10:43:04,734 INFO mapred.Task (Task.java:done(979)) - Task:attempt_local_0001_m_000000_0 is done. And is in the process of committing2013-01-19 10:43:05,077 INFO mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(501)) - map2013-01-19 10:43:05,078 INFO mapred.Task (Task.java:sendDone(1099)) - Task 'attempt_local_0001_m_000000_0' done.2013-01-19 10:43:05,078 INFO mapred.LocalJobRunner (LocalJobRunner.java:run(238)) - Finishing task: attempt_local_0001_m_000000_02013-01-19 10:43:05,078 INFO mapred.LocalJobRunner (LocalJobRunner.java:run(394)) - Map task executor complete.2013-01-19 10:43:05,155 INFO mapred.Task (Task.java:initialize(565)) - Using ResourceCalculatorPlugin : org.apache.hadoop.yarn.util.LinuxResourceCalculatorPlugin@63f8247d2013-01-19 10:43:05,182 INFO mapred.Merger (Merger.java:merge(549)) - Merging 1 sorted segments2013-01-19 10:43:05,206 INFO mapred.Merger (Merger.java:merge(648)) - Down to the last merge-pass, with 1 segments left of total size: 143 bytes2013-01-19 10:43:05,206 INFO mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(501)) - 2013-01-19 10:43:05,487 WARN conf.Configuration (Configuration.java:warnOnceIfDeprecated(816)) - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords2013-01-19 10:43:05,789 INFO mapred.Task (Task.java:done(979)) - Task:attempt_local_0001_r_000000_0 is done. And is in the process of committing2013-01-19 10:43:05,792 INFO mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(501)) - 2013-01-19 10:43:05,792 INFO mapred.Task (Task.java:commit(1140)) - Task attempt_local_0001_r_000000_0 is allowed to commit now2013-01-19 10:43:05,840 INFO output.FileOutputCommitter (FileOutputCommitter.java:commitTask(432)) - Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://localhost:9000/output/_temporary/0/task_local_0001_r_0000002013-01-19 10:43:05,840 INFO mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(501)) - reduce > reduce2013-01-19 10:43:05,840 INFO mapred.Task (Task.java:sendDone(1099)) - Task 'attempt_local_0001_r_000000_0' done.2013-01-19 10:43:06,001 INFO mapreduce.Job (Job.java:monitorAndPrintJob(1295)) - map 100% reduce 100%2013-01-19 10:43:07,002 INFO mapreduce.Job (Job.java:monitorAndPrintJob(1306)) - Job job_local_0001 completed successfully2013-01-19 10:43:07,063 INFO mapreduce.Job (Job.java:monitorAndPrintJob(1313)) - Counters: 32File System CountersFILE: Number of bytes read=496FILE: Number of bytes written=315196FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=262HDFS: Number of bytes written=108HDFS: Number of read operations=15HDFS: Number of large read operations=0HDFS: Number of write operations=4Map-Reduce FrameworkMap input records=8Map output records=16Map output bytes=195Map output materialized bytes=158Input split bytes=104Combine input records=16Combine output records=11Reduce input groups=11Reduce shuffle bytes=0Reduce input records=11Reduce output records=11Spilled Records=22Shuffled Maps =0Failed Shuffles=0Merged Map outputs=0GC time elapsed (ms)=3CPU time spent (ms)=0Physical memory (bytes) snapshot=0Virtual memory (bytes) snapshot=0Total committed heap usage (bytes)=327155712File Input Format Counters Bytes Read=131File Output Format Counters Bytes Written=108
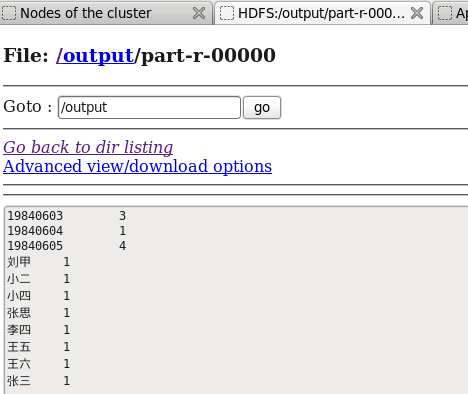
??? (5) 运行结果???