数据挖掘:Top 10 Algorithms in Data Mining(三)SVM
SVM(support vector machine)是一种基于分类间隔(margin)来训练的分类器,它是在1995年左右由Vapnik等人基于VC维而提出的高效分类器,其原理如下图最大化类间间隙。参考出处
SVM主要用于解决小样本和非线性分类问题。SVM解决非线性问题的办法为通过将原有的非线性可分的空间通过映射转换到高维线性可划分空间中,因此SVM会使得特征空间的维数升高。此处以φ(?) 来表示这种映射函数。则原模式Xk 在高维空间中变为yk=φ(Xk) 。有次可以看出原有的非线性问题变换为寻找合适的映射函数 φ(?)。映射函数的选择通常是根据问题的先验知识来确定,如果算法设计者的知识有限,则可以选择常用的多项式或者高斯函数。理论上可将源特征空间映射到任意高维的线性空间中。
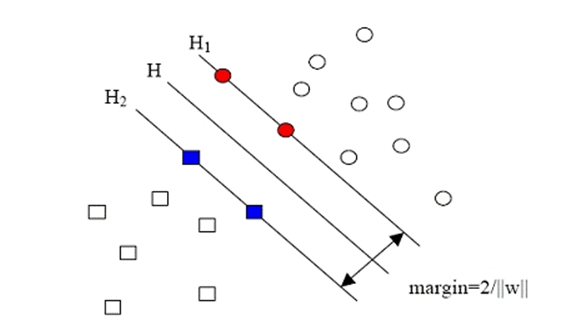
保证类别间的边界最大

SVM的训练使用无约束的拉格朗日法。根据原来的极小化目标,可以构造新的函数:
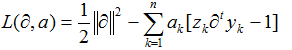
其中||?|| 为极小化目标,问题转换为寻找使得函数L()极小的权向量?和使其极大的拉格朗日待定因子ak>=0 。最后一项为使样本正确分类的目标。可以使用KT构造法将其转换为极大化形式:
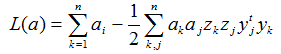
以及约束条件:
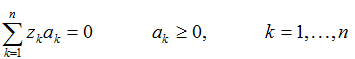
这些方程都可以通过二次规划来求解,除此还有其它经典解法。
支持向量机的重要优点为可以将分类复杂度与支持向量的个数联系到一起,而使其与映射后的空间的维数无关。这也使得SVM不易出现过拟合。
著名的SVM 工具有台湾大学陈Doctor Chen的libSVM 包。官方站点http://www.csie.ntu.edu.tw/~cjlin/libsvm/上面的介绍为:
LIBSVM : a simple and easy-to-use support vector machines tool for classification (C-SVC, nu-SVC), regression (epsilon-SVR, nu-SVR), and distribution estimation
该工具包主要由C++实现,还提供了对Python, R, Splus, MATLAB, Perl, Ruby语言的接口,可见接口支持非常丰富。其简单易用,是高校使用最多的一个第三方免费SVM包。Matlab 也有自己的SVM toolbox 但并没有libSVM强大,所以libSVM是高校教师指导新手和学生实验的不2选择(此处不是打广告)。下面给一个matlab使用libSVM的例子(需要将libSVM的相关的库文件和自己的.m放同个目录):
train_num = 5;
[x y z n] = size(YFL);
train_data = YFL(:,:,:,1:train_num);
test_data= YFL(:,:,:,train_num+1:n);
train_label = YLMask(:,:,:,1:train_num);
test_label = YLMask(:,:,:,train_num+1:n);
predict_label = zeros(x,y,z,n?train_num);
%training data
train_data_line = train_data(:,:,:,1);
train_label_line = train_label(:,:,:,1);
train_data_line = reshape(train_data_line,x*y*z,1);
train_label_line = reshape(train_label_line,x*y*z,1);
train_label_line = train_label_line(train_data_line>0);
train_data_line = train_data_line(train_data_line>0);
%train a model with this sample set
model_linear = svmtrain(train_label_line, train_data_line, '?t 0 wi 0.05');
save model_linear model_linear
for i=1:z
test_label_line = test_label(:,:,i,:);
test_data_line = test_data(:,:,i,:);
test_data_line = reshape(test_data_line,x*y*(n?train_num),1);
test_label_line = reshape(test_label_line,x*y*(n?train_num),1);
[predict_label_L, accuracy_L, dec_values_L] = svmpredict(test_label_line, test_data_line, model_linear);
unique(predict_label_L);
predict_label(:,:,i,:) = reshape(predict_label_L, x, y,1,5);
end
我这里YFL是一个MRI数据矩阵,维度为[128,256,256,10](即10个128*256*256的MRI图像). 在这里我用前5个MRI作训练数据,后面5个作为待分类数据。
更多资料参考:
http://www.support-vector-machines.org 该站点提供了很多SVM相关的资料。包括相关的书记,软件,在各种问题中的应用,以及相关的改进算法。
《Support Vector Machines for Pattern Classification》 Shigeo Abe, 2ed 不错的介绍SVM的书之一,有电子版。深入介绍了SVM的一些复杂使用方式及变形。
http://www.tnove.com