通过Map-Reduce实现Join系列之二
在本系列的第一篇中,介绍了几种在数据库应用中常见的Join算法,本文将会介绍两种使用Map-Reduce实现对两个数据集合进行Join的算法,其中的一种会用到第一篇中提到的哈希Join算法。这里将这两种方法分别命名为Map-Reduce Join和Map-Only Join。
1. Map-Reduce Join
这种Join方法,需要在hadoop上执行一个完整的Map-Reduce过程。下面的图说明了这个过程。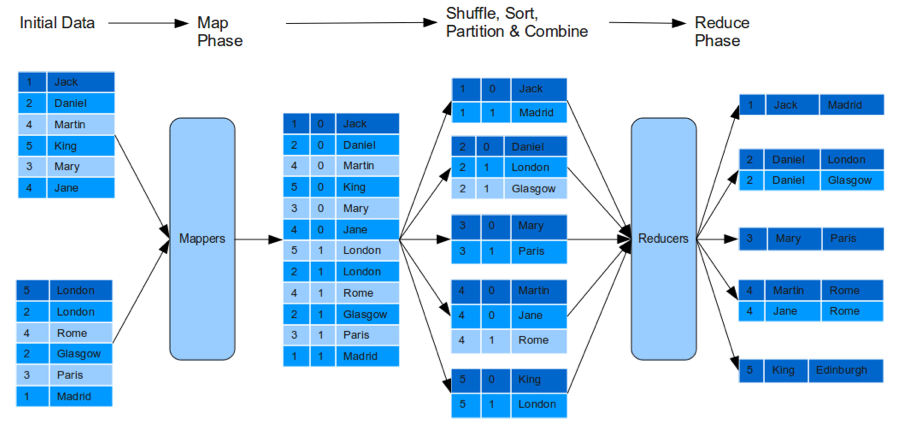 Map过程Map过程从需要进行合并的数据集合中读取数据,以Join条件中被用到的那一列的值为key,以整行数据为Value,将结果写到输出流中。为了标记Map集合中的每一行记录来自于哪个源数据集合,需要位Key添加一个标识。例如,有数据集合P(A,B)和Q(C,B),其中P集合有A、B两列,而Q集合有B、C两列,在根据B列对两个数据集合进行Join的情况下,P集合中的数据经过Map之后将以(B,tag,A+B)的形式输出,其中B列的值与tag的值共同组成Key,而整行记录将作为Value输出。对于Q来说也是如此,Q集合经过Map之后将以(B,tag,B+C)的形式输出。tag的作用tag的作用是为了区分数据来源,以便在Reduce阶段可以对不同来源的记录进行Join。但是,由于在Key中增加了一个tag,如果使用Hadoop默认的切分方法(Partitioner),会将B列值相同的记录分配给不同的Reducer,因此我们需要提供自定义的Partitioner,在选择Reducer的时候,不去考虑tag。
Map过程Map过程从需要进行合并的数据集合中读取数据,以Join条件中被用到的那一列的值为key,以整行数据为Value,将结果写到输出流中。为了标记Map集合中的每一行记录来自于哪个源数据集合,需要位Key添加一个标识。例如,有数据集合P(A,B)和Q(C,B),其中P集合有A、B两列,而Q集合有B、C两列,在根据B列对两个数据集合进行Join的情况下,P集合中的数据经过Map之后将以(B,tag,A+B)的形式输出,其中B列的值与tag的值共同组成Key,而整行记录将作为Value输出。对于Q来说也是如此,Q集合经过Map之后将以(B,tag,B+C)的形式输出。tag的作用tag的作用是为了区分数据来源,以便在Reduce阶段可以对不同来源的记录进行Join。但是,由于在Key中增加了一个tag,如果使用Hadoop默认的切分方法(Partitioner),会将B列值相同的记录分配给不同的Reducer,因此我们需要提供自定义的Partitioner,在选择Reducer的时候,不去考虑tag。
在数据丢给Reducer的reduce方法进行处理之前,Hadoop会根据key将数据进行聚合,把具有相同key的数据组合到一起去。由于在Key中增加了tag标识,如果使用Hadoop提供的默认分组方法,来自于不同集合的记录是无法被组合到一起去的,因此,我们同样需要提供自定义的分组排序算法,在分组的时候不去考虑tag标识,同时保证在同一个Key下面,来自于一个集合的所有记录都会排在另外一个集合的所有记录之前。Reduce过程在Reduce阶段,由于Map-Reduce方法保证具有相同Key的数据会被丢给同一个Reducer进行处理,因此P和Q中,在B列值相同的记录会被同一个Reducer进行处理,这个时候就可以执行Join操作了。所采用的算法如下:
void reduce(TextPair key , Iterator <TextPair> values , OutputCollector <Text , Text > output , Reporter reporter)throws IOException {ArrayList<Text> T1 = new ArrayList<Text>(); Text tag = key.getSecond();TextPair value = null; while(values.hasNext()){value = values.next(); if(value.getSecond().compareTo(tag)==0) {T1.add(value.getFirst()); } else {for(Text val : T1) {output.collect(key.getFirst(),new Text(val.toString() + "\t" + value.getFirst().toString()));} }} }